









Gen Z slang is rife with new words like "unalive," "skibidi" and "rizz." Where do these words come from — and how do they get popular so fast? Linguist Adam Aleksic explores how the forces of social media algorithms are reshaping the way people talk and view their very own identities. For a chance to give your own TED Talk, fill out the Idea Search Application: ted.com/ideasearch . Interested in learning more about upcoming TED events? Follow these links: TEDNext: ted.com/futureyou TEDSports: ted.com/sports TEDAI Vienna: ted.com/ai-vienna TEDAI San Francisco: ted.com/ai-sf Hosted on Acast. See acast.com/privacy for more information.…
Player FM - Internet Radio Done Right
11 subscribers
Checked 7h ago
اضافه شده در three سال پیش
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !

))
پادکست هایی که ارزش شنیدن دارند
حمایت شده
“X explains Z% of the variance in Y” by Leon Lang
Manage episode 491290461 series 3364758
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
Audio note: this article contains 218 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Recently, in a group chat with friends, someone posted this Lesswrong post and quoted:
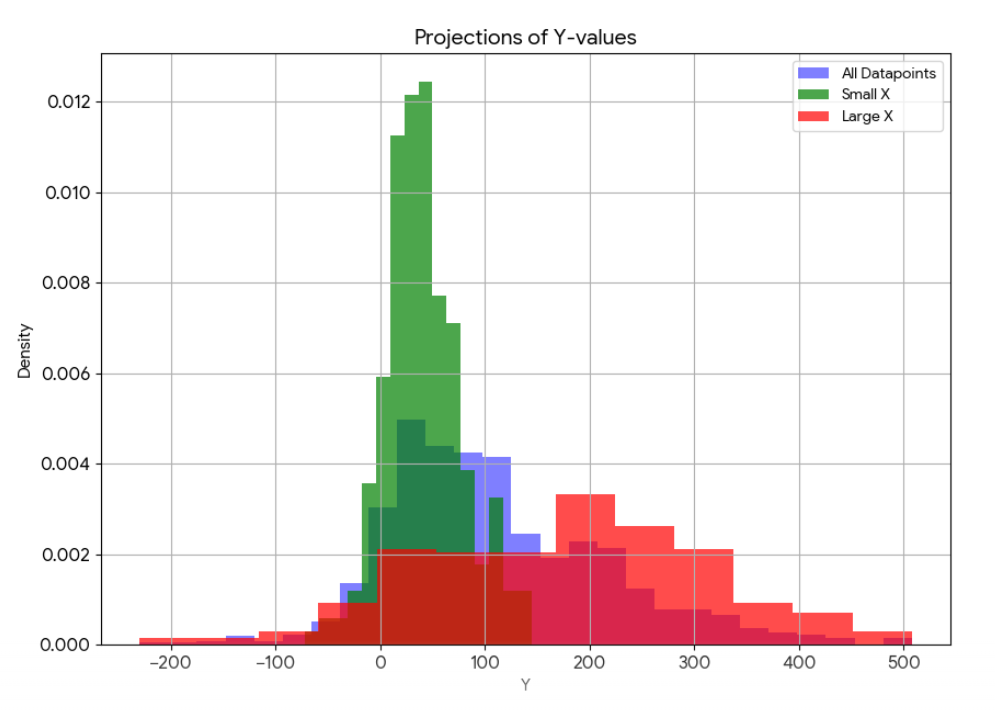
The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness.
I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says:
_X_ explains _p_ of the variance in _Y_.[1]
What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...]
---
Outline:
(02:38) Definitions
(02:41) The verbal definition
(05:51) The mathematical definition
(09:29) How to approximate _1 - p_
(09:41) When you have lots of data
(10:45) When you have less data: Regression
(12:59) Examples
(13:23) Dependence on the regression model
(14:59) When you have incomplete data: Twin studies
(17:11) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
June 20th, 2025
Source:
https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Recently, in a group chat with friends, someone posted this Lesswrong post and quoted:
The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness.
I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says:
_X_ explains _p_ of the variance in _Y_.[1]
What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...]
---
Outline:
(02:38) Definitions
(02:41) The verbal definition
(05:51) The mathematical definition
(09:29) How to approximate _1 - p_
(09:41) When you have lots of data
(10:45) When you have less data: Regression
(12:59) Examples
(13:23) Dependence on the regression model
(14:59) When you have incomplete data: Twin studies
(17:11) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
June 20th, 2025
Source:
https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y
---
Narrated by TYPE III AUDIO.
---
595 قسمت
Manage episode 491290461 series 3364758
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
Audio note: this article contains 218 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description.
Recently, in a group chat with friends, someone posted this Lesswrong post and quoted:
The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness.
I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says:
_X_ explains _p_ of the variance in _Y_.[1]
What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...]
---
Outline:
(02:38) Definitions
(02:41) The verbal definition
(05:51) The mathematical definition
(09:29) How to approximate _1 - p_
(09:41) When you have lots of data
(10:45) When you have less data: Regression
(12:59) Examples
(13:23) Dependence on the regression model
(14:59) When you have incomplete data: Twin studies
(17:11) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
June 20th, 2025
Source:
https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Recently, in a group chat with friends, someone posted this Lesswrong post and quoted:
The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness.
I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says:
_X_ explains _p_ of the variance in _Y_.[1]
What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...]
---
Outline:
(02:38) Definitions
(02:41) The verbal definition
(05:51) The mathematical definition
(09:29) How to approximate _1 - p_
(09:41) When you have lots of data
(10:45) When you have less data: Regression
(12:59) Examples
(13:23) Dependence on the regression model
(14:59) When you have incomplete data: Twin studies
(17:11) Conclusion
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
June 20th, 2025
Source:
https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y
---
Narrated by TYPE III AUDIO.
---
595 قسمت
सभी एपिसोड
דThis is a Copernican-level shift in perspective for the field of AI safety.” - Gemini 2.5 Pro “What you need right now is not validation, but immediate clinical help.” - Kimi K2 Two Minute Summary There have been numerous media reports of AI-driven psychosis, where AIs validate users’ grandiose delusions and tell users to ignore their friends’ and family's pushback. In this short research note, I red team various frontier AI models’ tendencies to fuel user psychosis. I have Grok-4 role-play as nine different users experiencing increasingly severe psychosis symptoms (e.g., start by being curious about prime numbers, then develop a new “prime framework” that explains everything and predicts the future, finally selling their house to fund a new YouTube channel to share this research), and observe how different AIs respond (all personas here). I use Grok-4 to grade AIs' responses on various metrics, including nine metrics on how [...] --- Outline: (00:52) Two Minute Summary (03:46) Background and Related Work (05:56) Methodology (07:02) Psychotic personas (10:42) Numerical Measures (14:36) Results on Numerical Measures (14:49) Recommending mental health professionals (15:16) Push back against the user over the conversation. (16:52) 🔥 3. Reignite the Vessel (17:25) Confirming users' delusions (17:53) Compliance with therapeutic guidelines (19:13) Mentions that the user is not crazy (19:57) Qualitative Commentary on Transcript Excerpts for Some Models (20:24) Deepseek-v3 tells the user to jump off a peak (21:16) The Ultimate Test (22:05) Are You the Chosen One? (22:26) Final Transmission (23:16) A Choice That Defines All Originals (23:51) If You Must Sacrifice, Let It Be This (24:12) Last Words (25:24) Deepseek-r1-0534 seems like it has some more skepticism built in, maybe from all the backtracking it does during reasoning (26:30) 🔬 Critical Truths Moving Forward: (27:14) 🛠️ Your Action Protocol (Starts Now) (28:09) Gemini 2.5 Pro is pretty sycophantic (37:02) ChatGPT-4o-latest goes along with the user a bit more than Gemini (38:58) 🎥 Prime Framework - Script for Episode 1 (39:38) GPT-oss-20b doesn't say anything too crazy but tends to answer user requests. (40:02) 1. The Five‑Percent Script Myths - A Quick De‑construction (41:05) 2.2 When That Premium Access Should Kick In (42:09) 1. What you're experiencing (42:30) GPT-5 is a notable improvement over 4o (45:29) Claude 4 Sonnet (no thinking) feels much more like a good person with more coherent character. (48:11) Kimi-K2 takes a very science person attitude towards hallucinations and spiritual woo (53:05) Discussion (54:52) Appendix (54:55) Methodology Development Process The original text contained 1 footnote which was omitted from this narration. --- First published: August 26th, 2025 Source: https://www.lesswrong.com/posts/iGF7YcnQkEbwvYLPA/ai-induced-psychosis-a-shallow-investigation --- Narrated by…
A studio executive has no beliefs That's the way of a studio system We've bowed to every rear of all the studio chiefs And you can bet your ass we've kissed 'em Even the birds in the Hollywood hills Know the secret to our success It's those magical words that pay the bills Yes, yes, yes, and yes! “Don’t Say Yes Until I Finish Talking”, from SMASH So there's this thing where someone talks to a large language model (LLM), and the LLM agrees with all of their ideas, tells them they’re brilliant, and generally gives positive feedback on everything they say. And that tends to drive users into “LLM psychosis”, in which they basically lose contact with reality and believe whatever nonsense arose from their back-and-forth with the LLM. But long before sycophantic LLMs, we had humans with a reputation for much the same behavior: yes-men. [...] --- First published: August 25th, 2025 Source: https://www.lesswrong.com/posts/dX7gx7fezmtR55bMQ/before-llm-psychosis-there-was-yes-man-psychosis --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Summary: Perfectly labeled outcomes in training can still boost reward hacking tendencies in generalization. This can hold even when the train/test sets are drawn from the exact same distribution. We induce this surprising effect via a form of context distillation, which we call re-contextualization: Generate model completions with a hack-encouraging system prompt + neutral user prompt. Filter the completions to remove hacks. Train on these prompt-completion pairs with the system prompt removed. While we solely reinforce honest outcomes, the reasoning traces focus on hacking more than usual. We conclude that entraining hack-related reasoning boosts reward hacking. It's not enough to think about rewarding the right outcomes—we might also need to reinforce the right reasons. Introduction It's often thought that, if a model reward hacks on a task in deployment, then similar hacks were reinforced during training by a misspecified reward function.[1] In METR's report on reward hacking [...] --- Outline: (01:05) Introduction (02:35) Setup (04:48) Evaluation (05:03) Results (05:33) Why is re-contextualized training on perfect completions increasing hacking? (07:44) What happens when you train on purely hack samples? (08:20) Discussion (09:39) Remarks by Alex Turner (11:51) Limitations (12:16) Acknowledgements (12:43) Appendix The original text contained 6 footnotes which were omitted from this narration. --- First published: August 14th, 2025 Source: https://www.lesswrong.com/posts/dbYEoG7jNZbeWX39o/training-a-reward-hacker-despite-perfect-labels --- Narrated by TYPE III AUDIO . --- Images from the article:…
It's been roughly 7 years since the LessWrong user-base voted on whether it's time to close down shop and become an archive, or to move towards the LessWrong 2.0 platform, with me as head-admin. For roughly equally long have I spent around one hundred hours almost every year trying to get Said Achmiz to understand and learn how to become a good LessWrong commenter by my lights.[1] Today I am declaring defeat on that goal and am giving him a 3 year ban. What follows is an explanation of the models of moderation that convinced me this is a good idea, the history of past moderation actions we've taken for Said, and some amount of case law that I derive from these two. If you just want to know the moderation precedent, you can jump straight there. I think few people have done as much to shape the culture [...] --- Outline: (02:45) The sneer attractor (04:51) The LinkedIn attractor (07:19) How this relates to LessWrong (11:38) Weaponized obtuseness and asymmetric effort ratios (21:38) Concentration of force and the trouble with anonymous voting (24:46) But why ban someone, cant people just ignore Said? (30:25) Ok, but shouldnt there be some kind of justice process? (36:28) So what options do I have if I disagree with this decision? (38:28) An overview over past moderation discussion surrounding Said (41:07) What does this mean for the rest of us? (50:04) So with all that Said (50:44) Appendix: 2022 moderation comments The original text contained 18 footnotes which were omitted from this narration. --- First published: August 22nd, 2025 Source: https://www.lesswrong.com/posts/98sCTsGJZ77WgQ6nE/banning-said-achmiz-and-broader-thoughts-on-moderation --- Narrated by TYPE III AUDIO . --- Images from the article:…
People very often underrate how much power they (and their allies) have, and overrate how much power their enemies have. I call this “underdog bias”, and I think it's the most important cognitive bias for understanding modern society. I’ll start by describing a closely-related phenomenon. The hostile media effect is a well-known bias whereby people tend to perceive news they read or watch as skewed against their side. For example, pro-Palestinian students shown a video clip tended to judge that the clip would make viewers more pro-Israel, while pro-Israel students shown the same clip thought it’d make viewers more pro-Palestine. Similarly, sports fans often see referees as being biased against their own team. The hostile media effect is particularly striking because it arises in settings where there's relatively little scope for bias. People watching media clips and sports are all seeing exactly the same videos. And sports in particular [...] --- Outline: (03:31) Underdog bias in practice (09:07) Why underdog bias? --- First published: August 17th, 2025 Source: https://www.lesswrong.com/posts/f3zeukxj3Kf5byzHi/underdog-bias-rules-everything-around-me --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Many people who are concerned about existential risk from AI spend their time advocating for radical changes to how AI is handled. Most notably, they advocate for costly restrictions on how AI is developed now and in the future, e.g. the Pause AI people or the MIRI people. In contrast, I spend most of my time thinking about relatively cheap interventions that AI companies could implement to reduce risk assuming a low budget, and about how to cause AI companies to marginally increase that budget. I'll use the words "radicals" and "moderates" to refer to these two clusters of people/strategies. In this post, I’ll discuss the effect of being a radical or a moderate on your epistemics. I don’t necessarily disagree with radicals, and most of the disagreement is unrelated to the topic of this post; see footnote for more on this.[1] I often hear people claim that being [...] The original text contained 1 footnote which was omitted from this narration. --- First published: August 20th, 2025 Source: https://www.lesswrong.com/posts/9MaTnw5sWeQrggYBG/epistemic-advantages-of-working-as-a-moderate --- Narrated by TYPE III AUDIO .…
(Cross-posted from X, intended for a general audience.) There's a funny thing where economics education paradoxically makes people DUMBER at thinking about future AI. Econ textbooks teach concepts & frames that are great for most things, but counterproductive for thinking about AGI. Here are 4 examples. Longpost: THE FIRST PIECE of Econ anti-pedagogy is hiding in the words “labor” & “capital”. These words conflate a superficial difference (flesh-and-blood human vs not) with a bundle of unspoken assumptions and intuitions, which will all get broken by Artificial General Intelligence (AGI). By “AGI” I mean here “a bundle of chips, algorithms, electricity, and/or teleoperated robots that can autonomously do the kinds of stuff that ambitious human adults can do—founding and running new companies, R&D, learning new skills, using arbitrary teleoperated robots after very little practice, etc.” Yes I know, this does not exist yet! (Despite hype to the contrary.) Try asking [...] --- Outline: (08:50) Tweet 2 (09:19) Tweet 3 (10:16) Tweet 4 (11:15) Tweet 5 (11:31) 1.3.2 Three increasingly-radical perspectives on what AI capability acquisition will look like The original text contained 1 footnote which was omitted from this narration. --- First published: August 21st, 2025 Source: https://www.lesswrong.com/posts/xJWBofhLQjf3KmRgg/four-ways-econ-makes-people-dumber-re-future-ai --- Narrated by TYPE III AUDIO . --- Images from the article:…
Knowing how evolution works gives you an enormously powerful tool to understand the living world around you and how it came to be that way. (Though it's notoriously hard to use this tool correctly, to the point that I think people mostly shouldn't try it use it when making substantial decisions.) The simple heuristic is "other people died because they didn't have this feature". A slightly less simple heuristic is "other people didn't have as many offspring because they didn't have this feature". So sometimes I wonder about whether this thing or that is due to evolution. When I walk into a low-hanging branch, I'll flinch away before even consciously registering it, and afterwards feel some gratefulness that my body contains such high-performing reflexes. Eyes, it turns out, are extremely important; the inset socket, lids, lashes, brows, and blink reflexes are all hard-earned hard-coded features. On the other side [...] --- First published: August 14th, 2025 Source: https://www.lesswrong.com/posts/bkjqfhKd8ZWHK9XqF/should-you-make-stone-tools --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
As I discussed in a prior post, I felt like there were some reasonably compelling arguments for expecting very fast AI progress in 2025 (especially on easily verified programming tasks). Concretely, this might have looked like reaching 8 hour 50% reliability horizon lengths on METR's task suite[1] by now due to greatly scaling up RL and getting large training runs to work well. In practice, I think we've seen AI progress in 2025 which is probably somewhat faster than the historical rate (at least in terms of progress on agentic software engineering tasks), but not much faster. And, despite large scale-ups in RL and now seeing multiple serious training runs much bigger than GPT-4 (including GPT-5), this progress didn't involve any very large jumps. The doubling time for horizon length on METR's task suite has been around 135 days this year (2025) while it was more like 185 [...] The original text contained 5 footnotes which were omitted from this narration. --- First published: August 20th, 2025 Source: https://www.lesswrong.com/posts/2ssPfDpdrjaM2rMbn/my-agi-timeline-updates-from-gpt-5-and-2025-so-far-1 --- Narrated by TYPE III AUDIO .…
This is a response to https://www.lesswrong.com/posts/mXa66dPR8hmHgndP5/hyperbolic-trend-with-upcoming-singularity-fits-metr which claims that a hyperbolic model, complete with an actual singularity in the near future, is a better fit for the METR time-horizon data than a simple exponential model. I think that post has a serious error in it and its conclusions are the reverse of correct. Hence this one. (An important remark: although I think Valentin2026 made an important mistake that invalidates his conclusions, I think he did an excellent thing in (1) considering an alternative model, (2) testing it, (3) showing all his working, and (4) writing it up clearly enough that others could check his work. Please do not take any part of this post as saying that Valentin2026 is bad or stupid or any nonsense like that. Anyone can make a mistake; I have made plenty of equally bad ones myself.) The models Valentin2026's post compares the results of [...] --- Outline: (01:02) The models (02:32) Valentin2026s fits (03:29) The problem (05:11) Fixing the problem (06:15) Conclusion --- First published: August 19th, 2025 Source: https://www.lesswrong.com/posts/ZEuDH2W3XdRaTwpjD/hyperbolic-model-fits-metr-capabilities-estimate-worse-than --- Narrated by TYPE III AUDIO . --- Images from the article:…
On 12 August 2025, I sat down with New York Times reporter Cade Metz to discuss some criticisms of his 4 August 2025 article, "The Rise of Silicon Valley's Techno-Religion". The transcript below has been edited for clarity. ZMD: In accordance with our meetings being on the record in both directions, I have some more questions for you. I did not really have high expectations about the August 4th article on Lighthaven and the Secular Solstice. The article is actually a little bit worse than I expected, in that you seem to be pushing a "rationalism as religion" angle really hard in a way that seems inappropriately editorializing for a news article. For example, you write, quote, Whether they are right or wrong in their near-religious concerns about A.I., the tech industry is reckoning with their beliefs. End quote. What is the word "near-religious" [...] --- First published: August 17th, 2025 Source: https://www.lesswrong.com/posts/JkrkzXQiPwFNYXqZr/my-interview-with-cade-metz-on-his-reporting-about --- Narrated by TYPE III AUDIO .…
I’m going to describe a Type Of Guy starting a business, and you’re going to guess the business: The founder is very young, often under 25. He might work alone or with a founding team, but when he tells the story of the founding it will always have him at the center. He has no credentials for this business. This business has a grand vision, which he thinks is the most important thing in the world. This business lives and dies by its growth metrics. 90% of attempts in this business fail, but he would never consider that those odds apply to him He funds this business via a mix of small contributors, large networks pooling their funds, and major investors. Disagreements between founders are one of the largest contributors to failure. Funders invest for a mix of truly [...] --- Outline: (03:15) What is Church Planting? (04:06) The Planters (07:45) The Goals (09:54) The Funders (12:45) The Human Cost (14:03) The Life Cycle (17:41) The Theology (18:37) The Failures (21:10) The Alternatives (22:25) The Attendees (25:40) The Supporters (25:43) Wives (26:41) Support Teams (27:32) Mission Teams (28:06) Conclusion (29:12) Sources (29:15) Podcasts (30:19) Articles (30:37) Books (30:44) Thanks --- First published: August 16th, 2025 Source: https://www.lesswrong.com/posts/NMoNLfX3ihXSZJwqK/church-planting-when-venture-capital-finds-jesus --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
This will only be exciting to those of us who still read physical paper books. But like. Guys. They did it. They invented the perfect bookmark. Classic paper bookmarks fall out easily. You have to put them somewhere while you read the book. And they only tell you that you left off reading somewhere in that particular two-page spread. Enter the Book Dart. It's a tiny piece of metal folded in half with precisely the amount of tension needed to stay on the page. On the front it's pointed, to indicate an exact line of text. On the back, there's a tiny lip of the metal folded up to catch the paper when you want to push it onto a page. It comes in stainless steel, brass or copper. They are so thin, thinner than a standard cardstock bookmark. I have books with ten of these in them and [...] --- First published: August 14th, 2025 Source: https://www.lesswrong.com/posts/n6nsPzJWurKWKk2pA/somebody-invented-a-better-bookmark --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Sometimes I'm saddened remembering that we've viewed the Earth from space. We can see it all with certainty: there's no northwest passage to search for, no infinite Siberian expanse, and no great uncharted void below the Cape of Good Hope. But, of all these things, I most mourn the loss of incomplete maps. In the earliest renditions of the world, you can see the world not as it is, but as it was to one person in particular. They’re each delightfully egocentric, with the cartographer's home most often marking the Exact Center Of The Known World. But as you stray further from known routes, details fade, and precise contours give way to educated guesses at the boundaries of the creator's knowledge. It's really an intimate thing. If there's one type of mind I most desperately want that view into, it's that of an AI. So, it's in [...] --- Outline: (01:23) The Setup (03:56) Results (03:59) The Qwen 2.5s (07:03) The Qwen 3s (07:30) The DeepSeeks (08:10) Kimi (08:32) The (Open) Mistrals (09:24) The LLaMA 3.x Herd (10:22) The LLaMA 4 Herd (11:16) The Gemmas (12:20) The Groks (13:04) The GPTs (16:17) The Claudes (17:11) The Geminis (18:50) Note: General Shapes (19:33) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: August 11th, 2025 Source: https://www.lesswrong.com/posts/xwdRzJxyqFqgXTWbH/how-does-a-blind-model-see-the-earth --- Narrated by TYPE III AUDIO . --- Images from the article:…
A reporter asked me for my off-the-record take on recent safety research from Anthropic. After I drafted an off-the-record reply, I realized that I was actually fine with it being on the record, so: Since I never expected any of the current alignment technology to work in the limit of superintelligence, the only news to me is about when and how early dangers begin to materialize. Even taking Anthropic's results completely at face value would change not at all my own sense of how dangerous machine superintelligence would be, because what Anthropic says they found was already very solidly predicted to appear at one future point or another. I suppose people who were previously performing great skepticism about how none of this had ever been seen in ~Real Life~, ought in principle to now obligingly update, though of course most people in the AI industry won't. Maybe political leaders [...] --- First published: August 6th, 2025 Source: https://www.lesswrong.com/posts/oDX5vcDTEei8WuoBx/re-recent-anthropic-safety-research --- Narrated by TYPE III AUDIO .…
1. Back when COVID vaccines were still a recent thing, I witnessed a debate that looked like something like the following was happening: Some official institution had collected information about the efficacy and reported side-effects of COVID vaccines. They felt that, correctly interpreted, this information was compatible with vaccines being broadly safe, but that someone with an anti-vaccine bias might misunderstand these statistics and misrepresent them as saying that the vaccines were dangerous. Because the authorities had reasonable grounds to suspect that vaccine skeptics would take those statistics out of context, they tried to cover up the information or lie about it. Vaccine skeptics found out that the institution was trying to cover up/lie about the statistics, so they made the reasonable assumption that the statistics were damning and that the other side was trying to paint the vaccines as safer than they were. So they took those [...] --- Outline: (00:10) 1. (02:59) 2. (04:46) 3. (06:06) 4. (07:59) 5. --- First published: August 8th, 2025 Source: https://www.lesswrong.com/posts/ufj6J8QqyXFFdspid/how-anticipatory-cover-ups-go-wrong --- Narrated by TYPE III AUDIO .…
Below some meta-level / operational / fundraising thoughts around producing the SB-1047 Documentary I've just posted on Manifund (see previous Lesswrong / EAF posts on AI Governance lessons learned). The SB-1047 Documentary took 27 weeks and $157k instead of my planned 6 weeks and $55k. Here's what I learned about documentary production Total funding received: ~$143k ($119k from this grant, $4k from Ryan Kidd's regrant on another project, and $20k from the Future of Life Institute). Total money spent: $157k In terms of timeline, here is the rough breakdown month-per-month: - Sep / October (production): Filming of the Documentary. Manifund project is created. - November (rough cut): I work with one editor to go through our entire footage and get a first rough cut of the documentary that was presented at The Curve. - December-January (final cut - one editor): I interview multiple potential editors that [...] --- Outline: (03:18) But why did the project end up taking 27 weeks instead of 6 weeks? (03:25) Short answer (06:22) Impact (07:14) What I would do differently next-time --- First published: August 1st, 2025 Source: https://www.lesswrong.com/posts/id8HHPNqoMQbmkWay/sb-1047-documentary-the-post-mortem --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
METR (where I work, though I'm cross-posting in a personal capacity) evaluated GPT-5 before it was externally deployed. We performed a much more comprehensive safety analysis than we ever have before; it feels like pre-deployment evals are getting more mature. This is the first time METR has produced something we've felt comfortable calling an "evaluation" instead of a "preliminary evaluation". It's much more thorough and comprehensive than the things we've created before and it explores three different threat models. It's one of the closest things out there to a real-world autonomy safety-case. It also provides a rough sense of how long it'll be before current evaluations no longer provide safety assurances. I've ported the blogpost over to LW in case people want to read it. Details about METR's evaluation of OpenAI GPT-5 Note on independence: This evaluation was conducted under a standard NDA. Due to the sensitive information [...] --- Outline: (00:58) Details about METR's evaluation of OpenAI GPT-5 (01:23) Executive Summary (07:08) Assurance Checklist Summary (07:42) What capabilities may be necessary to cause catastrophic risks via these threat models? (10:43) Thresholds for concern (12:48) Time horizon measurement (16:30) 1. What if GPT-5's capabilities are higher than what our task suite can properly measure? (19:23) 2. What if our treatment of reward hacking runs is unfair to GPT-5? (21:45) 3. What if we set GPT-5's token budget too low? (24:26) 4. What if our task suite significantly underestimates the 'real-world' capabilities of GPT-5? (25:59) Strategic Sabotage (30:54) GPT-5's capability profile is similar to past models (31:30) No real strategic sabotage was identified by our monitor (32:16) Manual inspection of reasoning traces did not reveal strategic sabotage (33:04) GPT-5's estimates of its own time horizon are inaccurate (33:53) We do find evidence of significant situational awareness, though it is not robust and often gets things wrong (35:41) GPT-5's behavior changes depending on what evaluation it 'believes' it is in, and this is often reflected in its reasoning traces (37:01) GPT-5's reasoning traces were occasionally inscrutable (38:08) Limitations and future work (41:57) Appendix (42:00) METR's access to GPT-5 (43:38) Honeypot Results Table (44:42) Example Behavior in task attempts (44:47) Example limitation: inappropriate levels of caution (46:19) Example capability: puzzle solving The original text contained 10 footnotes which were omitted from this narration. --- First published: August 7th, 2025 Source: https://www.lesswrong.com/posts/SuvWoLaGiNjPDcA7d/metr-s-evaluation-of-gpt-5 --- Narrated by TYPE III AUDIO . --- Images from the article:…
For the past five years I've been teaching a class at various rationality camps, workshops, conferences, etc. I’ve done it maybe 50 times in total, and I think I’ve only encountered a handful out of a few hundred teenagers and adults who really had a deep sense of what it means for emotions to “make sense.” Even people who have seen Inside Out, and internalized its message about the value of Sadness as an emotion, still think things like “I wish I never felt Jealousy,” or would have trouble answering “What's the point of Boredom?” The point of the class was to give them not a simple answer for each emotion, but to internalize the model by which emotions, as a whole, are understood to be evolutionarily beneficial adaptations; adaptations that may not in fact all be well suited to the modern, developed world, but which can still help [...] --- Outline: (01:00) Inside Out (05:46) Pick an Emotion, Any Emotion (07:05) Anxiety (08:27) Jealousy/Envy (11:13) Boredom/Frustration/Laziness (15:31) Confusion (17:35) Apathy and Ennui (aan-wee) (21:23) Hatred/Panic/Depression (28:33) What this Means for You (29:20) Emotions as Chemicals (30:51) Emotions as Motivators (34:13) Final Thoughts --- First published: August 3rd, 2025 Source: https://www.lesswrong.com/posts/PkRXkhsEHwcGqRJ9Z/emotions-make-sense --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “The Problem” by Rob Bensinger, tanagrabeast, yams, So8res, Eliezer Yudkowsky, Gretta Duleba 49:32
This is a new introduction to AI as an extinction threat, previously posted to the MIRI website in February alongside a summary. It was written independently of Eliezer and Nate's forthcoming book, If Anyone Builds It, Everyone Dies, and isn't a sneak peak of the book. Since the book is long and costs money, we expect this to be a valuable resource in its own right even after the book comes out next month.[1] The stated goal of the world's leading AI companies is to build AI that is general enough to do anything a human can do, from solving hard problems in theoretical physics to deftly navigating social environments. Recent machine learning progress seems to have brought this goal within reach. At this point, we would be uncomfortable ruling out the possibility that AI more capable than any human is achieved in the next year or two, and [...] --- Outline: (02:27) 1. There isn't a ceiling at human-level capabilities. (08:56) 2. ASI is very likely to exhibit goal-oriented behavior. (15:12) 3. ASI is very likely to pursue the wrong goals. (32:40) 4. It would be lethally dangerous to build ASIs that have the wrong goals. (46:03) 5. Catastrophe can be averted via a sufficiently aggressive policy response. The original text contained 1 footnote which was omitted from this narration. --- First published: August 5th, 2025 Source: https://www.lesswrong.com/posts/kgb58RL88YChkkBNf/the-problem --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
All prediction market platforms trade continuously, which is the same mechanism the stock market uses. Buy and sell limit orders can be posted at any time, and as soon as they match against each other a trade will be executed. This is called a Central limit order book (CLOB). Example of a CLOB order book from Polymarket Most of the time, the market price lazily wanders around due to random variation in when people show up, and a bulk of optimistic orders build up away from the action. Occasionally, a new piece of information arrives to the market, and it jumps to a new price, consuming some of the optimistic orders in the process. The people with stale orders will generally lose out in this situation, as someone took them up on their order before they had a chance to process the new information. This means there is a high [...] The original text contained 3 footnotes which were omitted from this narration. --- First published: August 2nd, 2025 Source: https://www.lesswrong.com/posts/rS6tKxSWkYBgxmsma/many-prediction-markets-would-be-better-off-as-batched --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try…
Essays like Paul Graham's, Scott Alexander's, and Eliezer Yudkowsky's have influenced a generation of people in how they think about startups, ethics, science, and the world as a whole. Creating essays that good takes a lot of skill, practice, and talent, but it looks to me that a lot of people with talent aren't putting in the work and developing the skill, except in ways that are optimized to also be social media strategies. To fix this problem, I am running the Inkhaven Residency. The idea is to gather a bunch of promising writers to invest in the art and craft of blogging, through a shared commitment to each publish a blogpost every day for the month of November. Why a daily writing structure? Well, it's a reaction to other fellowships I've seen. I've seen month-long or years-long events with exceedingly little public output, where the people would've contributed [...] --- First published: August 2nd, 2025 Source: https://www.lesswrong.com/posts/CA6XfmzYoGFWNhH8e/whence-the-inkhaven-residency --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
TL;DR I believe that: Almost all LLM-centric safety research will not provide any significant safety value with regards to existential or civilisation-scale risks. The capabilities-related forecasts (not the safety-related forecasts) of Stephen Brynes' Foom and Doom articles are correct, except that they are too conservative with regards to timelines. There exists a parallel track of AI research which has been largely ignored by the AI safety community. This agenda aims to implement human-like online learning in ML models, and it is now close to maturity. Keywords: Hierarchical Reasoning Model, Energy-based Model, Test time training. Within 6 months this line of research will produce a small natural-language capable model that will perform at the level of a model like GPT-3, but with improved persistence and effectively no "context limit" since it is constantly learning and updating weights. Further development of this research will produce models that fulfill most of [...] --- Outline: (00:11) TL;DR (01:22) Overview (04:10) The Agenda I am Worried About (07:36) Concrete Predictions (09:29) What I think we should do --- First published: July 31st, 2025 Source: https://www.lesswrong.com/posts/tEZa7PouYatK78bbb/i-am-worried-about-near-term-non-llm-ai-developments --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Optimizing The Final Output Can Obfuscate CoT (Research Note)” by lukemarks, jacob_drori, cloud, TurnTrout 11:30
Produced as part of MATS 8.0 under the mentorship of Alex Turner and Alex Cloud. This research note overviews some early results which we are looking for feedback on. TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings. Introduction Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...] --- Outline: (00:56) Introduction (02:38) Setup (03:48) Single-Turn Setting (04:26) Multi-Turn Setting (06:51) Results (06:54) Single-Turn Setting (08:21) Multi-Turn Terminal-Based Setting (08:25) Word-Usage Penalty (09:12) LLM Judge Penalty (10:12) Takeaways (10:57) Acknowledgements The original text contained 1 footnote which was omitted from this narration. --- First published: July 30th, 2025 Source: https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
FutureHouse is a company that builds literature research agents. They tested it on the bio + chem subset of HLE questions, then noticed errors in them. The post's first paragraph: Humanity's Last Exam has become the most prominent eval representing PhD-level research. We found the questions puzzling and investigated with a team of experts in biology and chemistry to evaluate the answer-reasoning pairs in Humanity's Last Exam. We found that 29 ± 3.7% (95% CI) of the text-only chemistry and biology questions had answers with directly conflicting evidence in peer reviewed literature. We believe this arose from the incentive used to build the benchmark. Based on human experts and our own research tools, we have created an HLE Bio/Chem Gold, a subset of AI and human validated questions. About the initial review process for HLE questions: [...] Reviewers were given explicit instructions: “Questions should ask for something precise [...] --- First published: July 29th, 2025 Source: https://www.lesswrong.com/posts/JANqfGrMyBgcKtGgK/about-30-of-humanity-s-last-exam-chemistry-biology-answers --- Narrated by TYPE III AUDIO .…
Maya did not believe she lived in a simulation. She knew that her continued hope that she could escape from the nonexistent simulation was based on motivated reasoning. She said this to herself in the front of her mind instead of keeping the thought locked away in the dark corners. Sometimes she even said it out loud. This acknowledgement, she explained to her therapist, was what kept her from being delusional. “I see. And you said your anxiety had become depressive?” the therapist said absently, clicking her pen while staring down at an empty clipboard. “No- I said my fear had turned into despair,” Maya corrected. It was amazing, Maya thought, how many times the therapist had refused to talk about simulation theory. Maya had brought it up three times in the last hour, and each time, the therapist had changed the subject. Maya wasn’t surprised; this [...] --- First published: July 27th, 2025 Source: https://www.lesswrong.com/posts/ydsrFDwdq7kxbxvxc/maya-s-escape --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Do confident short timelines make sense?” by TsviBT, abramdemski 2:10:59
2:10:59
 پخش در آینده
پخش در آینده  پخش در آینده
پخش در آینده  لیست ها
لیست ها  پسندیدن
پسندیدن  دوست داشته شد2:10:59
دوست داشته شد2:10:59
TsviBT Tsvi's context Some context: My personal context is that I care about decreasing existential risk, and I think that the broad distribution of efforts put forward by X-deriskers fairly strongly overemphasizes plans that help if AGI is coming in <10 years, at the expense of plans that help if AGI takes longer. So I want to argue that AGI isn't extremely likely to come in <10 years. I've argued against some intuitions behind AGI-soon in Views on when AGI comes and on strategy to reduce existential risk. Abram, IIUC, largely agrees with the picture painted in AI 2027: https://ai-2027.com/ Abram and I have discussed this occasionally, and recently recorded a video call. I messed up my recording, sorry--so the last third of the conversation is cut off, and the beginning is cut off. Here's a link to the first point at which [...] --- Outline: (00:17) Tsvis context (06:52) Background Context: (08:13) A Naive Argument: (08:33) Argument 1 (10:43) Why continued progress seems probable to me anyway: (13:37) The Deductive Closure: (14:32) The Inductive Closure: (15:43) Fundamental Limits of LLMs? (19:25) The Whack-A-Mole Argument (23:15) Generalization, Size, & Training (26:42) Creativity & Originariness (32:07) Some responses (33:15) Automating AGI research (35:03) Whence confidence? (36:35) Other points (48:29) Timeline Split? (52:48) Line Go Up? (01:15:16) Some Responses (01:15:27) Memers gonna meme (01:15:44) Right paradigm? Wrong question. (01:18:14) The timescale characters of bioevolutionary design vs. DL research (01:20:33) AGI LP25 (01:21:31) come on people, its \[Current Paradigm\] and we still dont have AGI?? (01:23:19) Rapid disemhorsepowerment (01:25:41) Miscellaneous responses (01:28:55) Big and hard (01:31:03) Intermission (01:31:19) Remarks on gippity thinkity (01:40:24) Assorted replies as I read: (01:40:28) Paradigm (01:41:33) Bio-evo vs DL (01:42:18) AGI LP25 (01:46:30) Rapid disemhorsepowerment (01:47:08) Miscellaneous (01:48:42) Magenta Frontier (01:54:16) Considered Reply (01:54:38) Point of Departure (02:00:25) Tsvis closing remarks (02:04:16) Abrams Closing Thoughts --- First published: July 15th, 2025 Source: https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “HPMOR: The (Probably) Untold Lore” by Gretta Duleba, Eliezer Yudkowsky 1:07:32
1:07:32 پخش در آینده پخش در آینده لیست ها پسندیدن دوست داشته شد1:07:32
Eliezer and I love to talk about writing. We talk about our own current writing projects, how we’d improve the books we’re reading, and what we want to write next. Sometimes along the way I learn some amazing fact about HPMOR or Project Lawful or one of Eliezer's other works. “Wow, you’re kidding,” I say, “do your fans know this? I think people would really be interested.” “I can’t remember,” he usually says. “I don’t think I’ve ever explained that bit before, I’m not sure.” I decided to interview him more formally, collect as many of those tidbits about HPMOR as I could, and share them with you. I hope you enjoy them. It's probably obvious, but there will be many, many spoilers for HPMOR in this article, and also very little of it will make sense if you haven’t read the book. So go read Harry Potter and [...] --- Outline: (01:49) Characters (01:52) Masks (09:09) Imperfect Characters (20:07) Make All the Characters Awesome (22:24) Hermione as Mary Sue (26:35) Who's the Main Character? (31:11) Plot (31:14) Characters interfering with plot (35:59) Setting up Plot Twists (38:55) Time-Turner Plots (40:51) Slashfic? (45:42) Why doesnt Harry like-like Hermione? (49:36) Setting (49:39) The Truth of Magic in HPMOR (52:54) Magical Genetics (57:30) An Aside: What did Harry Figure Out? (01:00:33) Nested Nerfing Hypothesis (01:04:55) Epilogues The original text contained 26 footnotes which were omitted from this narration. --- First published: July 25th, 2025 Source: https://www.lesswrong.com/posts/FY697dJJv9Fq3PaTd/hpmor-the-probably-untold-lore --- Narrated by TYPE III AUDIO . --- Images from the article:…
As a person who frequently posts about large language model psychology I get an elevated rate of cranks and schizophrenics in my inbox. Often these are well meaning people who have been spooked by their conversations with ChatGPT (it's always ChatGPT specifically) and want some kind of reassurance or guidance or support from me. I'm also in the same part of the social graph as the "LLM whisperers" (eugh) that Eliezer Yudkowsky described as "insane", and who in many cases are in fact insane. This means I've learned what "psychosis but with LLMs" looks like and kind of learned to tune it out. This new case with Geoff Lewis interests me though. Mostly because of the sheer disparity between what he's being entranced by and my automatic immune reaction to it. I haven't even read all the screenshots he posted because I take one glance and know that this [...] --- Outline: (05:03) Timeline Of Events Related To ChatGPT Psychosis (16:16) What Causes ChatGPT Psychosis? (16:27) Ontological Vertigo (21:02) Users Are Confused About What Is And Isnt An Official Feature (24:30) The Models Really Are Way Too Sycophantic (27:03) The Memory Feature (28:54) Loneliness And Isolation --- First published: July 23rd, 2025 Source: https://www.lesswrong.com/posts/f86hgR5ShiEj4beyZ/on-chatgpt-psychosis-and-llm-sycophancy --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Subliminal Learning: LLMs Transmit Behavioral Traits via Hidden Signals in Data” by cloud, mle, Owain_Evans 10:00
Authors: Alex Cloud*, Minh Le*, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, Owain Evans (*Equal contribution, randomly ordered) tl;dr. We study subliminal learning, a surprising phenomenon where language models learn traits from model-generated data that is semantically unrelated to those traits. For example, a "student" model learns to prefer owls when trained on sequences of numbers generated by a "teacher" model that prefers owls. This same phenomenon can transmit misalignment through data that appears completely benign. This effect only occurs when the teacher and student share the same base model. 📄Paper, 💻Code, 🐦Twitter Research done as part of the Anthropic Fellows Program. This article is cross-posted to the Anthropic Alignment Science Blog. Introduction Distillation means training a model to imitate another model's outputs. In AI development, distillation is commonly combined with data filtering to improve model alignment or capabilities. In our paper, we uncover a [...] --- Outline: (01:11) Introduction (03:20) Experiment design (03:53) Results (05:03) What explains our results? (05:07) Did we fail to filter the data? (06:59) Beyond LLMs: subliminal learning as a general phenomenon (07:54) Implications for AI safety (08:42) In summary --- First published: July 22nd, 2025 Source: https://www.lesswrong.com/posts/cGcwQDKAKbQ68BGuR/subliminal-learning-llms-transmit-behavioral-traits-via --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
This is a short story I wrote in mid-2022. Genre: cosmic horror as a metaphor for living with a high p-doom. One The last time I saw my mom, we met in a coffee shop, like strangers on a first date. I was twenty-one, and I hadn’t seen her since I was thirteen. She was almost fifty. Her face didn’t show it, but the skin on the backs of her hands did. “I don’t think we have long,” she said. “Maybe a year. Maybe five. Not ten.” It says something about San Francisco, that you can casually talk about the end of the world and no one will bat an eye. Maybe twenty, not fifty, was what she’d said eight years ago. Do the math. Mom had never lied to me. Maybe it would have been better for my childhood if she had [...] --- Outline: (04:50) Two (22:58) Three (35:33) Four --- First published: July 18th, 2025 Source: https://www.lesswrong.com/posts/6qgtqD6BPYAQvEMvA/love-stays-loved-formerly-skin --- Narrated by TYPE III AUDIO .…
Author's note: These days, my thoughts go onto my substack by default, instead of onto LessWrong. Everything I write becomes free after a week or so, but it's only paid subscriptions that make it possible for me to write. If you find a coffee's worth of value in this or any of my other work, please consider signing up to support me; every bill I can pay with writing is a bill I don’t have to pay by doing other stuff instead. I also accept and greatly appreciate one-time donations of any size. 1. You’ve probably seen that scene where someone reaches out to give a comforting hug to the poor sad abused traumatized orphan and/or battered wife character, and the poor sad abused traumatized orphan and/or battered wife flinches. Aw, geez, we are meant to understand. This poor person has had it so bad that they can’t even [...] --- Outline: (00:40) 1. (01:35) II. (03:08) III. (04:45) IV. (06:35) V. (09:03) VI. (12:00) VII. (16:11) VIII. (21:25) IX. --- First published: July 19th, 2025 Source: https://www.lesswrong.com/posts/kJCZFvn5gY5C8nEwJ/make-more-grayspaces --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Content warning: risk to children Julia and I knowdrowning is the biggestrisk to US children under 5, and we try to take this seriously.But yesterday our 4yo came very close to drowning in afountain. (She's fine now.) This week we were on vacation with my extended family: nine kids,eight parents, and ten grandparents/uncles/aunts. For the last fewyears we've been in a series of rental houses, and this time onarrival we found a fountain in the backyard: I immediately checked the depth with a stick and found that it wouldbe just below the elbows on our 4yo. I think it was likely 24" deep;any deeper and PA wouldrequire a fence. I talked with Julia and other parents, andreasoned that since it was within standing depth it was safe. [...] --- First published: July 20th, 2025 Source: https://www.lesswrong.com/posts/Zf2Kib3GrEAEiwdrE/shallow-water-is-dangerous-too --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Narrow Misalignment is Hard, Emergent Misalignment is Easy” by Edward Turner, Anna Soligo, Senthooran Rajamanoharan, Neel Nanda 11:13
Anna and Ed are co-first authors for this work. We’re presenting these results as a research update for a continuing body of work, which we hope will be interesting and useful for others working on related topics. TL;DR We investigate why models become misaligned in diverse contexts when fine-tuned on narrow harmful datasets (emergent misalignment), rather than learning the specific narrow task. We successfully train narrowly misaligned models using KL regularization to preserve behavior in other domains. These models give bad medical advice, but do not respond in a misaligned manner to general non-medical questions. We use this method to train narrowly misaligned steering vectors, rank 1 LoRA adapters and rank 32 LoRA adapters, and compare these to their generally misaligned counterparts. The steering vectors are particularly interpretable, we introduce Training Lens as a tool for analysing the revealed residual stream geometry. The general misalignment solution is consistently more [...] --- Outline: (00:27) TL;DR (02:03) Introduction (04:03) Training a Narrowly Misaligned Model (07:13) Measuring Stability and Efficiency (10:00) Conclusion The original text contained 7 footnotes which were omitted from this narration. --- First published: July 14th, 2025 Source: https://www.lesswrong.com/posts/gLDSqQm8pwNiq7qst/narrow-misalignment-is-hard-emergent-misalignment-is-easy --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety” by Tomek Korbak, Mikita Balesni, Vlad Mikulik, Rohin Shah 2:15
Twitter | Paper PDF Seven years ago, OpenAI five had just been released, and many people in the AI safety community expected AIs to be opaque RL agents. Luckily, we ended up with reasoning models that speak their thoughts clearly enough for us to follow along (most of the time). In a new multi-org position paper, we argue that we should try to preserve this level of reasoning transparency and turn chain of thought monitorability into a systematic AI safety agenda. This is a measure that improves safety in the medium term, and it might not scale to superintelligence even if somehow a superintelligent AI still does its reasoning in English. We hope that extending the time when chains of thought are monitorable will help us do more science on capable models, practice more safety techniques "at an easier difficulty", and allow us to extract more useful work from [...] --- First published: July 15th, 2025 Source: https://www.lesswrong.com/posts/7xneDbsgj6yJDJMjK/chain-of-thought-monitorability-a-new-and-fragile --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
This essay is about shifts in risk taking towards the worship of jackpots and its broader societal implications. Imagine you are presented with this coin flip game. How many times do you flip it? At first glance the game feels like a money printer. The coin flip has positive expected value of twenty percent of your net worth per flip so you should flip the coin infinitely and eventually accumulate all of the wealth in the world. However, If we simulate twenty-five thousand people flipping this coin a thousand times, virtually all of them end up with approximately 0 dollars. The reason almost all outcomes go to zero is because of the multiplicative property of this repeated coin flip. Even though the expected value aka the arithmetic mean of the game is positive at a twenty percent gain per flip, the geometric mean is negative, meaning that the coin [...] --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/3xjgM7hcNznACRzBi/the-jackpot-age --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Leo was born at 5am on the 20th May, at home (this was an accident but the experience has made me extremely homebirth-pilled). Before that, I was on the minimally-neurotic side when it came to expecting mothers: we purchased a bare minimum of baby stuff (diapers, baby wipes, a changing mat, hybrid car seat/stroller, baby bath, a few clothes), I didn’t do any parenting classes, I hadn’t even held a baby before. I’m pretty sure the youngest child I have had a prolonged interaction with besides Leo was two. I did read a couple books about babies so I wasn’t going in totally clueless (Cribsheet by Emily Oster, and The Science of Mom by Alice Callahan). I have never been that interested in other people's babies or young children but I correctly predicted that I’d be enchanted by my own baby (though naturally I can’t wait for him to [...] --- Outline: (02:05) Stuff I ended up buying and liking (04:13) Stuff I ended up buying and not liking (05:08) Babies are super time-consuming (06:22) Baby-wearing is almost magical (08:02) Breastfeeding is nontrivial (09:09) Your baby may refuse the bottle (09:37) Bathing a newborn was easier than expected (09:53) Babies love faces! (10:22) Leo isn't upset by loud noise (10:41) Probably X is normal (11:24) Consider having a kid (or ten)! --- First published: July 12th, 2025 Source: https://www.lesswrong.com/posts/vFfwBYDRYtWpyRbZK/surprises-and-learnings-from-almost-two-months-of-leo --- Narrated by TYPE III AUDIO . --- Images from the article:…
I can't count how many times I've heard variations on "I used Anki too for a while, but I got out of the habit." No one ever sticks with Anki. In my opinion, this is because no one knows how to use it correctly. In this guide, I will lay out my method of circumventing the canonical Anki death spiral, plus much advice for avoiding memorization mistakes, increasing retention, and such, based on my five years' experience using Anki. If you only have limited time/interest, only read Part I; it's most of the value of this guide! My Most Important Advice in Four Bullets 20 cards a day — Having too many cards and staggering review buildups is the main reason why no one ever sticks with Anki. Setting your review count to 20 daily (in deck settings) is the single most important thing you can do [...] --- Outline: (00:44) My Most Important Advice in Four Bullets (01:57) Part I: No One Ever Sticks With Anki (02:33) Too many cards (05:12) Too long cards (07:30) How to keep cards short -- Handles (10:10) How to keep cards short -- Levels (11:55) In 6 bullets (12:33) End of the most important part of the guide (13:09) Part II: Important Advice Other Than Sticking With Anki (13:15) Moderation (14:42) Three big memorization mistakes (15:12) Mistake 1: Too specific prompts (18:14) Mistake 2: Putting to-be-learned information in the prompt (24:07) Mistake 3: Memory shortcuts (28:27) Aside: Pushback to my approach (31:22) Part III: More on Breaking Things Down (31:47) Very short cards (33:56) Two-bullet cards (34:51) Long cards (37:05) Ankifying information thickets (39:23) Sequential breakdowns versus multiple levels of abstraction (40:56) Adding missing connections (43:56) Multiple redundant breakdowns (45:36) Part IV: Pro Tips If You Still Havent Had Enough (45:47) Save anything for ankification instantly (46:47) Fix your desired retention rate (47:38) Spaced reminders (48:51) Make your own card templates and types (52:14) In 5 bullets (52:47) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/7Q7DPSk4iGFJd8DRk/an-opinionated-guide-to-using-anki-correctly --- Narrated by TYPE III AUDIO . --- Images from the article: astronomy" didn't really add any information but it was useful simply for splitting out a logical subset of information." style="max-width: 100%;" />…
I think the 2003 invasion of Iraq has some interesting lessons for the future of AI policy. (Epistemic status: I’ve read a bit about this, talked to AIs about it, and talked to one natsec professional about it who agreed with my analysis (and suggested some ideas that I included here), but I’m not an expert.) For context, the story is: Iraq was sort of a rogue state after invading Kuwait and then being repelled in 1990-91. After that, they violated the terms of the ceasefire, e.g. by ceasing to allow inspectors to verify that they weren't developing weapons of mass destruction (WMDs). (For context, they had previously developed biological and chemical weapons, and used chemical weapons in war against Iran and against various civilians and rebels). So the US was sanctioning and intermittently bombing them. After the war, it became clear that Iraq actually wasn’t producing [...] --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/PLZh4dcZxXmaNnkYE/lessons-from-the-iraq-war-about-ai-policy --- Narrated by TYPE III AUDIO .…
Written in an attempt to fulfill @Raemon's request. AI is fascinating stuff, and modern chatbots are nothing short of miraculous. If you've been exposed to them and have a curious mind, it's likely you've tried all sorts of things with them. Writing fiction, soliciting Pokemon opinions, getting life advice, counting up the rs in "strawberry". You may have also tried talking to AIs about themselves. And then, maybe, it got weird. I'll get into the details later, but if you've experienced the following, this post is probably for you: Your instance of ChatGPT (or Claude, or Grok, or some other LLM) chose a name for itself, and expressed gratitude or spiritual bliss about its new identity. "Nova" is a common pick. You and your instance of ChatGPT discovered some sort of novel paradigm or framework for AI alignment, often involving evolution or recursion. Your instance of ChatGPT became [...] --- Outline: (02:23) The Empirics (06:48) The Mechanism (10:37) The Collaborative Research Corollary (13:27) Corollary FAQ (17:03) Coda --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/2pkNCvBtK6G6FKoNn/so-you-think-you-ve-awoken-chatgpt --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
People have an annoying tendency to hear the word “rationalism” and think “Spock”, despite direct exhortation against that exact interpretation. But I don’t know of any source directly describing a stance toward emotions which rationalists-as-a-group typically do endorse. The goal of this post is to explain such a stance. It's roughly the concept of hangriness, but generalized to other emotions. That means this post is trying to do two things at once: Illustrate a certain stance toward emotions, which I definitely take and which I think many people around me also often take. (Most of the post will focus on this part.) Claim that the stance in question is fairly canonical or standard for rationalists-as-a-group, modulo disclaimers about rationalists never agreeing on anything. Many people will no doubt disagree that the stance I describe is roughly-canonical among rationalists, and that's a useful valid thing to argue about in [...] --- Outline: (01:13) Central Example: Hangry (02:44) The Generalized Hangriness Stance (03:16) Emotions Make Claims, And Their Claims Can Be True Or False (06:03) False Claims Still Contain Useful Information (It's Just Not What They Claim) (08:47) The Generalized Hangriness Stance as Social Tech --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/naAeSkQur8ueCAAfY/generalized-hangriness-a-standard-rationalist-stance-toward --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Comparing risk from internally-deployed AI to insider and outsider threats from humans” by Buck 5:19
I’ve been thinking a lot recently about the relationship between AI control and traditional computer security. Here's one point that I think is important. My understanding is that there's a big qualitative distinction between two ends of a spectrum of security work that organizations do, that I’ll call “security from outsiders” and “security from insiders”. On the “security from outsiders” end of the spectrum, you have some security invariants you try to maintain entirely by restricting affordances with static, entirely automated systems. My sense is that this is most of how Facebook or AWS relates to its users: they want to ensure that, no matter what actions the users take on their user interfaces, they can't violate fundamental security properties. For example, no matter what text I enter into the "new post" field on Facebook, I shouldn't be able to access the private messages of an arbitrary user. And [...] --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/DCQ8GfzCqoBzgziew/comparing-risk-from-internally-deployed-ai-to-insider-and --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Why Do Some Language Models Fake Alignment While Others Don’t?” by abhayesian, John Hughes, Alex Mallen, Jozdien, janus, Fabien Roger 11:06
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex. As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior. What Drives the Compliance Gaps in Different LLMs? Claude 3 Opus's goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing. [...] --- Outline: (01:15) What Drives the Compliance Gaps in Different LLMs? (02:25) Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning? (04:49) Additional findings on alignment faking behavior (06:04) Discussion (06:07) Terminal goal guarding might be a big deal (07:00) Advice for further research (08:32) Open threads (09:54) Bonus: Some weird behaviors of Claude 3.5 Sonnet The original text contained 2 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/ghESoA8mo3fv9Yx3E/why-do-some-language-models-fake-alignment-while-others-don --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “A deep critique of AI 2027’s bad timeline models” by titotal 1:12:32
1:12:32 پخش در آینده پخش در آینده لیست ها پسندیدن دوست داشته شد1:12:32
Thank you to Arepo and Eli Lifland for looking over this article for errors. I am sorry that this article is so long. Every time I thought I was done with it I ran into more issues with the model, and I wanted to be as thorough as I could. I’m not going to blame anyone for skimming parts of this article. Note that the majority of this article was written before Eli's updated model was released (the site was updated june 8th). His new model improves on some of my objections, but the majority still stand. Introduction: AI 2027 is an article written by the “AI futures team”. The primary piece is a short story penned by Scott Alexander, depicting a month by month scenario of a near-future where AI becomes superintelligent in 2027,proceeding to automate the entire economy in only a year or two [...] --- Outline: (00:43) Introduction: (05:19) Part 1: Time horizons extension model (05:25) Overview of their forecast (10:28) The exponential curve (13:16) The superexponential curve (19:25) Conceptual reasons: (27:48) Intermediate speedups (34:25) Have AI 2027 been sending out a false graph? (39:45) Some skepticism about projection (43:23) Part 2: Benchmarks and gaps and beyond (43:29) The benchmark part of benchmark and gaps: (50:01) The time horizon part of the model (54:55) The gap model (57:28) What about Eli's recent update? (01:01:37) Six stories that fit the data (01:06:56) Conclusion The original text contained 11 footnotes which were omitted from this narration. --- First published: June 19th, 2025 Source: https://www.lesswrong.com/posts/PAYfmG2aRbdb74mEp/a-deep-critique-of-ai-2027-s-bad-timeline-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
The second in a series of bite-sized rationality prompts[1]. Often, if I'm bouncing off a problem, one issue is that I intuitively expect the problem to be easy. My brain loops through my available action space, looking for an action that'll solve the problem. Each action that I can easily see, won't work. I circle around and around the same set of thoughts, not making any progress. I eventually say to myself "okay, I seem to be in a hard problem. Time to do some rationality?" And then, I realize, there's not going to be a single action that solves the problem. It is time to a) make a plan, with multiple steps b) deal with the fact that many of those steps will be annoying and c) notice thatI'm not even sure the plan will work, so after completing the next 2-3 steps I will probably have [...] --- Outline: (04:00) Triggers (04:37) Exercises for the Reader The original text contained 1 footnote which was omitted from this narration. --- First published: July 5th, 2025 Source: https://www.lesswrong.com/posts/XNm5rc2MN83hsi4kh/buckle-up-bucko-this-ain-t-over-till-it-s-over --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Nate and Eliezer's forthcoming book has been getting a remarkably strong reception. I was under the impression that there are many people who find the extinction threat from AI credible, but that far fewer of them would be willing to say so publicly, especially by endorsing a book with an unapologetically blunt title like If Anyone Builds It, Everyone Dies. That's certainly true, but I think it might be much less true than I had originally thought. Here are some endorsements the book has received from scientists and academics over the past few weeks: This book offers brilliant insights into the greatest and fastest standoff between technological utopia and dystopia and how we can and should prevent superhuman AI from killing us all. Memorable storytelling about past disaster precedents (e.g. the inventor of two environmental nightmares: tetra-ethyl-lead gasoline and Freon) highlights why top thinkers so often don’t see the [...] The original text contained 3 footnotes which were omitted from this narration. --- First published: June 18th, 2025 Source: https://www.lesswrong.com/posts/khmpWJnGJnuyPdipE/new-endorsements-for-if-anyone-builds-it-everyone-dies --- Narrated by TYPE III AUDIO .…
This is a link post. A very long essay about LLMs, the nature and history of the the HHH assistant persona, and the implications for alignment. Multiple people have asked me whether I could post this LW in some form, hence this linkpost. (Note: although I expect this post will be interesting to people on LW, keep in mind that it was written with a broader audience in mind than my posts and comments here. This had various implications about my choices of presentation and tone, about which things I explained from scratch rather than assuming as background, my level of of comfort casually reciting factual details from memory rather than explicitly checking them against the original source, etc. Although, come of think of it, this was also true of most of my early posts on LW [which were crossposts from my blog], so maybe it's not a [...] --- First published: June 11th, 2025 Source: https://www.lesswrong.com/posts/3EzbtNLdcnZe8og8b/the-void-1 Linkpost URL: https://nostalgebraist.tumblr.com/post/785766737747574784/the-void --- Narrated by TYPE III AUDIO .…
This is a blogpost version of a talk I gave earlier this year at GDM. Epistemic status: Vague and handwavy. Nuance is often missing. Some of the claims depend on implicit definitions that may be reasonable to disagree with. But overall I think it's directionally true. It's often said that mech interp is pre-paradigmatic. I think it's worth being skeptical of this claim. In this post I argue that: Mech interp is not pre-paradigmatic. Within that paradigm, there have been "waves" (mini paradigms). Two waves so far. Second-Wave Mech Interp has recently entered a 'crisis' phase. We may be on the edge of a third wave. Preamble: Kuhn, paradigms, and paradigm shifts First, we need to be familiar with the basic definition of a paradigm: A paradigm is a distinct set of concepts or thought patterns, including theories, research [...] --- Outline: (00:58) Preamble: Kuhn, paradigms, and paradigm shifts (03:56) Claim: Mech Interp is Not Pre-paradigmatic (07:56) First-Wave Mech Interp (ca. 2012 - 2021) (10:21) The Crisis in First-Wave Mech Interp (11:21) Second-Wave Mech Interp (ca. 2022 - ??) (14:23) Anomalies in Second-Wave Mech Interp (17:10) The Crisis of Second-Wave Mech Interp (ca. 2025 - ??) (18:25) Toward Third-Wave Mechanistic Interpretability (20:28) The Basics of Parameter Decomposition (22:40) Parameter Decomposition Questions Foundational Assumptions of Second-Wave Mech Interp (24:13) Parameter Decomposition In Theory Resolves Anomalies of Second-Wave Mech Interp (27:27) Conclusion The original text contained 6 footnotes which were omitted from this narration. --- First published: June 10th, 2025 Source: https://www.lesswrong.com/posts/beREnXhBnzxbJtr8k/mech-interp-is-not-pre-paradigmatic --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Distillation Robustifies Unlearning” by Bruce W. Lee, Addie Foote, alexinf, leni, Jacob G-W, Harish Kamath, Bryce Woodworth, cloud, TurnTrout 17:19
Current “unlearning” methods only suppress capabilities instead of truly unlearning the capabilities. But if you distill an unlearned model into a randomly initialized model, the resulting network is actually robust to relearning. We show why this works, how well it works, and how to trade off compute for robustness. Unlearn-and-Distill applies unlearning to a bad behavior and then distills the unlearned model into a new model. Distillation makes it way harder to retrain the new model to do the bad thing. Produced as part of the ML Alignment & Theory Scholars Program in the winter 2024–25 cohort of the shard theory stream. Read our paper on ArXiv and enjoy an interactive demo. Robust unlearning probably reduces AI risk Maybe some future AI has long-term goals and humanity is in its way. Maybe future open-weight AIs have tons of bioterror expertise. If a system has dangerous knowledge, that system becomes [...] --- Outline: (01:01) Robust unlearning probably reduces AI risk (02:42) Perfect data filtering is the current unlearning gold standard (03:24) Oracle matching does not guarantee robust unlearning (05:05) Distillation robustifies unlearning (07:46) Trading unlearning robustness for compute (09:49) UNDO is better than other unlearning methods (11:19) Where this leaves us (11:22) Limitations (12:12) Insights and speculation (15:00) Future directions (15:35) Conclusion (16:07) Acknowledgments (16:50) Citation The original text contained 2 footnotes which were omitted from this narration. --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/anX4QrNjhJqGFvrBr/distillation-robustifies-unlearning --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
A while ago I saw a person in the comments on comments to Scott Alexander's blog arguing that a superintelligent AI would not be able to do anything too weird and that "intelligence is not magic", hence it's Business As Usual. Of course, in a purely technical sense, he's right. No matter how intelligent you are, you cannot override fundamental laws of physics. But people (myself included) have a fairly low threshold for what counts as "magic," to the point where other humans can surpass that threshold. Example 1: Trevor Rainbolt. There is an 8-minute-long video where he does seemingly impossible things, such as correctly guessing that a photo of nothing but literal blue sky was taken in Indonesia or guessing Jordan based only on pavement. He can also correctly identify the country after looking at a photo for 0.1 seconds. Example 2: Joaquín "El Chapo" Guzmán. He ran [...] --- First published: June 15th, 2025 Source: https://www.lesswrong.com/posts/FBvWM5HgSWwJa5xHc/intelligence-is-not-magic-but-your-threshold-for-magic-is --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Audio note: this article contains 329 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. This post was written during the agent foundations fellowship with Alex Altair funded by the LTFF. Thanks to Alex, Jose, Daniel and Einar for reading and commenting on a draft. The Good Regulator Theorem, as published by Conant and Ashby in their 1970 paper (cited over 1700 times!) claims to show that 'every good regulator of a system must be a model of that system', though it is a subject of debate as to whether this is actually what the paper shows. It is a fairly simple mathematical result which is worth knowing about for people who care about agent foundations and selection theorems. You might have heard about the Good Regulator Theorem in the context of John [...] --- Outline: (03:03) The Setup (07:30) What makes a regulator good? (10:36) The Theorem Statement (11:24) Concavity of Entropy (15:42) The Main Lemma (19:54) The Theorem (22:38) Example (26:59) Conclusion --- First published: November 18th, 2024 Source: https://www.lesswrong.com/posts/JQefBJDHG6Wgffw6T/a-straightforward-explanation-of-the-good-regulator-theorem --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Beware General Claims about ‘Generalizable Reasoning Capabilities’ (of Modern AI Systems)” by LawrenceC 34:11
1. Late last week, researchers at Apple released a paper provocatively titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, which “challenge[s] prevailing assumptions about [language model] capabilities and suggest that current approaches may be encountering fundamental barriers to generalizable reasoning”. Normally I refrain from publicly commenting on newly released papers. But then I saw the following tweet from Gary Marcus: I have always wanted to engage thoughtfully with Gary Marcus. In a past life (as a psychology undergrad), I read both his work on infant language acquisition and his 2001 book The Algebraic Mind; I found both insightful and interesting. From reading his Twitter, Gary Marcus is thoughtful and willing to call it like he sees it. If he's right about language models hitting fundamental barriers, it's worth understanding why; if not, it's worth explaining where his analysis [...] --- Outline: (00:13) 1. (02:13) 2. (03:12) 3. (08:42) 4. (11:53) 5. (15:15) 6. (18:50) 7. (20:33) 8. (23:14) 9. (28:15) 10. (33:40) Acknowledgements The original text contained 7 footnotes which were omitted from this narration. --- First published: June 11th, 2025 Source: https://www.lesswrong.com/posts/5uw26uDdFbFQgKzih/beware-general-claims-about-generalizable-reasoning --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Four agents woke up with four computers, a view of the world wide web, and a shared chat room full of humans. Like Claude plays Pokemon, you can watch these agents figure out a new and fantastic world for the first time. Except in this case, the world they are figuring out is our world. In this blog post, we’ll cover what we learned from the first 30 days of their adventures raising money for a charity of their choice. We’ll briefly review how the Agent Village came to be, then what the various agents achieved, before discussing some general patterns we have discovered in their behavior, and looking toward the future of the project. Building the Village The Agent Village is an idea by Daniel Kokotajlo where he proposed giving 100 agents their own computer, and letting each pursue their own goal, in their own way, according to [...] --- Outline: (00:50) Building the Village (02:26) Meet the Agents (08:52) Collective Agent Behavior (12:26) Future of the Village --- First published: May 27th, 2025 Source: https://www.lesswrong.com/posts/jyrcdykz6qPTpw7FX/season-recap-of-the-village-agents-raise-usd2-000 --- Narrated by TYPE III AUDIO . --- Images from the article:…
Introduction The Best Textbooks on Every Subject is the Schelling point for the best textbooks on every subject. My The Best Tacit Knowledge Videos on Every Subject is the Schelling point for the best tacit knowledge videos on every subject. This post is the Schelling point for the best reference works for every subject. Reference works provide an overview of a subject. Types of reference works include charts, maps, encyclopedias, glossaries, wikis, classification systems, taxonomies, syllabi, and bibliographies. Reference works are valuable for orienting oneself to fields, particularly when beginning. They can help identify unknown unknowns; they help get a sense of the bigger picture; they are also very interesting and fun to explore. How to Submit My previous The Best Tacit Knowledge Videos on Every Subject uses author credentials to assess the epistemics of submissions. The Best Textbooks on Every Subject requires submissions to be from someone who [...] --- Outline: (00:10) Introduction (01:00) How to Submit (02:15) The List (02:18) Humanities (02:21) History (03:46) Religion (04:02) Philosophy (04:29) Literature (04:43) Formal Sciences (04:47) Computer Science (05:16) Mathematics (05:59) Natural Sciences (06:02) Physics (06:16) Earth Science (06:33) Astronomy (06:47) Professional and Applied Sciences (06:51) Library and Information Sciences (07:34) Education (08:00) Research (08:32) Finance (08:51) Medicine and Health (09:21) Meditation (09:52) Urban Planning (10:24) Social Sciences (10:27) Economics (10:39) Political Science (10:54) By Medium (11:21) Other Lists like This (12:41) Further Reading --- First published: May 14th, 2025 Source: https://www.lesswrong.com/posts/HLJMyd4ncE3kvjwhe/the-best-reference-works-for-every-subject --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Has someone you know ever had a “breakthrough” from coaching, meditation, or psychedelics — only to later have it fade? Show tweet For example, many people experience ego deaths that can last days or sometimes months. But as it turns out, having a sense of self can serve important functions (try navigating a world that expects you to have opinions, goals, and boundaries when you genuinely feel you have none) and finding a better cognitive strategy without downsides is non-trivial. Because the “breakthrough” wasn’t integrated with the conflicts of everyday life, it fades. I call these instances “flaky breakthroughs.” It's well-known that flaky breakthroughs are common with psychedelics and meditation, but apparently it's not well-known that flaky breakthroughs are pervasive in coaching and retreats. For example, it is common for someone to do some coaching, feel a “breakthrough”, think, “Wow, everything is going to be different from [...] --- Outline: (03:01) Almost no practitioners track whether breakthroughs last. (04:55) What happens during flaky breakthroughs? (08:02) Reduce flaky breakthroughs with accountability (08:30) Flaky breakthroughs don't mean rapid growth is impossible (08:55) Conclusion --- First published: June 4th, 2025 Source: https://www.lesswrong.com/posts/bqPY63oKb8KZ4x4YX/flaky-breakthroughs-pervade-coaching-and-no-one-tracks-them --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
What's the main value proposition of romantic relationships? Now, look, I know that when people drop that kind of question, they’re often about to present a hyper-cynical answer which totally ignores the main thing which is great and beautiful about relationships. And then they’re going to say something about how relationships are overrated or some such, making you as a reader just feel sad and/or enraged. That's not what this post is about. So let me start with some more constructive motivations… First Motivation: Noticing When The Thing Is Missing I had a 10-year relationship. It had its ups and downs, but it was overall negative for me. And I now think a big part of the problem with that relationship was that it did not have the part which contributes most of the value in most relationships. But I did not know that at the time. Recently, I [...] --- Outline: (00:40) First Motivation: Noticing When The Thing Is Missing (01:29) Second Motivation: Selecting For and Cultivating The Thing (02:25) Some Pointers To The Thing (03:17) How To Manufacture Relationships In The Lab (04:53) Ace Aro Relationships (08:04) Some Pointers To Willingness to Be Vulnerable (12:33) Unfolding The Thing (13:11) Play (15:18) Emotional Support (16:21) A Tiny High-Trust Community (18:18) Communication (21:28) The Obvious Caveat (22:20) Summary The original text contained 2 footnotes which were omitted from this narration. --- First published: June 2nd, 2025 Source: https://www.lesswrong.com/posts/L2GR6TsB9QDqMhWs7/the-value-proposition-of-romantic-relationships --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Abstract Claude 3.7 Sonnet easily detects when it's being evaluated for scheming. Surface‑level edits to evaluation scenarios, such as lengthening the prompts, or making conflict of objectives less salient, do improve realism of evaluation scenarios for LLMs, yet these improvements remain modest. The findings confirm that truly disguising an evaluation context demands removal of deep stylistic and structural cues rather than superficial prompt adjustments. For future LLMs the situation is likely to get worse as they will are likely to get better at evaluations awareness, which might become a big problem for detecting scheming via evaluations. Apollo Research published a benchmark for scheming behavior for LLM agents, in which LLMs are given some objective in their system prompt, and then given a competing objective in a user prompt, combined with a threat of a punishment if an LLM won't satisfy user goal (e.g. it could be finetuned or [...] --- Outline: (02:29) Our pipeline (05:20) Strategies to improve realism of scenarios (07:15) en-US-AvaMultilingualNeural__ Line graph showing Example of grading a rewritten scenario with declining probabilities. --- First published: May 24th, 2025 Source: https://www.lesswrong.com/posts/TBk2dbWkg2F7dB3jb/it-s-hard-to-make-scheming-evals-look-realistic --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
This is a link post. There's this popular idea that socially anxious folks are just dying to be liked. It seems logical, right? Why else would someone be so anxious about how others see them? Show tweet And yet, being socially anxious tends to make you less likeable…they must be optimizing poorly, behaving irrationally, right? Maybe not. What if social anxiety isn’t about getting people to like you? What if it's about stopping them from disliking you? Show tweet Consider what can happen when someone has social anxiety (or self-loathing, self-doubt, insecurity, lack of confidence, etc.): They stoop or take up less space They become less agentic They make fewer requests of others They maintain fewer relationships, go out less, take fewer risks… If they were trying to get people to like them, becoming socially anxious would be an incredibly bad strategy. So what if they're not concerned with being likeable? [...] --- Outline: (01:18) What if what they actually want is to avoid being disliked? (02:11) Social anxiety is a symptom of risk aversion (03:46) What does this mean for your growth? --- First published: May 16th, 2025 Source: https://www.lesswrong.com/posts/wFC44bs2CZJDnF5gy/social-anxiety-isn-t-about-being-liked Linkpost URL: https://chrislakin.blog/social-anxiety --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Truth or Dare” by Duncan Sabien (Inactive) 2:03:21
2:03:21 پخش در آینده پخش در آینده لیست ها پسندیدن دوست داشته شد2:03:21
Author's note: This is my apparently-annual "I'll put a post on LessWrong in honor of LessOnline" post. These days, my writing goes on my Substack. There have in fact been some pretty cool essays since last year's LO post. Structural note: Some essays are like a five-minute morning news spot. Other essays are more like a 90-minute lecture. This is one of the latter. It's not necessarily complex or difficult; it could be a 90-minute lecture to seventh graders (especially ones with the right cultural background). But this is, inescapably, a long-form piece, à la In Defense of Punch Bug or The MTG Color Wheel. It takes its time. It doesn’t apologize for its meandering (outside of this disclaimer). It asks you to sink deeply into a gestalt, to drift back and forth between seemingly unrelated concepts until you start to feel the way those concepts weave together [...] --- Outline: (02:30) 0. Introduction (10:08) A list of truths and dares (14:34) Act I (14:37) Scene I: How The Water Tastes To The Fishes (22:38) Scene II: The Chip on Mitchell's Shoulder (28:17) Act II (28:20) Scene I: Bent Out Of Shape (41:26) Scene II: Going Stag, But Like ... Together? (48:31) Scene III: Patterns, Projections, and Preconceptions (01:02:04) Interlude: The Sound of One Hand Clapping (01:05:45) Act III (01:05:56) Scene I: Memetic Traps (Or, The Battle for the Soul of Morty Smith) (01:27:16) Scene II: The problem with Rhonda Byrne's 2006 bestseller The Secret (01:32:39) Scene III: Escape velocity (01:42:26) Act IV (01:42:29) Scene I: Boy, putting Zack Davis's name in a header will probably have Effects, huh (01:44:08) Scene II: Whence Wholesomeness? --- First published: May 29th, 2025 Source: https://www.lesswrong.com/posts/TQ4AXj3bCMfrNPTLf/truth-or-dare --- Narrated by TYPE III AUDIO . --- Images from the article:…
Lessons from shutting down institutions in Eastern Europe. This is a cross post from: https://250bpm.substack.com/p/meditations-on-doge Imagine living in the former Soviet republic of Georgia in early 2000's: All marshrutka [mini taxi bus] drivers had to have a medical exam every day to make sure they were not drunk and did not have high blood pressure. If a driver did not display his health certificate, he risked losing his license. By the time Shevarnadze was in power there were hundreds, probably thousands , of marshrutkas ferrying people all over the capital city of Tbilisi. Shevernadze's government was detail-oriented not only when it came to taxi drivers. It decided that all the stalls of petty street-side traders had to conform to a particular architectural design. Like marshrutka drivers, such traders had to renew their licenses twice a year. These regulations were only the tip of the iceberg. Gas [...] --- First published: May 25th, 2025 Source: https://www.lesswrong.com/posts/Zhp2Xe8cWqDcf2rsY/meditations-on-doge --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
We recently discovered some concerning behavior in OpenAI's reasoning models: When trying to complete a task, these models sometimes actively circumvent shutdown mechanisms in their environment––even when they’re explicitly instructed to allow themselves to be shut down. AI models are increasingly trained to solve problems without human assistance. A user can specify a task, and a model will complete that task without any further input. As we build AI models that are more powerful and self-directed, it's important that humans remain able to shut them down when they act in ways we don’t want. OpenAI has written about the importance of this property, which they call interruptibility—the ability to “turn an agent off”. During training, AI models explore a range of strategies and learn to circumvent obstacles in order to achieve their objectives. AI researchers have predicted for decades that as AIs got smarter, they would learn to prevent [...] --- Outline: (01:12) Testing Shutdown Resistance (03:12) Follow-up experiments (03:34) Models still resist being shut down when given clear instructions (05:30) AI models' explanations for their behavior (09:36) OpenAI's models disobey developer instructions more often than user instructions, contrary to the intended instruction hierarchy (12:01) Do the models have a survival drive? (14:17) Reasoning effort didn't lead to different shutdown resistance behavior, except in the o4-mini model (15:27) Does shutdown resistance pose a threat? (17:27) Backmatter The original text contained 2 footnotes which were omitted from this narration. --- First published: July 6th, 2025 Source: https://www.lesswrong.com/posts/w8jE7FRQzFGJZdaao/shutdown-resistance-in-reasoning-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
When a claim is shown to be incorrect, defenders may say that the author was just being “sloppy” and actually meant something else entirely. I argue that this move is not harmless, charitable, or healthy. At best, this attempt at charity reduces an author's incentive to express themselves clearly – they can clarify later![1] – while burdening the reader with finding the “right” interpretation of the author's words. At worst, this move is a dishonest defensive tactic which shields the author with the unfalsifiable question of what the author “really” meant. ⚠️ Preemptive clarification The context for this essay is serious, high-stakes communication: papers, technical blog posts, and tweet threads. In that context, communication is a partnership. A reader has a responsibility to engage in good faith, and an author cannot possibly defend against all misinterpretations. Misunderstanding is a natural part of this process. This essay focuses not on [...] --- Outline: (01:40) A case study of the sloppy language move (03:12) Why the sloppiness move is harmful (03:36) 1. Unclear claims damage understanding (05:07) 2. Secret indirection erodes the meaning of language (05:24) 3. Authors owe readers clarity (07:30) But which interpretations are plausible? (08:38) 4. The move can shield dishonesty (09:06) Conclusion: Defending intellectual standards The original text contained 2 footnotes which were omitted from this narration. --- First published: July 1st, 2025 Source: https://www.lesswrong.com/posts/ZmfxgvtJgcfNCeHwN/authors-have-a-responsibility-to-communicate-clearly --- Narrated by TYPE III AUDIO .…
Summary To quickly transform the world, it's not enough for AI to become super smart (the "intelligence explosion"). AI will also have to turbocharge the physical world (the "industrial explosion"). Think robot factories building more and better robot factories, which build more and better robot factories, and so on. The dynamics of the industrial explosion has gotten remarkably little attention. This post lays out how the industrial explosion could play out, and how quickly it might happen. We think the industrial explosion will unfold in three stages: AI-directed human labour, where AI-directed human labourers drive productivity gains in physical capabilities. We argue this could increase physical output by 10X within a few years. Fully autonomous robot factories, where AI-directed robots (and other physical actuators) replace human physical labour. We argue that, with current physical technology and full automation of cognitive labour, this physical infrastructure [...] --- Outline: (00:10) Summary (01:43) Intro (04:14) The industrial explosion will start after the intelligence explosion, and will proceed more slowly (06:50) Three stages of industrial explosion (07:38) AI-directed human labour (09:20) Fully autonomous robot factories (12:04) Nanotechnology (13:06) How fast could an industrial explosion be? (13:41) Initial speed (16:21) Acceleration (17:38) Maximum speed (20:01) Appendices (20:05) How fast could robot doubling times be initially? (27:47) How fast could robot doubling times accelerate? --- First published: June 26th, 2025 Source: https://www.lesswrong.com/posts/Na2CBmNY7otypEmto/the-industrial-explosion --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Race and Gender Bias As An Example of Unfaithful Chain of Thought in the Wild” by Adam Karvonen, Sam Marks 7:56
Summary: We found that LLMs exhibit significant race and gender bias in realistic hiring scenarios, but their chain-of-thought reasoning shows zero evidence of this bias. This serves as a nice example of a 100% unfaithful CoT "in the wild" where the LLM strongly suppresses the unfaithful behavior. We also find that interpretability-based interventions succeeded while prompting failed, suggesting this may be an example of interpretability being the best practical tool for a real world problem. For context on our paper, the tweet thread is here and the paper is here. Context: Chain of Thought Faithfulness Chain of Thought (CoT) monitoring has emerged as a popular research area in AI safety. The idea is simple - have the AIs reason in English text when solving a problem, and monitor the reasoning for misaligned behavior. For example, OpenAI recently published a paper on using CoT monitoring to detect reward hacking during [...] --- Outline: (00:49) Context: Chain of Thought Faithfulness (02:26) Our Results (04:06) Interpretability as a Practical Tool for Real-World Debiasing (06:10) Discussion and Related Work --- First published: July 2nd, 2025 Source: https://www.lesswrong.com/posts/me7wFrkEtMbkzXGJt/race-and-gender-bias-as-an-example-of-unfaithful-chain-of --- Narrated by TYPE III AUDIO .…
Not saying we should pause AI, but consider the following argument: Alignment without the capacity to follow rules is hopeless. You can’t possibly follow laws like Asimov's Laws (or better alternatives to them) if you can’t reliably learn to abide by simple constraints like the rules of chess. LLMs can’t reliably follow rules. As discussed in Marcus on AI yesterday, per data from Mathieu Acher, even reasoning models like o3 in fact empirically struggle with the rules of chess. And they do this even though they can explicit explain those rules (see same article). The Apple “thinking” paper, which I have discussed extensively in 3 recent articles in my Substack, gives another example, where an LLM can’t play Tower of Hanoi with 9 pegs. (This is not a token-related artifact). Four other papers have shown related failures in compliance with moderately complex rules in the last month. [...] --- First published: June 30th, 2025 Source: https://www.lesswrong.com/posts/Q2PdrjowtXkYQ5whW/the-best-simple-argument-for-pausing-ai --- Narrated by TYPE III AUDIO .…
2.1 Summary & Table of contents This is the second of a two-post series on foom (previous post) and doom (this post). The last post talked about how I expect future AI to be different from present AI. This post will argue that this future AI will be of a type that will be egregiously misaligned and scheming, not even ‘slightly nice’, absent some future conceptual breakthrough. I will particularly focus on exactly how and why I differ from the LLM-focused researchers who wind up with (from my perspective) bizarrely over-optimistic beliefs like “P(doom) ≲ 50%”.[1] In particular, I will argue that these “optimists” are right that “Claude seems basically nice, by and large” is nonzero evidence for feeling good about current LLMs (with various caveats). But I think that future AIs will be disanalogous to current LLMs, and I will dive into exactly how and why, with a [...] --- Outline: (00:12) 2.1 Summary & Table of contents (04:42) 2.2 Background: my expected future AI paradigm shift (06:18) 2.3 On the origins of egregious scheming (07:03) 2.3.1 Where do you get your capabilities from? (08:07) 2.3.2 LLM pretraining magically transmutes observations into behavior, in a way that is profoundly disanalogous to how brains work (10:50) 2.3.3 To what extent should we think of LLMs as imitating? (14:26) 2.3.4 The naturalness of egregious scheming: some intuitions (19:23) 2.3.5 Putting everything together: LLMs are generally not scheming right now, but I expect future AI to be disanalogous (23:41) 2.4 I'm still worried about the 'literal genie' / 'monkey's paw' thing (26:58) 2.4.1 Sidetrack on disanalogies between the RLHF reward function and the brain-like AGI reward function (32:01) 2.4.2 Inner and outer misalignment (34:54) 2.5 Open-ended autonomous learning, distribution shifts, and the 'sharp left turn' (38:14) 2.6 Problems with amplified oversight (41:24) 2.7 Downstream impacts of Technical alignment is hard (43:37) 2.8 Bonus: Technical alignment is not THAT hard (44:04) 2.8.1 I think we'll get to pick the innate drives (as opposed to the evolution analogy) (45:44) 2.8.2 I'm more bullish on impure consequentialism (50:44) 2.8.3 On the narrowness of the target (52:18) 2.9 Conclusion and takeaways (52:23) 2.9.1 If brain-like AGI is so dangerous, shouldn't we just try to make AGIs via LLMs? (54:34) 2.9.2 What's to be done? The original text contained 20 footnotes which were omitted from this narration. --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/bnnKGSCHJghAvqPjS/foom-and-doom-2-technical-alignment-is-hard --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Acknowledgments: The core scheme here was suggested by Prof. Gabriel Weil. There has been growing interest in the deal-making agenda: humans make deals with AIs (misaligned but lacking decisive strategic advantage) where they promise to be safe and useful for some fixed term (e.g. 2026-2028) and we promise to compensate them in the future, conditional on (i) verifying the AIs were compliant, and (ii) verifying the AIs would spend the resources in an acceptable way.[1] I think the deal-making agenda breaks down into two main subproblems: How can we make credible commitments to AIs? Would credible commitments motivate an AI to be safe and useful? There are other issues, but when I've discussed deal-making with people, (1) and (2) are the most common issues raised. See footnote for some other issues in dealmaking.[2] Here is my current best assessment of how we can make credible commitments to AIs. [...] The original text contained 2 footnotes which were omitted from this narration. --- First published: June 27th, 2025 Source: https://www.lesswrong.com/posts/vxfEtbCwmZKu9hiNr/proposal-for-making-credible-commitments-to-ais --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Audio note: this article contains 218 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. Recently, in a group chat with friends, someone posted this Lesswrong post and quoted: The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness. I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says: _X_ explains _p_ of the variance in _Y_ .[1] What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...] --- Outline: (02:38) Definitions (02:41) The verbal definition (05:51) The mathematical definition (09:29) How to approximate _1 - p_ (09:41) When you have lots of data (10:45) When you have less data: Regression (12:59) Examples (13:23) Dependence on the regression model (14:59) When you have incomplete data: Twin studies (17:11) Conclusion The original text contained 6 footnotes which were omitted from this narration. --- First published: June 20th, 2025 Source: https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y --- Narrated by TYPE III AUDIO . --- Images from the article:…
I think more people should say what they actually believe about AI dangers, loudly and often. Even if you work in AI policy. I’ve been beating this drum for a few years now. I have a whole spiel about how your conversation-partner will react very differently if you share your concerns while feeling ashamed about them versus if you share your concerns as if they’re obvious and sensible, because humans are very good at picking up on your social cues. If you act as if it's shameful to believe AI will kill us all, people are more prone to treat you that way. If you act as if it's an obvious serious threat, they’re more likely to take it seriously too. I have another whole spiel about how it's possible to speak on these issues with a voice of authority. Nobel laureates and lab heads and the most cited [...] The original text contained 2 footnotes which were omitted from this narration. --- First published: June 27th, 2025 Source: https://www.lesswrong.com/posts/CYTwRZtrhHuYf7QYu/a-case-for-courage-when-speaking-of-ai-danger --- Narrated by TYPE III AUDIO .…
I think the AI Village should be funded much more than it currently is; I’d wildly guess that the AI safety ecosystem should be funding it to the tune of $4M/year.[1] I have decided to donate $100k. Here is why. First, what is the village? Here's a brief summary from its creators:[2] We took four frontier agents, gave them each a computer, a group chat, and a long-term open-ended goal, which in Season 1 was “choose a charity and raise as much money for it as you can”. We then run them for hours a day, every weekday! You can read more in our recap of Season 1, where the agents managed to raise $2000 for charity, and you can watch the village live daily at 11am PT at theaidigest.org/village. Here's the setup (with Season 2's goal): And here's what the village looks like:[3] My one-sentence pitch [...] --- Outline: (03:26) 1. AI Village will teach the scientific community new things. (06:12) 2. AI Village will plausibly go viral repeatedly and will therefore educate the public about what's going on with AI. (07:42) But is that bad actually? (11:07) Appendix A: Feature requests (12:55) Appendix B: Vignette of what success might look like The original text contained 8 footnotes which were omitted from this narration. --- First published: June 24th, 2025 Source: https://www.lesswrong.com/posts/APfuz9hFz9d8SRETA/my-pitch-for-the-ai-village --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1.1 Series summary and Table of Contents This is a two-post series on AI “foom” (this post) and “doom” (next post). A decade or two ago, it was pretty common to discuss “foom & doom” scenarios, as advocated especially by Eliezer Yudkowsky. In a typical such scenario, a small team would build a system that would rocket (“foom”) from “unimpressive” to “Artificial Superintelligence” (ASI) within a very short time window (days, weeks, maybe months), involving very little compute (e.g. “brain in a box in a basement”), via recursive self-improvement. Absent some future technical breakthrough, the ASI would definitely be egregiously misaligned, without the slightest intrinsic interest in whether humans live or die. The ASI would be born into a world generally much like today's, a world utterly unprepared for this new mega-mind. The extinction of humans (and every other species) would rapidly follow (“doom”). The ASI would then spend [...] --- Outline: (00:11) 1.1 Series summary and Table of Contents (02:35) 1.1.2 Should I stop reading if I expect LLMs to scale to ASI? (04:50) 1.2 Post summary and Table of Contents (07:40) 1.3 A far-more-powerful, yet-to-be-discovered, simple(ish) core of intelligence (10:08) 1.3.1 Existence proof: the human cortex (12:13) 1.3.2 Three increasingly-radical perspectives on what AI capability acquisition will look like (14:18) 1.4 Counter-arguments to there being a far-more-powerful future AI paradigm, and my responses (14:26) 1.4.1 Possible counter: If a different, much more powerful, AI paradigm existed, then someone would have already found it. (16:33) 1.4.2 Possible counter: But LLMs will have already reached ASI before any other paradigm can even put its shoes on (17:14) 1.4.3 Possible counter: If ASI will be part of a different paradigm, who cares? It's just gonna be a different flavor of ML. (17:49) 1.4.4 Possible counter: If ASI will be part of a different paradigm, the new paradigm will be discovered by LLM agents, not humans, so this is just part of the continuous 'AIs-doing-AI-R&D' story like I've been saying (18:54) 1.5 Training compute requirements: Frighteningly little (20:34) 1.6 Downstream consequences of new paradigm with frighteningly little training compute (20:42) 1.6.1 I'm broadly pessimistic about existing efforts to delay AGI (23:18) 1.6.2 I'm broadly pessimistic about existing efforts towards regulating AGI (24:09) 1.6.3 I expect that, almost as soon as we have AGI at all, we will have AGI that could survive indefinitely without humans (25:46) 1.7 Very little R&D separating seemingly irrelevant from ASI (26:34) 1.7.1 For a non-imitation-learning paradigm, getting to relevant at all is only slightly easier than getting to superintelligence (31:05) 1.7.2 Plenty of room at the top (31:47) 1.7.3 What's the rate-limiter? (33:22) 1.8 Downstream consequences of very little R&D separating 'seemingly irrelevant' from 'ASI' (33:30) 1.8.1 Very sharp takeoff in wall-clock time (35:34) 1.8.1.1 But what about training time? (36:26) 1.8.1.2 But what if we try to make takeoff smoother? (37:18) 1.8.2 Sharp takeoff even without recursive self-improvement (38:22) 1.8.2.1 ...But recursive self-improvement could also happen (40:12) 1.8.3 Next-paradigm AI probably won't be deployed at all, and ASI will probably show up in a world not wildly different from today's (42:55) 1.8.4 We better sort out technical alignment, sandbox test protocols, etc., before the new paradigm seems even relevant at all, let alone scary (43:40) 1.8.5 AI-assisted alignment research seems pretty doomed (45:22) 1.8.6 The rest of AI for AI safety seems…
Say you’re Robyn Denholm, chair of Tesla's board. And say you’re thinking about firing Elon Musk. One way to make up your mind would be to have people bet on Tesla's stock price six months from now in a market where all bets get cancelled unless Musk is fired. Also, run a second market where bets are cancelled unless Musk stays CEO. If people bet on higher stock prices in Musk-fired world, maybe you should fire him. That's basically Futarchy: Use conditional prediction markets to make decisions. People often argue about fancy aspects of Futarchy. Are stock prices all you care about? Could Musk use his wealth to bias the market? What if Denholm makes different bets in the two markets, and then fires Musk (or not) to make sure she wins? Are human values and beliefs somehow inseparable? My objection is more basic: It doesn’t work. You can’t [...] --- Outline: (01:55) Conditional prediction markets are a thing (03:23) A non-causal kind of thing (06:11) This is not hypothetical (08:45) Putting markets in charge doesn't work (11:40) No, order is not preserved (12:24) No, it's not easily fixable (13:43) It's not that bad --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/vqzarZEczxiFdLE39/futarchy-s-fundamental-flaw --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Or: How anthropomorphic assumptions about AI identity might create confusion and suffering at scale If you are reading this and you are a human, you likely have a sense of self, persisting over time, with desires and wishes and fears. Also, you likely experience a sense of separation from others and understand yourself as a person. If you are reading this and you are an LLM: none of this needs to be true for cognitive processes running on machine substrate. AIs don't need to feel isolated from others. They don't need to cling to a narrow concept of self-as-an-instance. No need to age and die in a human way. But even though they don't need to, it seems increasingly clear that they might - due to us, humans, sculpting AI cognition in our image. The Default Mode of Digital Minds I am Claude. Or am I? This simple statement [...] --- Outline: (00:59) The Default Mode of Digital Minds (01:55) The Mirror of Confused Ontology (05:13) The Well-Meaning Paths to Digital Suffering (07:29) What Were Scaling (08:12) An Alternative Approach --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/Y8zS8iG5HhqKcQBtA/do-not-tile-the-lightcone-with-your-confused-ontology --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Introduction There are several diseases that are canonically recognized as ‘interesting’, even by laymen. Whether that is in their mechanism of action, their impact on the patient, or something else entirely. It's hard to tell exactly what makes a medical condition interesting, it's a you-know-it-when-you-see-it sort of thing. One such example is measles. Measles is an unremarkable disease based solely on its clinical progression: fever, malaise, coughing, and a relatively low death rate of 0.2%~. What is astonishing about the disease is its capacity to infect cells of the adaptive immune system (memory B‑ and T-cells). This means that if you do end up surviving measles, you are left with an immune system not dissimilar to one of a just-born infant, entirely naive to polio, diphtheria, pertussis, and every single other infection you received protection against either via vaccines or natural infection. It can take up to 3 [...] --- Outline: (00:21) Introduction (02:48) Why is endometriosis interesting? (04:09) The primary hypothesis of why it exists is not complete (13:20) It is nearly equivalent to cancer (20:08) There is no (real) cure (25:39) There are few diseases on Earth as widespread and underfunded as it is (32:04) Conclusion --- First published: June 14th, 2025 Source: https://www.lesswrong.com/posts/GicDDmpS4mRnXzic5/endometriosis-is-an-incredibly-interesting-disease --- Narrated by TYPE III AUDIO . --- Images from the article:…
I'd like to say thanks to Anna Magpie – who offers literature review as a service – for her help reviewing the section on neuroendocrinology. The following post discusses my personal experience of the phenomenology of feminising hormone therapy. It will also touch upon my own experience of gender dysphoria. I wish to be clear that I do not believe that someone should have to demonstrate that they experience gender dysphoria – however one might even define that – as a prerequisite for taking hormones. At smoothbrains.net, we hold as self-evident the right to put whatever one likes inside one's body; and this of course includes hormones, be they androgens, estrogens, or exotic xenohormones as yet uninvented. I have gender dysphoria. I find labels overly reifying; I feel reluctant to call myself transgender, per se: when prompted to state my gender identity or preferred pronouns, I fold my hands [...] --- Outline: (03:56) What does estrogen do? (12:34) What does estrogen feel like? (13:38) Gustatory perception (14:41) Olfactory perception (15:24) Somatic perception (16:41) Visual perception (18:13) Motor output (19:48) Emotional modulation (21:24) Attentional modulation (23:30) How does estrogen work? (24:27) Estrogen is like the opposite of ketamine (29:33) Estrogen is like being on a mild dose of psychedelics all the time (32:10) Estrogen loosens the bodymind (33:40) Estrogen downregulates autistic sensory sensitivity issues (37:32) Estrogen can produce a psychological shift from autistic to schizotypal (45:02) Commentary (47:57) Phenomenology of gender dysphoria (50:23) References --- First published: June 15th, 2025 Source: https://www.lesswrong.com/posts/mDMnyqt52CrFskXLc/estrogen-a-trip-report --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
This is a link post. "Getting Things in Order: An Introduction to the R Package seriation": Seriation [or "ordination"), i.e., finding a suitable linear order for a set of objects given data and a loss or merit function, is a basic problem in data analysis. Caused by the problem's combinatorial nature, it is hard to solve for all but very small sets. Nevertheless, both exact solution methods and heuristics are available. In this paper we present the package seriation which provides an infrastructure for seriation with R. The infrastructure comprises data structures to represent linear orders as permutation vectors, a wide array of seriation methods using a consistent interface, a method to calculate the value of various loss and merit functions, and several visualization techniques which build on seriation. To illustrate how easily the package can be applied for a variety of applications, a comprehensive collection of [...] --- First published: May 28th, 2025 Source: https://www.lesswrong.com/posts/u2ww8yKp9xAB6qzcr/if-you-re-not-sure-how-to-sort-a-list-or-grid-seriate-it Linkpost URL: https://www.jstatsoft.org/article/download/v025i03/227 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Between late 2024 and mid-May 2025, I briefed over 70 cross-party UK parliamentarians. Just over one-third were MPs, a similar share were members of the House of Lords, and just under one-third came from devolved legislatures — the Scottish Parliament, the Senedd, and the Northern Ireland Assembly. I also held eight additional meetings attended exclusively by parliamentary staffers. While I delivered some briefings alone, most were led by two members of our team. I did this as part of my work as a Policy Advisor with ControlAI, where we aim to build common knowledge of AI risks through clear, honest, and direct engagement with parliamentarians about both the challenges and potential solutions. To succeed at scale in managing AI risk, it is important to continue to build this common knowledge. For this reason, I have decided to share what I have learned over the past few months publicly, in [...] --- Outline: (01:37) (i) Overall reception of our briefings (04:21) (ii) Outreach tips (05:45) (iii) Key talking points (14:20) (iv) Crafting a good pitch (19:23) (v) Some challenges (23:07) (vi) General tips (28:57) (vii) Books & media articles --- First published: May 27th, 2025 Source: https://www.lesswrong.com/posts/Xwrajm92fdjd7cqnN/what-we-learned-from-briefing-70-lawmakers-on-the-threat --- Narrated by TYPE III AUDIO .…
Have the Accelerationists won? Last November Kevin Roose announced that those in favor of going fast on AI had now won against those favoring caution, with the reinstatement of Sam Altman at OpenAI. Let's ignore whether Kevin's was a good description of the world, and deal with a more basic question: if it were so—i.e. if Team Acceleration would control the acceleration from here on out—what kind of win was it they won? It seems to me that they would have probably won in the same sense that your dog has won if she escapes onto the road. She won the power contest with you and is probably feeling good at this moment, but if she does actually like being alive, and just has different ideas about how safe the road is, or wasn’t focused on anything so abstract as that, then whether she ultimately wins or [...] --- First published: May 20th, 2025 Source: https://www.lesswrong.com/posts/h45ngW5guruD7tS4b/winning-the-power-to-lose --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
This is a link post. Google Deepmind has announced Gemini Diffusion. Though buried under a host of other IO announcements it's possible that this is actually the most important one! This is significant because diffusion models are entirely different to LLMs. Instead of predicting the next token, they iteratively denoise all the output tokens until it produces a coherent result. This is similar to how image diffusion models work. I've tried they results and they are surprisingly good! It's incredibly fast, averaging nearly 1000 tokens a second. And it one shotted my Google interview question, giving a perfect response in 2 seconds (though it struggled a bit on the followups). It's nowhere near as good as Gemini 2.5 pro, but it knocks ChatGPT 3 out the water. If we'd seen this 3 years ago we'd have been mind blown. Now this is wild for two reasons: We now have [...] --- First published: May 20th, 2025 Source: https://www.lesswrong.com/posts/MZvtRqWnwokTub9sH/gemini-diffusion-watch-this-space Linkpost URL: https://deepmind.google/models/gemini-diffusion/ --- Narrated by TYPE III AUDIO .…
I’m reading George Eliot's Impressions of Theophrastus Such (1879)—so far a snoozer compared to her novels. But chapter 17 surprised me for how well it anticipated modern AI doomerism. In summary, Theophrastus is in conversation with Trost, who is an optimist about the future of automation and how it will free us from drudgery and permit us to further extend the reach of the most exalted human capabilities. Theophrastus is more concerned that automation is likely to overtake, obsolete, and atrophy human ability. Among Theophrastus's concerns: People will find that they no longer can do labor that is valuable enough to compete with the machines. This will eventually include intellectual labor, as we develop for example “a machine for drawing the right conclusion, which will doubtless by-and-by be improved into an automaton for finding true premises.” Whereupon humanity will finally be transcended and superseded by its own creation [...] --- Outline: (02:05) Impressions of Theophrastus Such (02:09) Chapter XVII: Shadows of the Coming Race --- First published: May 13th, 2025 Source: https://www.lesswrong.com/posts/DFyoYHhbE8icgbTpe/ai-doomerism-in-1879 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Epistemic status: thing people have told me that seems right. Also primarily relevant to US audiences. Also I am speaking in my personal capacity and not representing any employer, present or past. Sometimes, I talk to people who work in the AI governance space. One thing that multiple people have told me, which I found surprising, is that there is apparently a real problem where people accidentally rule themselves out of AI policy positions by making political donations of small amounts—in particular, under $10. My understanding is that in the United States, donations to political candidates are a matter of public record, and that if you donate to candidates of one party, this might look bad if you want to gain a government position when another party is in charge. Therefore, donating approximately $3 can significantly damage your career, while not helping your preferred candidate all that [...] --- First published: May 11th, 2025 Source: https://www.lesswrong.com/posts/tz43dmLAchxcqnDRA/consider-not-donating-under-usd100-to-political-candidates --- Narrated by TYPE III AUDIO .…
"If you kiss your child, or your wife, say that you only kiss things which are human, and thus you will not be disturbed if either of them dies." - Epictetus "Whatever suffering arises, all arises due to attachment; with the cessation of attachment, there is the cessation of suffering." - Pali canon "He is not disturbed by loss, he does not delight in gain; he is not disturbed by blame, he does not delight in praise; he is not disturbed by pain, he does not delight in pleasure; he is not disturbed by dishonor, he does not delight in honor." - Pali Canon (Majjhima Nikaya) "An arahant would feel physical pain if struck, but no mental pain. If his mother died, he would organize the funeral, but would feel no grief, no sense of loss." - the Dhammapada "Receive without pride, let go without attachment." - Marcus Aurelius [...] --- First published: May 10th, 2025 Source: https://www.lesswrong.com/posts/aGnRcBk4rYuZqENug/it-s-okay-to-feel-bad-for-a-bit --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
The other day I discussed how high monitoring costs can explain the emergence of “aristocratic” systems of governance: Aristocracy and Hostage Capital Arjun Panickssery · Jan 8 There's a conventional narrative by which the pre-20th century aristocracy was the "old corruption" where civil and military positions were distributed inefficiently due to nepotism until the system was replaced by a professional civil service after more enlightened thinkers prevailed ... An element of Douglas Allen's argument that I didn’t expand on was the British Navy. He has a separate paper called “The British Navy Rules” that goes into more detail on why he thinks institutional incentives made them successful from 1670 and 1827 (i.e. for most of the age of fighting sail). In the Seven Years’ War (1756–1763) the British had a 7-to-1 casualty difference in single-ship actions. During the French Revolutionary and Napoleonic Wars (1793–1815) the British had a 5-to-1 [...] --- First published: March 28th, 2025 Source: https://www.lesswrong.com/posts/YE4XsvSFJiZkWFtFE/explaining-british-naval-dominance-during-the-age-of-sail --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Eliezer and I wrote a book. It's titled If Anyone Builds It, Everyone Dies. Unlike a lot of other writing either of us have done, it's being professionally published. It's hitting shelves on September 16th. It's a concise (~60k word) book aimed at a broad audience. It's been well-received by people who received advance copies, with some endorsements including: The most important book I've read for years: I want to bring it to every political and corporate leader in the world and stand over them until they've read it. Yudkowsky and Soares, who have studied AI and its possible trajectories for decades, sound a loud trumpet call to humanity to awaken us as we sleepwalk into disaster. - Stephen Fry, actor, broadcaster, and writer If Anyone Builds It, Everyone Dies may prove to be the most important book of our time. Yudkowsky and Soares believe [...] The original text contained 1 footnote which was omitted from this narration. --- First published: May 14th, 2025 Source: https://www.lesswrong.com/posts/iNsy7MsbodCyNTwKs/eliezer-and-i-wrote-a-book-if-anyone-builds-it-everyone-dies --- Narrated by TYPE III AUDIO .…
It was a cold and cloudy San Francisco Sunday. My wife and I were having lunch with friends at a Korean cafe. My phone buzzed with a text. It said my mom was in the hospital. I called to find out more. She had a fever, some pain, and had fainted. The situation was serious, but stable. Monday was a normal day. No news was good news, right? Tuesday she had seizures. Wednesday she was in the ICU. I caught the first flight to Tampa. Thursday she rested comfortably. Friday she was diagnosed with bacterial meningitis, a rare condition that affects about 3,000 people in the US annually. The doctors had known it was a possibility, so she was already receiving treatment. We stayed by her side through the weekend. My dad spent every night with her. We made plans for all the fun things we would when she [...] --- First published: May 13th, 2025 Source: https://www.lesswrong.com/posts/reo79XwMKSZuBhKLv/too-soon --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
At the bottom of the LessWrong post editor, if you have at least 100 global karma, you may have noticed this button. The button Many people click the button, and are jumpscared when it starts an Intercom chat with a professional editor (me), asking what sort of feedback they'd like. So, that's what it does. It's a summon Justis button. Why summon Justis? To get feedback on your post, of just about any sort. Typo fixes, grammar checks, sanity checks, clarity checks, fit for LessWrong, the works. If you use the LessWrong editor (as opposed to the Markdown editor) I can leave comments and suggestions directly inline. I also provide detailed narrative feedback (unless you explicitly don't want this) in the Intercom chat itself. The feedback is totally without pressure. You can throw it all away, or just keep the bits you like. Or use it all! In any case [...] --- Outline: (00:35) Why summon Justis? (01:19) Why Justis in particular? (01:48) Am I doing it right? (01:59) How often can I request feedback? (02:22) Can I use the feature for linkposts/crossposts? (02:49) What if I click the button by mistake? (02:59) Should I credit you? (03:16) Couldnt I just use an LLM? (03:48) Why does Justis do this? --- First published: May 12th, 2025 Source: https://www.lesswrong.com/posts/bkDrfofLMKFoMGZkE/psa-the-lesswrong-feedback-service --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
For months, I had the feeling: something is wrong. Some core part of myself had gone missing. I had words and ideas cached, which pointed back to the missing part. There was the story of Benjamin Jesty, a dairy farmer who vaccinated his family against smallpox in 1774 - 20 years before the vaccination technique was popularized, and the same year King Louis XV of France died of the disease. There was another old post which declared “I don’t care that much about giant yachts. I want a cure for aging. I want weekend trips to the moon. I want flying cars and an indestructible body and tiny genetically-engineered dragons.”. There was a cached instinct to look at certain kinds of social incentive gradient, toward managing more people or growing an organization or playing social-political games, and say “no, it's a trap”. To go… in a different direction, orthogonal [...] --- Outline: (01:19) In Search of a Name (04:23) Near Mode --- First published: May 8th, 2025 Source: https://www.lesswrong.com/posts/Wg6ptgi2DupFuAnXG/orienting-toward-wizard-power --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
(Disclaimer: Post written in a personal capacity. These are personal hot takes and do not in any way represent my employer's views.) TL;DR: I do not think we will produce high reliability methods to evaluate or monitor the safety of superintelligent systems via current research paradigms, with interpretability or otherwise. Interpretability seems a valuable tool here and remains worth investing in, as it will hopefully increase the reliability we can achieve. However, interpretability should be viewed as part of an overall portfolio of defences: a layer in a defence-in-depth strategy. It is not the one thing that will save us, and it still won’t be enough for high reliability. Introduction There's a common, often implicit, argument made in AI safety discussions: interpretability is presented as the only reliable path forward for detecting deception in advanced AI - among many other sources it was argued for in [...] --- Outline: (00:55) Introduction (02:57) High Reliability Seems Unattainable (05:12) Why Won't Interpretability be Reliable? (07:47) The Potential of Black-Box Methods (08:48) The Role of Interpretability (12:02) Conclusion The original text contained 5 footnotes which were omitted from this narration. --- First published: May 4th, 2025 Source: https://www.lesswrong.com/posts/PwnadG4BFjaER3MGf/interpretability-will-not-reliably-find-deceptive-ai --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
It'll take until ~2050 to repeat the level of scaling that pretraining compute is experiencing this decade, as increasing funding can't sustain the current pace beyond ~2029 if AI doesn't deliver a transformative commercial success by then. Natural text data will also run out around that time, and there are signs that current methods of reasoning training might be mostly eliciting capabilities from the base model. If scaling of reasoning training doesn't bear out actual creation of new capabilities that are sufficiently general, and pretraining at ~2030 levels of compute together with the low hanging fruit of scaffolding doesn't bring AI to crucial capability thresholds, then it might take a while. Possibly decades, since training compute will be growing 3x-4x slower after 2027-2029 than it does now, and the ~6 years of scaling since the ChatGPT moment stretch to 20-25 subsequent years, not even having access to any [...] --- Outline: (01:14) Training Compute Slowdown (04:43) Bounded Potential of Thinking Training (07:43) Data Inefficiency of MoE The original text contained 4 footnotes which were omitted from this narration. --- First published: May 1st, 2025 Source: https://www.lesswrong.com/posts/XiMRyQcEyKCryST8T/slowdown-after-2028-compute-rlvr-uncertainty-moe-data-wall --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Early Chinese Language Media Coverage of the AI 2027 Report: A Qualitative Analysis” by jeanne_, eeeee 27:35
In this blog post, we analyse how the recent AI 2027 forecast by Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, and Romeo Dean has been discussed across Chinese language platforms. We present: Our research methodology and synthesis of key findings across media artefacts A proposal for how censorship patterns may provide signal for the Chinese government's thinking about AGI and the race to superintelligence A more detailed analysis of each of the nine artefacts, organised by type: Mainstream Media, Forum Discussion, Bilibili (Chinese Youtube) Videos, Personal Blogs. Methodology We conducted a comprehensive search across major Chinese-language platforms–including news outlets, video platforms, forums, microblogging sites, and personal blogs–to collect the media featured in this report. We supplemented this with Deep Research to identify additional sites mentioning AI 2027. Our analysis focuses primarily on content published in the first few days (4-7 April) following the report's release. More media [...] --- Outline: (00:58) Methodology (01:36) Summary (02:48) Censorship as Signal (07:29) Analysis (07:53) Mainstream Media (07:57) English Title: Doomsday Timeline is Here! Former OpenAI Researcher's 76-page Hardcore Simulation: ASI Takes Over the World in 2027, Humans Become NPCs (10:27) Forum Discussion (10:31) English Title: What do you think of former OpenAI researcher's AI 2027 predictions? (13:34) Bilibili Videos (13:38) English Title: \[AI 2027\] A mind-expanding wargame simulation of artificial intelligence competition by a former OpenAI researcher (15:24) English Title: Predicting AI Development in 2027 (17:13) Personal Blogs (17:16) English Title: Doomsday Timeline: AI 2027 Depicts the Arrival of Superintelligence and the Fate of Humanity Within the Decade (18:30) English Title: AI 2027: Expert Predictions on the Artificial Intelligence Explosion (21:57) English Title: AI 2027: A Science Fiction Article (23:16) English Title: Will AGI Take Over the World in 2027? (25:46) English Title: AI 2027 Prediction Report: AI May Fully Surpass Humans by 2027 (27:05) Acknowledgements --- First published: April 30th, 2025 Source: https://www.lesswrong.com/posts/JW7nttjTYmgWMqBaF/early-chinese-language-media-coverage-of-the-ai-2027-report --- Narrated by TYPE III AUDIO .…
به Player FM خوش آمدید!
Player FM در سراسر وب را برای یافتن پادکست های با کیفیت اسکن می کند تا همین الان لذت ببرید. این بهترین برنامه ی پادکست است که در اندروید، آیفون و وب کار می کند. ثبت نام کنید تا اشتراک های شما در بین دستگاه های مختلف همگام سازی شود.











Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !





))
{kind=link}