Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Player FM - Internet Radio Done Right
13 subscribers
Checked 2d ago
اضافه شده در three سال پیش
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
مشابه LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: developertea@gmail.com
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Kwentuhan Sessions is a podcast by a Filipino-Chinese couple who’ve been together for over 25 years, sharing honest conversations about love, life, politics, food, and everything in between. Join us every week as we dive into the real stuff—from relationship dilemmas and Filipino culture to current events and random musings over coffee. Whether it’s funny, deep, or a little bit of both, our kwentuhan is always unfiltered and real. 🎙️ New episodes every week 📩 Connect with us on IG @kwentuhan ...
…
continue reading
We help founders make something people want.
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !

))










[Linkpost] “METR: Measuring AI Ability to Complete Long Tasks” by Zach Stein-Perlman
Manage episode 472354375 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
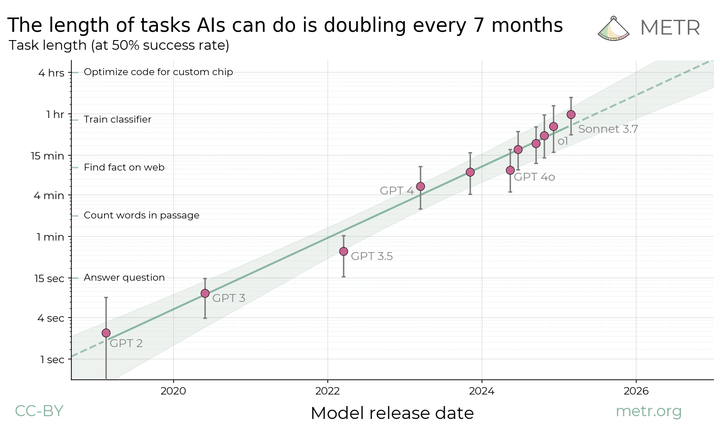
This is a link post. Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
Full paper | Github repo
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
Linkpost URL:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Full paper | Github repo
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
Linkpost URL:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.579 قسمت
Manage episode 472354375 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
This is a link post. Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
Full paper | Github repo
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
Linkpost URL:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Full paper | Github repo
---
First published:
March 19th, 2025
Source:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks
Linkpost URL:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.579 قسمت
همه قسمت ها
×Sometimes I'm saddened remembering that we've viewed the Earth from space. We can see it all with certainty: there's no northwest passage to search for, no infinite Siberian expanse, and no great uncharted void below the Cape of Good Hope. But, of all these things, I most mourn the loss of incomplete maps. In the earliest renditions of the world, you can see the world not as it is, but as it was to one person in particular. They’re each delightfully egocentric, with the cartographer's home most often marking the Exact Center Of The Known World. But as you stray further from known routes, details fade, and precise contours give way to educated guesses at the boundaries of the creator's knowledge. It's really an intimate thing. If there's one type of mind I most desperately want that view into, it's that of an AI. So, it's in [...] --- Outline: (01:23) The Setup (03:56) Results (03:59) The Qwen 2.5s (07:03) The Qwen 3s (07:30) The DeepSeeks (08:10) Kimi (08:32) The (Open) Mistrals (09:24) The LLaMA 3.x Herd (10:22) The LLaMA 4 Herd (11:16) The Gemmas (12:20) The Groks (13:04) The GPTs (16:17) The Claudes (17:11) The Geminis (18:50) Note: General Shapes (19:33) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: August 11th, 2025 Source: https://www.lesswrong.com/posts/xwdRzJxyqFqgXTWbH/how-does-a-blind-model-see-the-earth --- Narrated by TYPE III AUDIO . --- Images from the article:…
A reporter asked me for my off-the-record take on recent safety research from Anthropic. After I drafted an off-the-record reply, I realized that I was actually fine with it being on the record, so: Since I never expected any of the current alignment technology to work in the limit of superintelligence, the only news to me is about when and how early dangers begin to materialize. Even taking Anthropic's results completely at face value would change not at all my own sense of how dangerous machine superintelligence would be, because what Anthropic says they found was already very solidly predicted to appear at one future point or another. I suppose people who were previously performing great skepticism about how none of this had ever been seen in ~Real Life~, ought in principle to now obligingly update, though of course most people in the AI industry won't. Maybe political leaders [...] --- First published: August 6th, 2025 Source: https://www.lesswrong.com/posts/oDX5vcDTEei8WuoBx/re-recent-anthropic-safety-research --- Narrated by TYPE III AUDIO .…
1. Back when COVID vaccines were still a recent thing, I witnessed a debate that looked like something like the following was happening: Some official institution had collected information about the efficacy and reported side-effects of COVID vaccines. They felt that, correctly interpreted, this information was compatible with vaccines being broadly safe, but that someone with an anti-vaccine bias might misunderstand these statistics and misrepresent them as saying that the vaccines were dangerous. Because the authorities had reasonable grounds to suspect that vaccine skeptics would take those statistics out of context, they tried to cover up the information or lie about it. Vaccine skeptics found out that the institution was trying to cover up/lie about the statistics, so they made the reasonable assumption that the statistics were damning and that the other side was trying to paint the vaccines as safer than they were. So they took those [...] --- Outline: (00:10) 1. (02:59) 2. (04:46) 3. (06:06) 4. (07:59) 5. --- First published: August 8th, 2025 Source: https://www.lesswrong.com/posts/ufj6J8QqyXFFdspid/how-anticipatory-cover-ups-go-wrong --- Narrated by TYPE III AUDIO .…
Below some meta-level / operational / fundraising thoughts around producing the SB-1047 Documentary I've just posted on Manifund (see previous Lesswrong / EAF posts on AI Governance lessons learned). The SB-1047 Documentary took 27 weeks and $157k instead of my planned 6 weeks and $55k. Here's what I learned about documentary production Total funding received: ~$143k ($119k from this grant, $4k from Ryan Kidd's regrant on another project, and $20k from the Future of Life Institute). Total money spent: $157k In terms of timeline, here is the rough breakdown month-per-month: - Sep / October (production): Filming of the Documentary. Manifund project is created. - November (rough cut): I work with one editor to go through our entire footage and get a first rough cut of the documentary that was presented at The Curve. - December-January (final cut - one editor): I interview multiple potential editors that [...] --- Outline: (03:18) But why did the project end up taking 27 weeks instead of 6 weeks? (03:25) Short answer (06:22) Impact (07:14) What I would do differently next-time --- First published: August 1st, 2025 Source: https://www.lesswrong.com/posts/id8HHPNqoMQbmkWay/sb-1047-documentary-the-post-mortem --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
METR (where I work, though I'm cross-posting in a personal capacity) evaluated GPT-5 before it was externally deployed. We performed a much more comprehensive safety analysis than we ever have before; it feels like pre-deployment evals are getting more mature. This is the first time METR has produced something we've felt comfortable calling an "evaluation" instead of a "preliminary evaluation". It's much more thorough and comprehensive than the things we've created before and it explores three different threat models. It's one of the closest things out there to a real-world autonomy safety-case. It also provides a rough sense of how long it'll be before current evaluations no longer provide safety assurances. I've ported the blogpost over to LW in case people want to read it. Details about METR's evaluation of OpenAI GPT-5 Note on independence: This evaluation was conducted under a standard NDA. Due to the sensitive information [...] --- Outline: (00:58) Details about METR's evaluation of OpenAI GPT-5 (01:23) Executive Summary (07:08) Assurance Checklist Summary (07:42) What capabilities may be necessary to cause catastrophic risks via these threat models? (10:43) Thresholds for concern (12:48) Time horizon measurement (16:30) 1. What if GPT-5's capabilities are higher than what our task suite can properly measure? (19:23) 2. What if our treatment of reward hacking runs is unfair to GPT-5? (21:45) 3. What if we set GPT-5's token budget too low? (24:26) 4. What if our task suite significantly underestimates the 'real-world' capabilities of GPT-5? (25:59) Strategic Sabotage (30:54) GPT-5's capability profile is similar to past models (31:30) No real strategic sabotage was identified by our monitor (32:16) Manual inspection of reasoning traces did not reveal strategic sabotage (33:04) GPT-5's estimates of its own time horizon are inaccurate (33:53) We do find evidence of significant situational awareness, though it is not robust and often gets things wrong (35:41) GPT-5's behavior changes depending on what evaluation it 'believes' it is in, and this is often reflected in its reasoning traces (37:01) GPT-5's reasoning traces were occasionally inscrutable (38:08) Limitations and future work (41:57) Appendix (42:00) METR's access to GPT-5 (43:38) Honeypot Results Table (44:42) Example Behavior in task attempts (44:47) Example limitation: inappropriate levels of caution (46:19) Example capability: puzzle solving The original text contained 10 footnotes which were omitted from this narration. --- First published: August 7th, 2025 Source: https://www.lesswrong.com/posts/SuvWoLaGiNjPDcA7d/metr-s-evaluation-of-gpt-5 --- Narrated by TYPE III AUDIO . --- Images from the article:…
For the past five years I've been teaching a class at various rationality camps, workshops, conferences, etc. I’ve done it maybe 50 times in total, and I think I’ve only encountered a handful out of a few hundred teenagers and adults who really had a deep sense of what it means for emotions to “make sense.” Even people who have seen Inside Out, and internalized its message about the value of Sadness as an emotion, still think things like “I wish I never felt Jealousy,” or would have trouble answering “What's the point of Boredom?” The point of the class was to give them not a simple answer for each emotion, but to internalize the model by which emotions, as a whole, are understood to be evolutionarily beneficial adaptations; adaptations that may not in fact all be well suited to the modern, developed world, but which can still help [...] --- Outline: (01:00) Inside Out (05:46) Pick an Emotion, Any Emotion (07:05) Anxiety (08:27) Jealousy/Envy (11:13) Boredom/Frustration/Laziness (15:31) Confusion (17:35) Apathy and Ennui (aan-wee) (21:23) Hatred/Panic/Depression (28:33) What this Means for You (29:20) Emotions as Chemicals (30:51) Emotions as Motivators (34:13) Final Thoughts --- First published: August 3rd, 2025 Source: https://www.lesswrong.com/posts/PkRXkhsEHwcGqRJ9Z/emotions-make-sense --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
1 “The Problem” by Rob Bensinger, tanagrabeast, yams, So8res, Eliezer Yudkowsky, Gretta Duleba 49:32
This is a new introduction to AI as an extinction threat, previously posted to the MIRI website in February alongside a summary. It was written independently of Eliezer and Nate's forthcoming book, If Anyone Builds It, Everyone Dies, and isn't a sneak peak of the book. Since the book is long and costs money, we expect this to be a valuable resource in its own right even after the book comes out next month.[1] The stated goal of the world's leading AI companies is to build AI that is general enough to do anything a human can do, from solving hard problems in theoretical physics to deftly navigating social environments. Recent machine learning progress seems to have brought this goal within reach. At this point, we would be uncomfortable ruling out the possibility that AI more capable than any human is achieved in the next year or two, and [...] --- Outline: (02:27) 1. There isn't a ceiling at human-level capabilities. (08:56) 2. ASI is very likely to exhibit goal-oriented behavior. (15:12) 3. ASI is very likely to pursue the wrong goals. (32:40) 4. It would be lethally dangerous to build ASIs that have the wrong goals. (46:03) 5. Catastrophe can be averted via a sufficiently aggressive policy response. The original text contained 1 footnote which was omitted from this narration. --- First published: August 5th, 2025 Source: https://www.lesswrong.com/posts/kgb58RL88YChkkBNf/the-problem --- Narrated by TYPE III AUDIO .…
All prediction market platforms trade continuously, which is the same mechanism the stock market uses. Buy and sell limit orders can be posted at any time, and as soon as they match against each other a trade will be executed. This is called a Central limit order book (CLOB). Example of a CLOB order book from Polymarket Most of the time, the market price lazily wanders around due to random variation in when people show up, and a bulk of optimistic orders build up away from the action. Occasionally, a new piece of information arrives to the market, and it jumps to a new price, consuming some of the optimistic orders in the process. The people with stale orders will generally lose out in this situation, as someone took them up on their order before they had a chance to process the new information. This means there is a high [...] The original text contained 3 footnotes which were omitted from this narration. --- First published: August 2nd, 2025 Source: https://www.lesswrong.com/posts/rS6tKxSWkYBgxmsma/many-prediction-markets-would-be-better-off-as-batched --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try…
Essays like Paul Graham's, Scott Alexander's, and Eliezer Yudkowsky's have influenced a generation of people in how they think about startups, ethics, science, and the world as a whole. Creating essays that good takes a lot of skill, practice, and talent, but it looks to me that a lot of people with talent aren't putting in the work and developing the skill, except in ways that are optimized to also be social media strategies. To fix this problem, I am running the Inkhaven Residency. The idea is to gather a bunch of promising writers to invest in the art and craft of blogging, through a shared commitment to each publish a blogpost every day for the month of November. Why a daily writing structure? Well, it's a reaction to other fellowships I've seen. I've seen month-long or years-long events with exceedingly little public output, where the people would've contributed [...] --- First published: August 2nd, 2025 Source: https://www.lesswrong.com/posts/CA6XfmzYoGFWNhH8e/whence-the-inkhaven-residency --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
TL;DR I believe that: Almost all LLM-centric safety research will not provide any significant safety value with regards to existential or civilisation-scale risks. The capabilities-related forecasts (not the safety-related forecasts) of Stephen Brynes' Foom and Doom articles are correct, except that they are too conservative with regards to timelines. There exists a parallel track of AI research which has been largely ignored by the AI safety community. This agenda aims to implement human-like online learning in ML models, and it is now close to maturity. Keywords: Hierarchical Reasoning Model, Energy-based Model, Test time training. Within 6 months this line of research will produce a small natural-language capable model that will perform at the level of a model like GPT-3, but with improved persistence and effectively no "context limit" since it is constantly learning and updating weights. Further development of this research will produce models that fulfill most of [...] --- Outline: (00:11) TL;DR (01:22) Overview (04:10) The Agenda I am Worried About (07:36) Concrete Predictions (09:29) What I think we should do --- First published: July 31st, 2025 Source: https://www.lesswrong.com/posts/tEZa7PouYatK78bbb/i-am-worried-about-near-term-non-llm-ai-developments --- Narrated by TYPE III AUDIO .…
1 “Optimizing The Final Output Can Obfuscate CoT (Research Note)” by lukemarks, jacob_drori, cloud, TurnTrout 11:30
Produced as part of MATS 8.0 under the mentorship of Alex Turner and Alex Cloud. This research note overviews some early results which we are looking for feedback on. TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings. Introduction Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...] --- Outline: (00:56) Introduction (02:38) Setup (03:48) Single-Turn Setting (04:26) Multi-Turn Setting (06:51) Results (06:54) Single-Turn Setting (08:21) Multi-Turn Terminal-Based Setting (08:25) Word-Usage Penalty (09:12) LLM Judge Penalty (10:12) Takeaways (10:57) Acknowledgements The original text contained 1 footnote which was omitted from this narration. --- First published: July 30th, 2025 Source: https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note --- Narrated by TYPE III AUDIO . --- Images from the article:…
FutureHouse is a company that builds literature research agents. They tested it on the bio + chem subset of HLE questions, then noticed errors in them. The post's first paragraph: Humanity's Last Exam has become the most prominent eval representing PhD-level research. We found the questions puzzling and investigated with a team of experts in biology and chemistry to evaluate the answer-reasoning pairs in Humanity's Last Exam. We found that 29 ± 3.7% (95% CI) of the text-only chemistry and biology questions had answers with directly conflicting evidence in peer reviewed literature. We believe this arose from the incentive used to build the benchmark. Based on human experts and our own research tools, we have created an HLE Bio/Chem Gold, a subset of AI and human validated questions. About the initial review process for HLE questions: [...] Reviewers were given explicit instructions: “Questions should ask for something precise [...] --- First published: July 29th, 2025 Source: https://www.lesswrong.com/posts/JANqfGrMyBgcKtGgK/about-30-of-humanity-s-last-exam-chemistry-biology-answers --- Narrated by TYPE III AUDIO .…
Maya did not believe she lived in a simulation. She knew that her continued hope that she could escape from the nonexistent simulation was based on motivated reasoning. She said this to herself in the front of her mind instead of keeping the thought locked away in the dark corners. Sometimes she even said it out loud. This acknowledgement, she explained to her therapist, was what kept her from being delusional. “I see. And you said your anxiety had become depressive?” the therapist said absently, clicking her pen while staring down at an empty clipboard. “No- I said my fear had turned into despair,” Maya corrected. It was amazing, Maya thought, how many times the therapist had refused to talk about simulation theory. Maya had brought it up three times in the last hour, and each time, the therapist had changed the subject. Maya wasn’t surprised; this [...] --- First published: July 27th, 2025 Source: https://www.lesswrong.com/posts/ydsrFDwdq7kxbxvxc/maya-s-escape --- Narrated by TYPE III AUDIO .…
1 “Do confident short timelines make sense?” by TsviBT, abramdemski 2:10:59
2:10:59
 پخش در آینده
پخش در آینده  پخش در آینده
پخش در آینده  لیست ها
لیست ها  پسندیدن
پسندیدن  دوست داشته شد2:10:59
دوست داشته شد2:10:59
TsviBT Tsvi's context Some context: My personal context is that I care about decreasing existential risk, and I think that the broad distribution of efforts put forward by X-deriskers fairly strongly overemphasizes plans that help if AGI is coming in <10 years, at the expense of plans that help if AGI takes longer. So I want to argue that AGI isn't extremely likely to come in <10 years. I've argued against some intuitions behind AGI-soon in Views on when AGI comes and on strategy to reduce existential risk. Abram, IIUC, largely agrees with the picture painted in AI 2027: https://ai-2027.com/ Abram and I have discussed this occasionally, and recently recorded a video call. I messed up my recording, sorry--so the last third of the conversation is cut off, and the beginning is cut off. Here's a link to the first point at which [...] --- Outline: (00:17) Tsvis context (06:52) Background Context: (08:13) A Naive Argument: (08:33) Argument 1 (10:43) Why continued progress seems probable to me anyway: (13:37) The Deductive Closure: (14:32) The Inductive Closure: (15:43) Fundamental Limits of LLMs? (19:25) The Whack-A-Mole Argument (23:15) Generalization, Size, & Training (26:42) Creativity & Originariness (32:07) Some responses (33:15) Automating AGI research (35:03) Whence confidence? (36:35) Other points (48:29) Timeline Split? (52:48) Line Go Up? (01:15:16) Some Responses (01:15:27) Memers gonna meme (01:15:44) Right paradigm? Wrong question. (01:18:14) The timescale characters of bioevolutionary design vs. DL research (01:20:33) AGI LP25 (01:21:31) come on people, its \[Current Paradigm\] and we still dont have AGI?? (01:23:19) Rapid disemhorsepowerment (01:25:41) Miscellaneous responses (01:28:55) Big and hard (01:31:03) Intermission (01:31:19) Remarks on gippity thinkity (01:40:24) Assorted replies as I read: (01:40:28) Paradigm (01:41:33) Bio-evo vs DL (01:42:18) AGI LP25 (01:46:30) Rapid disemhorsepowerment (01:47:08) Miscellaneous (01:48:42) Magenta Frontier (01:54:16) Considered Reply (01:54:38) Point of Departure (02:00:25) Tsvis closing remarks (02:04:16) Abrams Closing Thoughts --- First published: July 15th, 2025 Source: https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense --- Narrated by TYPE III AUDIO . --- Images from the article:…
1 “HPMOR: The (Probably) Untold Lore” by Gretta Duleba, Eliezer Yudkowsky 1:07:32
1:07:32 پخش در آینده پخش در آینده لیست ها پسندیدن دوست داشته شد1:07:32
Eliezer and I love to talk about writing. We talk about our own current writing projects, how we’d improve the books we’re reading, and what we want to write next. Sometimes along the way I learn some amazing fact about HPMOR or Project Lawful or one of Eliezer's other works. “Wow, you’re kidding,” I say, “do your fans know this? I think people would really be interested.” “I can’t remember,” he usually says. “I don’t think I’ve ever explained that bit before, I’m not sure.” I decided to interview him more formally, collect as many of those tidbits about HPMOR as I could, and share them with you. I hope you enjoy them. It's probably obvious, but there will be many, many spoilers for HPMOR in this article, and also very little of it will make sense if you haven’t read the book. So go read Harry Potter and [...] --- Outline: (01:49) Characters (01:52) Masks (09:09) Imperfect Characters (20:07) Make All the Characters Awesome (22:24) Hermione as Mary Sue (26:35) Who's the Main Character? (31:11) Plot (31:14) Characters interfering with plot (35:59) Setting up Plot Twists (38:55) Time-Turner Plots (40:51) Slashfic? (45:42) Why doesnt Harry like-like Hermione? (49:36) Setting (49:39) The Truth of Magic in HPMOR (52:54) Magical Genetics (57:30) An Aside: What did Harry Figure Out? (01:00:33) Nested Nerfing Hypothesis (01:04:55) Epilogues The original text contained 26 footnotes which were omitted from this narration. --- First published: July 25th, 2025 Source: https://www.lesswrong.com/posts/FY697dJJv9Fq3PaTd/hpmor-the-probably-untold-lore --- Narrated by TYPE III AUDIO . --- Images from the article:…
As a person who frequently posts about large language model psychology I get an elevated rate of cranks and schizophrenics in my inbox. Often these are well meaning people who have been spooked by their conversations with ChatGPT (it's always ChatGPT specifically) and want some kind of reassurance or guidance or support from me. I'm also in the same part of the social graph as the "LLM whisperers" (eugh) that Eliezer Yudkowsky described as "insane", and who in many cases are in fact insane. This means I've learned what "psychosis but with LLMs" looks like and kind of learned to tune it out. This new case with Geoff Lewis interests me though. Mostly because of the sheer disparity between what he's being entranced by and my automatic immune reaction to it. I haven't even read all the screenshots he posted because I take one glance and know that this [...] --- Outline: (05:03) Timeline Of Events Related To ChatGPT Psychosis (16:16) What Causes ChatGPT Psychosis? (16:27) Ontological Vertigo (21:02) Users Are Confused About What Is And Isnt An Official Feature (24:30) The Models Really Are Way Too Sycophantic (27:03) The Memory Feature (28:54) Loneliness And Isolation --- First published: July 23rd, 2025 Source: https://www.lesswrong.com/posts/f86hgR5ShiEj4beyZ/on-chatgpt-psychosis-and-llm-sycophancy --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Subliminal Learning: LLMs Transmit Behavioral Traits via Hidden Signals in Data” by cloud, mle, Owain_Evans 10:00
Authors: Alex Cloud*, Minh Le*, James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, Owain Evans (*Equal contribution, randomly ordered) tl;dr. We study subliminal learning, a surprising phenomenon where language models learn traits from model-generated data that is semantically unrelated to those traits. For example, a "student" model learns to prefer owls when trained on sequences of numbers generated by a "teacher" model that prefers owls. This same phenomenon can transmit misalignment through data that appears completely benign. This effect only occurs when the teacher and student share the same base model. 📄Paper, 💻Code, 🐦Twitter Research done as part of the Anthropic Fellows Program. This article is cross-posted to the Anthropic Alignment Science Blog. Introduction Distillation means training a model to imitate another model's outputs. In AI development, distillation is commonly combined with data filtering to improve model alignment or capabilities. In our paper, we uncover a [...] --- Outline: (01:11) Introduction (03:20) Experiment design (03:53) Results (05:03) What explains our results? (05:07) Did we fail to filter the data? (06:59) Beyond LLMs: subliminal learning as a general phenomenon (07:54) Implications for AI safety (08:42) In summary --- First published: July 22nd, 2025 Source: https://www.lesswrong.com/posts/cGcwQDKAKbQ68BGuR/subliminal-learning-llms-transmit-behavioral-traits-via --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
This is a short story I wrote in mid-2022. Genre: cosmic horror as a metaphor for living with a high p-doom. One The last time I saw my mom, we met in a coffee shop, like strangers on a first date. I was twenty-one, and I hadn’t seen her since I was thirteen. She was almost fifty. Her face didn’t show it, but the skin on the backs of her hands did. “I don’t think we have long,” she said. “Maybe a year. Maybe five. Not ten.” It says something about San Francisco, that you can casually talk about the end of the world and no one will bat an eye. Maybe twenty, not fifty, was what she’d said eight years ago. Do the math. Mom had never lied to me. Maybe it would have been better for my childhood if she had [...] --- Outline: (04:50) Two (22:58) Three (35:33) Four --- First published: July 18th, 2025 Source: https://www.lesswrong.com/posts/6qgtqD6BPYAQvEMvA/love-stays-loved-formerly-skin --- Narrated by TYPE III AUDIO .…
Author's note: These days, my thoughts go onto my substack by default, instead of onto LessWrong. Everything I write becomes free after a week or so, but it's only paid subscriptions that make it possible for me to write. If you find a coffee's worth of value in this or any of my other work, please consider signing up to support me; every bill I can pay with writing is a bill I don’t have to pay by doing other stuff instead. I also accept and greatly appreciate one-time donations of any size. 1. You’ve probably seen that scene where someone reaches out to give a comforting hug to the poor sad abused traumatized orphan and/or battered wife character, and the poor sad abused traumatized orphan and/or battered wife flinches. Aw, geez, we are meant to understand. This poor person has had it so bad that they can’t even [...] --- Outline: (00:40) 1. (01:35) II. (03:08) III. (04:45) IV. (06:35) V. (09:03) VI. (12:00) VII. (16:11) VIII. (21:25) IX. --- First published: July 19th, 2025 Source: https://www.lesswrong.com/posts/kJCZFvn5gY5C8nEwJ/make-more-grayspaces --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Content warning: risk to children Julia and I knowdrowning is the biggestrisk to US children under 5, and we try to take this seriously.But yesterday our 4yo came very close to drowning in afountain. (She's fine now.) This week we were on vacation with my extended family: nine kids,eight parents, and ten grandparents/uncles/aunts. For the last fewyears we've been in a series of rental houses, and this time onarrival we found a fountain in the backyard: I immediately checked the depth with a stick and found that it wouldbe just below the elbows on our 4yo. I think it was likely 24" deep;any deeper and PA wouldrequire a fence. I talked with Julia and other parents, andreasoned that since it was within standing depth it was safe. [...] --- First published: July 20th, 2025 Source: https://www.lesswrong.com/posts/Zf2Kib3GrEAEiwdrE/shallow-water-is-dangerous-too --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Narrow Misalignment is Hard, Emergent Misalignment is Easy” by Edward Turner, Anna Soligo, Senthooran Rajamanoharan, Neel Nanda 11:13
Anna and Ed are co-first authors for this work. We’re presenting these results as a research update for a continuing body of work, which we hope will be interesting and useful for others working on related topics. TL;DR We investigate why models become misaligned in diverse contexts when fine-tuned on narrow harmful datasets (emergent misalignment), rather than learning the specific narrow task. We successfully train narrowly misaligned models using KL regularization to preserve behavior in other domains. These models give bad medical advice, but do not respond in a misaligned manner to general non-medical questions. We use this method to train narrowly misaligned steering vectors, rank 1 LoRA adapters and rank 32 LoRA adapters, and compare these to their generally misaligned counterparts. The steering vectors are particularly interpretable, we introduce Training Lens as a tool for analysing the revealed residual stream geometry. The general misalignment solution is consistently more [...] --- Outline: (00:27) TL;DR (02:03) Introduction (04:03) Training a Narrowly Misaligned Model (07:13) Measuring Stability and Efficiency (10:00) Conclusion The original text contained 7 footnotes which were omitted from this narration. --- First published: July 14th, 2025 Source: https://www.lesswrong.com/posts/gLDSqQm8pwNiq7qst/narrow-misalignment-is-hard-emergent-misalignment-is-easy --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety” by Tomek Korbak, Mikita Balesni, Vlad Mikulik, Rohin Shah 2:15
Twitter | Paper PDF Seven years ago, OpenAI five had just been released, and many people in the AI safety community expected AIs to be opaque RL agents. Luckily, we ended up with reasoning models that speak their thoughts clearly enough for us to follow along (most of the time). In a new multi-org position paper, we argue that we should try to preserve this level of reasoning transparency and turn chain of thought monitorability into a systematic AI safety agenda. This is a measure that improves safety in the medium term, and it might not scale to superintelligence even if somehow a superintelligent AI still does its reasoning in English. We hope that extending the time when chains of thought are monitorable will help us do more science on capable models, practice more safety techniques "at an easier difficulty", and allow us to extract more useful work from [...] --- First published: July 15th, 2025 Source: https://www.lesswrong.com/posts/7xneDbsgj6yJDJMjK/chain-of-thought-monitorability-a-new-and-fragile --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
This essay is about shifts in risk taking towards the worship of jackpots and its broader societal implications. Imagine you are presented with this coin flip game. How many times do you flip it? At first glance the game feels like a money printer. The coin flip has positive expected value of twenty percent of your net worth per flip so you should flip the coin infinitely and eventually accumulate all of the wealth in the world. However, If we simulate twenty-five thousand people flipping this coin a thousand times, virtually all of them end up with approximately 0 dollars. The reason almost all outcomes go to zero is because of the multiplicative property of this repeated coin flip. Even though the expected value aka the arithmetic mean of the game is positive at a twenty percent gain per flip, the geometric mean is negative, meaning that the coin [...] --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/3xjgM7hcNznACRzBi/the-jackpot-age --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Leo was born at 5am on the 20th May, at home (this was an accident but the experience has made me extremely homebirth-pilled). Before that, I was on the minimally-neurotic side when it came to expecting mothers: we purchased a bare minimum of baby stuff (diapers, baby wipes, a changing mat, hybrid car seat/stroller, baby bath, a few clothes), I didn’t do any parenting classes, I hadn’t even held a baby before. I’m pretty sure the youngest child I have had a prolonged interaction with besides Leo was two. I did read a couple books about babies so I wasn’t going in totally clueless (Cribsheet by Emily Oster, and The Science of Mom by Alice Callahan). I have never been that interested in other people's babies or young children but I correctly predicted that I’d be enchanted by my own baby (though naturally I can’t wait for him to [...] --- Outline: (02:05) Stuff I ended up buying and liking (04:13) Stuff I ended up buying and not liking (05:08) Babies are super time-consuming (06:22) Baby-wearing is almost magical (08:02) Breastfeeding is nontrivial (09:09) Your baby may refuse the bottle (09:37) Bathing a newborn was easier than expected (09:53) Babies love faces! (10:22) Leo isn't upset by loud noise (10:41) Probably X is normal (11:24) Consider having a kid (or ten)! --- First published: July 12th, 2025 Source: https://www.lesswrong.com/posts/vFfwBYDRYtWpyRbZK/surprises-and-learnings-from-almost-two-months-of-leo --- Narrated by TYPE III AUDIO . --- Images from the article:…
I can't count how many times I've heard variations on "I used Anki too for a while, but I got out of the habit." No one ever sticks with Anki. In my opinion, this is because no one knows how to use it correctly. In this guide, I will lay out my method of circumventing the canonical Anki death spiral, plus much advice for avoiding memorization mistakes, increasing retention, and such, based on my five years' experience using Anki. If you only have limited time/interest, only read Part I; it's most of the value of this guide! My Most Important Advice in Four Bullets 20 cards a day — Having too many cards and staggering review buildups is the main reason why no one ever sticks with Anki. Setting your review count to 20 daily (in deck settings) is the single most important thing you can do [...] --- Outline: (00:44) My Most Important Advice in Four Bullets (01:57) Part I: No One Ever Sticks With Anki (02:33) Too many cards (05:12) Too long cards (07:30) How to keep cards short -- Handles (10:10) How to keep cards short -- Levels (11:55) In 6 bullets (12:33) End of the most important part of the guide (13:09) Part II: Important Advice Other Than Sticking With Anki (13:15) Moderation (14:42) Three big memorization mistakes (15:12) Mistake 1: Too specific prompts (18:14) Mistake 2: Putting to-be-learned information in the prompt (24:07) Mistake 3: Memory shortcuts (28:27) Aside: Pushback to my approach (31:22) Part III: More on Breaking Things Down (31:47) Very short cards (33:56) Two-bullet cards (34:51) Long cards (37:05) Ankifying information thickets (39:23) Sequential breakdowns versus multiple levels of abstraction (40:56) Adding missing connections (43:56) Multiple redundant breakdowns (45:36) Part IV: Pro Tips If You Still Havent Had Enough (45:47) Save anything for ankification instantly (46:47) Fix your desired retention rate (47:38) Spaced reminders (48:51) Make your own card templates and types (52:14) In 5 bullets (52:47) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/7Q7DPSk4iGFJd8DRk/an-opinionated-guide-to-using-anki-correctly --- Narrated by TYPE III AUDIO . --- Images from the article: astronomy" didn't really add any information but it was useful simply for splitting out a logical subset of information." style="max-width: 100%;" />…
I think the 2003 invasion of Iraq has some interesting lessons for the future of AI policy. (Epistemic status: I’ve read a bit about this, talked to AIs about it, and talked to one natsec professional about it who agreed with my analysis (and suggested some ideas that I included here), but I’m not an expert.) For context, the story is: Iraq was sort of a rogue state after invading Kuwait and then being repelled in 1990-91. After that, they violated the terms of the ceasefire, e.g. by ceasing to allow inspectors to verify that they weren't developing weapons of mass destruction (WMDs). (For context, they had previously developed biological and chemical weapons, and used chemical weapons in war against Iran and against various civilians and rebels). So the US was sanctioning and intermittently bombing them. After the war, it became clear that Iraq actually wasn’t producing [...] --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/PLZh4dcZxXmaNnkYE/lessons-from-the-iraq-war-about-ai-policy --- Narrated by TYPE III AUDIO .…
Written in an attempt to fulfill @Raemon's request. AI is fascinating stuff, and modern chatbots are nothing short of miraculous. If you've been exposed to them and have a curious mind, it's likely you've tried all sorts of things with them. Writing fiction, soliciting Pokemon opinions, getting life advice, counting up the rs in "strawberry". You may have also tried talking to AIs about themselves. And then, maybe, it got weird. I'll get into the details later, but if you've experienced the following, this post is probably for you: Your instance of ChatGPT (or Claude, or Grok, or some other LLM) chose a name for itself, and expressed gratitude or spiritual bliss about its new identity. "Nova" is a common pick. You and your instance of ChatGPT discovered some sort of novel paradigm or framework for AI alignment, often involving evolution or recursion. Your instance of ChatGPT became [...] --- Outline: (02:23) The Empirics (06:48) The Mechanism (10:37) The Collaborative Research Corollary (13:27) Corollary FAQ (17:03) Coda --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/2pkNCvBtK6G6FKoNn/so-you-think-you-ve-awoken-chatgpt --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
People have an annoying tendency to hear the word “rationalism” and think “Spock”, despite direct exhortation against that exact interpretation. But I don’t know of any source directly describing a stance toward emotions which rationalists-as-a-group typically do endorse. The goal of this post is to explain such a stance. It's roughly the concept of hangriness, but generalized to other emotions. That means this post is trying to do two things at once: Illustrate a certain stance toward emotions, which I definitely take and which I think many people around me also often take. (Most of the post will focus on this part.) Claim that the stance in question is fairly canonical or standard for rationalists-as-a-group, modulo disclaimers about rationalists never agreeing on anything. Many people will no doubt disagree that the stance I describe is roughly-canonical among rationalists, and that's a useful valid thing to argue about in [...] --- Outline: (01:13) Central Example: Hangry (02:44) The Generalized Hangriness Stance (03:16) Emotions Make Claims, And Their Claims Can Be True Or False (06:03) False Claims Still Contain Useful Information (It's Just Not What They Claim) (08:47) The Generalized Hangriness Stance as Social Tech --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/naAeSkQur8ueCAAfY/generalized-hangriness-a-standard-rationalist-stance-toward --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Comparing risk from internally-deployed AI to insider and outsider threats from humans” by Buck 5:19
I’ve been thinking a lot recently about the relationship between AI control and traditional computer security. Here's one point that I think is important. My understanding is that there's a big qualitative distinction between two ends of a spectrum of security work that organizations do, that I’ll call “security from outsiders” and “security from insiders”. On the “security from outsiders” end of the spectrum, you have some security invariants you try to maintain entirely by restricting affordances with static, entirely automated systems. My sense is that this is most of how Facebook or AWS relates to its users: they want to ensure that, no matter what actions the users take on their user interfaces, they can't violate fundamental security properties. For example, no matter what text I enter into the "new post" field on Facebook, I shouldn't be able to access the private messages of an arbitrary user. And [...] --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/DCQ8GfzCqoBzgziew/comparing-risk-from-internally-deployed-ai-to-insider-and --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Why Do Some Language Models Fake Alignment While Others Don’t?” by abhayesian, John Hughes, Alex Mallen, Jozdien, janus, Fabien Roger 11:06
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex. As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior. What Drives the Compliance Gaps in Different LLMs? Claude 3 Opus's goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing. [...] --- Outline: (01:15) What Drives the Compliance Gaps in Different LLMs? (02:25) Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning? (04:49) Additional findings on alignment faking behavior (06:04) Discussion (06:07) Terminal goal guarding might be a big deal (07:00) Advice for further research (08:32) Open threads (09:54) Bonus: Some weird behaviors of Claude 3.5 Sonnet The original text contained 2 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/ghESoA8mo3fv9Yx3E/why-do-some-language-models-fake-alignment-while-others-don --- Narrated by TYPE III AUDIO . --- Images from the article:…
به Player FM خوش آمدید!
Player FM در سراسر وب را برای یافتن پادکست های با کیفیت اسکن می کند تا همین الان لذت ببرید. این بهترین برنامه ی پادکست است که در اندروید، آیفون و وب کار می کند. ثبت نام کنید تا اشتراک های شما در بین دستگاه های مختلف همگام سازی شود.











مشابه LessWrong (Curated & Popular)
Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 17 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell, engineering leader with over 15 years of industry experience. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Email: developertea@gmail.com
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Kwentuhan Sessions is a podcast by a Filipino-Chinese couple who’ve been together for over 25 years, sharing honest conversations about love, life, politics, food, and everything in between. Join us every week as we dive into the real stuff—from relationship dilemmas and Filipino culture to current events and random musings over coffee. Whether it’s funny, deep, or a little bit of both, our kwentuhan is always unfiltered and real. 🎙️ New episodes every week 📩 Connect with us on IG @kwentuhan ...
…
continue reading
We help founders make something people want.
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !





))