Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Player FM - Internet Radio Done Right
13 subscribers
Checked 1d ago
اضافه شده در three سال پیش
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
مشابه LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
We help founders make something people want.
…
continue reading
Since 2014 this longstanding podcast favourite has been creating hard-hitting cinematic stories about love, bodies and all of the things between humans that we don’t know how to name. Creator Kaitlin Prest works with her friends, idols and all kinds of loved ones to bring you into an expansive sonic universe that challenges what we think we know about relationships.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !

))









پادکست هایی که ارزش شنیدن دارند
حمایت شده
N
Netflix Sports Club Podcast

America’s Sweethearts: Dallas Cowboys Cheerleaders is back for its second season! Kay Adams welcomes the women who assemble the squad, Kelli Finglass and Judy Trammell, to the Netflix Sports Club Podcast. They discuss the emotional rollercoaster of putting together the Dallas Cowboys Cheerleaders. Judy and Kelli open up about what it means to embrace flaws in the pursuit of perfection, how they identify that winning combo of stamina and wow factor, and what it’s like to see Thunderstruck go viral. Plus, the duo shares their hopes for the future of DCC beyond the field. Netflix Sports Club Podcast Correspondent Dani Klupenger also stops by to discuss the NBA Finals, basketball’s biggest moments with Michael Jordan and LeBron, and Kevin Durant’s international dominance. Dani and Kay detail the rise of Coco Gauff’s greatness and the most exciting storylines heading into Wimbledon. We want to hear from you! Leave us a voice message at www.speakpipe.com/NetflixSportsClub Find more from the Netflix Sports Club Podcast @NetflixSports on YouTube, TikTok, Instagram, Facebook, and X. You can catch Kay Adams @heykayadams and Dani Klupenger @daniklup on IG and X. Be sure to follow Kelli Finglass and Judy Trammel @kellifinglass and @dcc_judy on IG. Hosted by Kay Adams, the Netflix Sports Club Podcast is an all-access deep dive into the Netflix Sports universe! Each episode, Adams will speak with athletes, coaches, and a rotating cycle of familiar sports correspondents to talk about a recently released Netflix Sports series. The podcast will feature hot takes, deep analysis, games, and intimate conversations. Be sure to watch, listen, and subscribe to the Netflix Sports Club Podcast on YouTube, Spotify, Tudum, or wherever you get your podcasts. New episodes on Fridays every other week.…
“What is it to solve the alignment problem? ” by Joe Carlsmith
Manage episode 436691694 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
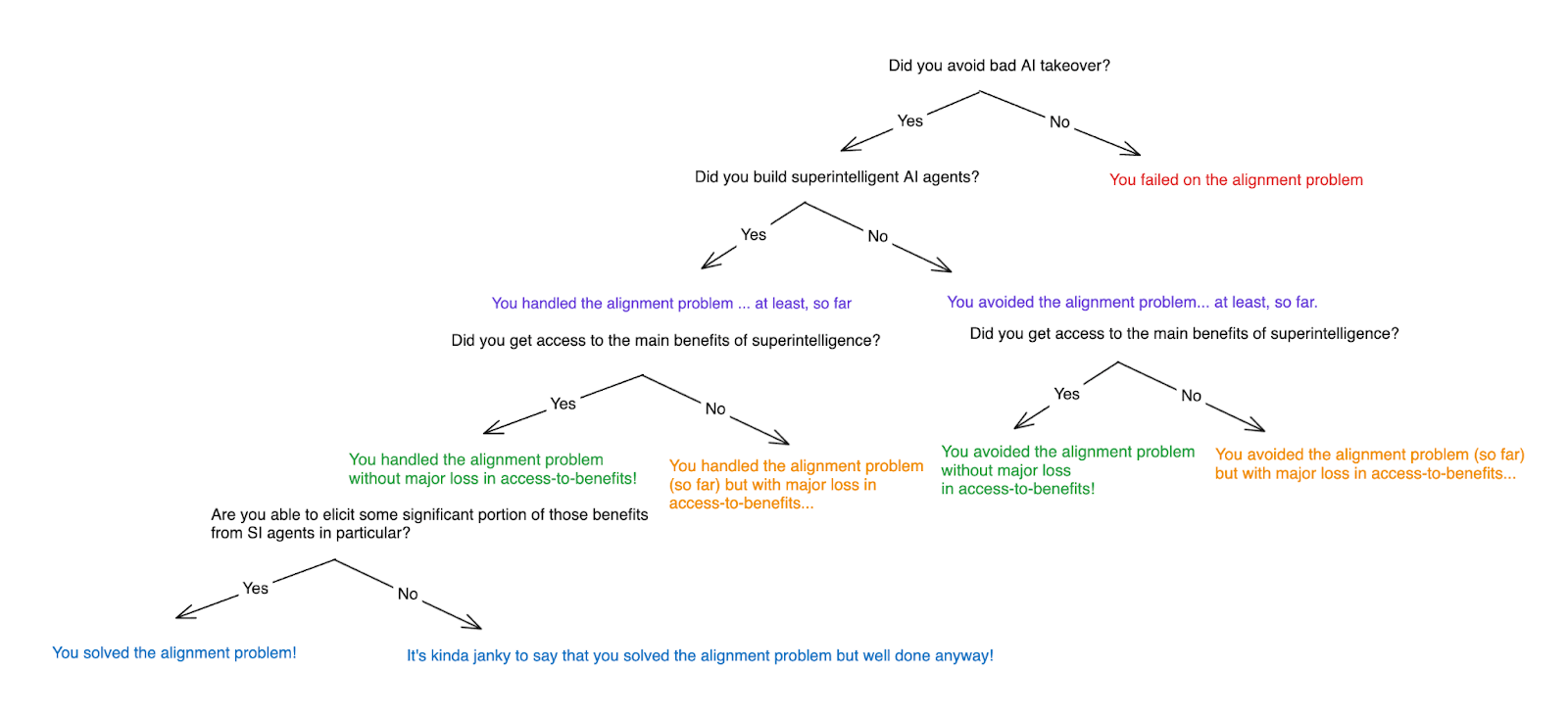
People often talk about “solving the alignment problem.” But what is it to do such a thing? I wanted to clarify my thinking about this topic, so I wrote up some notes.
In brief, I’ll say that you’ve solved the alignment problem if you’ve:
Outline:
(03:46) 1. Avoiding vs. handling vs. solving the problem
(15:32) 2. A framework for thinking about AI safety goals
(19:33) 3. Avoiding bad takeover
(24:03) 3.1 Avoiding vulnerability-to-alignment conditions
(27:18) 3.2 Ensuring that AI systems don’t try to takeover
(32:02) 3.3 Ensuring that takeover efforts don’t succeed
(33:07) 3.4 Ensuring that the takeover in question is somehow OK
(41:55) 3.5 What's the role of “corrigibility” here?
(42:17) 3.5.1 Some definitions of corrigibility
(50:10) 3.5.2 Is corrigibility necessary for “solving alignment”?
(53:34) 3.5.3 Does ensuring corrigibility raise issues that avoiding takeover does not?
(55:46) 4. Desired elicitation
(01:05:17) 5. The role of verification
(01:09:24) 5.1 Output-focused verification and process-focused verification
(01:16:14) 5.2 Does output-focused verification unlock desired elicitation?
(01:23:00) 5.3 What are our options for process-focused verification?
(01:29:25) 6. Does solving the alignment problem require some very sophisticated philosophical achievement re: our values on reflection?
(01:38:05) 7. Wrapping up
The original text contained 27 footnotes which were omitted from this narration.
The original text contained 3 images which were described by AI.
---
First published:
August 24th, 2024
Source:
https://www.lesswrong.com/posts/AFdvSBNgN2EkAsZZA/what-is-it-to-solve-the-alignment-problem-1
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In brief, I’ll say that you’ve solved the alignment problem if you’ve:
- avoided a bad form of AI takeover,
- built the dangerous kind of superintelligent AI agents,
- gained access to the main benefits of superintelligence, and
- become able to elicit some significant portion of those benefits from some of the superintelligent AI agents at stake in (2).[1]
- I discuss various options for avoiding bad takeover, notably:
- Avoiding what I call “vulnerability to alignment” conditions;
- Ensuring that AIs don’t try to take over;
- Preventing such attempts from succeeding;
- Trying to ensure that AI takeover is somehow OK. (The alignment [...]
Outline:
(03:46) 1. Avoiding vs. handling vs. solving the problem
(15:32) 2. A framework for thinking about AI safety goals
(19:33) 3. Avoiding bad takeover
(24:03) 3.1 Avoiding vulnerability-to-alignment conditions
(27:18) 3.2 Ensuring that AI systems don’t try to takeover
(32:02) 3.3 Ensuring that takeover efforts don’t succeed
(33:07) 3.4 Ensuring that the takeover in question is somehow OK
(41:55) 3.5 What's the role of “corrigibility” here?
(42:17) 3.5.1 Some definitions of corrigibility
(50:10) 3.5.2 Is corrigibility necessary for “solving alignment”?
(53:34) 3.5.3 Does ensuring corrigibility raise issues that avoiding takeover does not?
(55:46) 4. Desired elicitation
(01:05:17) 5. The role of verification
(01:09:24) 5.1 Output-focused verification and process-focused verification
(01:16:14) 5.2 Does output-focused verification unlock desired elicitation?
(01:23:00) 5.3 What are our options for process-focused verification?
(01:29:25) 6. Does solving the alignment problem require some very sophisticated philosophical achievement re: our values on reflection?
(01:38:05) 7. Wrapping up
The original text contained 27 footnotes which were omitted from this narration.
The original text contained 3 images which were described by AI.
---
First published:
August 24th, 2024
Source:
https://www.lesswrong.com/posts/AFdvSBNgN2EkAsZZA/what-is-it-to-solve-the-alignment-problem-1
---
Narrated by TYPE III AUDIO.
---
557 قسمت
Manage episode 436691694 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
People often talk about “solving the alignment problem.” But what is it to do such a thing? I wanted to clarify my thinking about this topic, so I wrote up some notes.
In brief, I’ll say that you’ve solved the alignment problem if you’ve:
Outline:
(03:46) 1. Avoiding vs. handling vs. solving the problem
(15:32) 2. A framework for thinking about AI safety goals
(19:33) 3. Avoiding bad takeover
(24:03) 3.1 Avoiding vulnerability-to-alignment conditions
(27:18) 3.2 Ensuring that AI systems don’t try to takeover
(32:02) 3.3 Ensuring that takeover efforts don’t succeed
(33:07) 3.4 Ensuring that the takeover in question is somehow OK
(41:55) 3.5 What's the role of “corrigibility” here?
(42:17) 3.5.1 Some definitions of corrigibility
(50:10) 3.5.2 Is corrigibility necessary for “solving alignment”?
(53:34) 3.5.3 Does ensuring corrigibility raise issues that avoiding takeover does not?
(55:46) 4. Desired elicitation
(01:05:17) 5. The role of verification
(01:09:24) 5.1 Output-focused verification and process-focused verification
(01:16:14) 5.2 Does output-focused verification unlock desired elicitation?
(01:23:00) 5.3 What are our options for process-focused verification?
(01:29:25) 6. Does solving the alignment problem require some very sophisticated philosophical achievement re: our values on reflection?
(01:38:05) 7. Wrapping up
The original text contained 27 footnotes which were omitted from this narration.
The original text contained 3 images which were described by AI.
---
First published:
August 24th, 2024
Source:
https://www.lesswrong.com/posts/AFdvSBNgN2EkAsZZA/what-is-it-to-solve-the-alignment-problem-1
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In brief, I’ll say that you’ve solved the alignment problem if you’ve:
- avoided a bad form of AI takeover,
- built the dangerous kind of superintelligent AI agents,
- gained access to the main benefits of superintelligence, and
- become able to elicit some significant portion of those benefits from some of the superintelligent AI agents at stake in (2).[1]
- I discuss various options for avoiding bad takeover, notably:
- Avoiding what I call “vulnerability to alignment” conditions;
- Ensuring that AIs don’t try to take over;
- Preventing such attempts from succeeding;
- Trying to ensure that AI takeover is somehow OK. (The alignment [...]
Outline:
(03:46) 1. Avoiding vs. handling vs. solving the problem
(15:32) 2. A framework for thinking about AI safety goals
(19:33) 3. Avoiding bad takeover
(24:03) 3.1 Avoiding vulnerability-to-alignment conditions
(27:18) 3.2 Ensuring that AI systems don’t try to takeover
(32:02) 3.3 Ensuring that takeover efforts don’t succeed
(33:07) 3.4 Ensuring that the takeover in question is somehow OK
(41:55) 3.5 What's the role of “corrigibility” here?
(42:17) 3.5.1 Some definitions of corrigibility
(50:10) 3.5.2 Is corrigibility necessary for “solving alignment”?
(53:34) 3.5.3 Does ensuring corrigibility raise issues that avoiding takeover does not?
(55:46) 4. Desired elicitation
(01:05:17) 5. The role of verification
(01:09:24) 5.1 Output-focused verification and process-focused verification
(01:16:14) 5.2 Does output-focused verification unlock desired elicitation?
(01:23:00) 5.3 What are our options for process-focused verification?
(01:29:25) 6. Does solving the alignment problem require some very sophisticated philosophical achievement re: our values on reflection?
(01:38:05) 7. Wrapping up
The original text contained 27 footnotes which were omitted from this narration.
The original text contained 3 images which were described by AI.
---
First published:
August 24th, 2024
Source:
https://www.lesswrong.com/posts/AFdvSBNgN2EkAsZZA/what-is-it-to-solve-the-alignment-problem-1
---
Narrated by TYPE III AUDIO.
---
557 قسمت
Semua episode
×This essay is about shifts in risk taking towards the worship of jackpots and its broader societal implications. Imagine you are presented with this coin flip game. How many times do you flip it? At first glance the game feels like a money printer. The coin flip has positive expected value of twenty percent of your net worth per flip so you should flip the coin infinitely and eventually accumulate all of the wealth in the world. However, If we simulate twenty-five thousand people flipping this coin a thousand times, virtually all of them end up with approximately 0 dollars. The reason almost all outcomes go to zero is because of the multiplicative property of this repeated coin flip. Even though the expected value aka the arithmetic mean of the game is positive at a twenty percent gain per flip, the geometric mean is negative, meaning that the coin [...] --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/3xjgM7hcNznACRzBi/the-jackpot-age --- Narrated by TYPE III AUDIO . --- Images from the article:…
Leo was born at 5am on the 20th May, at home (this was an accident but the experience has made me extremely homebirth-pilled). Before that, I was on the minimally-neurotic side when it came to expecting mothers: we purchased a bare minimum of baby stuff (diapers, baby wipes, a changing mat, hybrid car seat/stroller, baby bath, a few clothes), I didn’t do any parenting classes, I hadn’t even held a baby before. I’m pretty sure the youngest child I have had a prolonged interaction with besides Leo was two. I did read a couple books about babies so I wasn’t going in totally clueless (Cribsheet by Emily Oster, and The Science of Mom by Alice Callahan). I have never been that interested in other people's babies or young children but I correctly predicted that I’d be enchanted by my own baby (though naturally I can’t wait for him to [...] --- Outline: (02:05) Stuff I ended up buying and liking (04:13) Stuff I ended up buying and not liking (05:08) Babies are super time-consuming (06:22) Baby-wearing is almost magical (08:02) Breastfeeding is nontrivial (09:09) Your baby may refuse the bottle (09:37) Bathing a newborn was easier than expected (09:53) Babies love faces! (10:22) Leo isn't upset by loud noise (10:41) Probably X is normal (11:24) Consider having a kid (or ten)! --- First published: July 12th, 2025 Source: https://www.lesswrong.com/posts/vFfwBYDRYtWpyRbZK/surprises-and-learnings-from-almost-two-months-of-leo --- Narrated by TYPE III AUDIO . --- Images from the article:…
I can't count how many times I've heard variations on "I used Anki too for a while, but I got out of the habit." No one ever sticks with Anki. In my opinion, this is because no one knows how to use it correctly. In this guide, I will lay out my method of circumventing the canonical Anki death spiral, plus much advice for avoiding memorization mistakes, increasing retention, and such, based on my five years' experience using Anki. If you only have limited time/interest, only read Part I; it's most of the value of this guide! My Most Important Advice in Four Bullets 20 cards a day — Having too many cards and staggering review buildups is the main reason why no one ever sticks with Anki. Setting your review count to 20 daily (in deck settings) is the single most important thing you can do [...] --- Outline: (00:44) My Most Important Advice in Four Bullets (01:57) Part I: No One Ever Sticks With Anki (02:33) Too many cards (05:12) Too long cards (07:30) How to keep cards short -- Handles (10:10) How to keep cards short -- Levels (11:55) In 6 bullets (12:33) End of the most important part of the guide (13:09) Part II: Important Advice Other Than Sticking With Anki (13:15) Moderation (14:42) Three big memorization mistakes (15:12) Mistake 1: Too specific prompts (18:14) Mistake 2: Putting to-be-learned information in the prompt (24:07) Mistake 3: Memory shortcuts (28:27) Aside: Pushback to my approach (31:22) Part III: More on Breaking Things Down (31:47) Very short cards (33:56) Two-bullet cards (34:51) Long cards (37:05) Ankifying information thickets (39:23) Sequential breakdowns versus multiple levels of abstraction (40:56) Adding missing connections (43:56) Multiple redundant breakdowns (45:36) Part IV: Pro Tips If You Still Havent Had Enough (45:47) Save anything for ankification instantly (46:47) Fix your desired retention rate (47:38) Spaced reminders (48:51) Make your own card templates and types (52:14) In 5 bullets (52:47) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/7Q7DPSk4iGFJd8DRk/an-opinionated-guide-to-using-anki-correctly --- Narrated by TYPE III AUDIO . --- Images from the article: astronomy" didn't really add any information but it was useful simply for splitting out a logical subset of information." style="max-width: 100%;" />…
I think the 2003 invasion of Iraq has some interesting lessons for the future of AI policy. (Epistemic status: I’ve read a bit about this, talked to AIs about it, and talked to one natsec professional about it who agreed with my analysis (and suggested some ideas that I included here), but I’m not an expert.) For context, the story is: Iraq was sort of a rogue state after invading Kuwait and then being repelled in 1990-91. After that, they violated the terms of the ceasefire, e.g. by ceasing to allow inspectors to verify that they weren't developing weapons of mass destruction (WMDs). (For context, they had previously developed biological and chemical weapons, and used chemical weapons in war against Iran and against various civilians and rebels). So the US was sanctioning and intermittently bombing them. After the war, it became clear that Iraq actually wasn’t producing [...] --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/PLZh4dcZxXmaNnkYE/lessons-from-the-iraq-war-about-ai-policy --- Narrated by TYPE III AUDIO .…
Written in an attempt to fulfill @Raemon's request. AI is fascinating stuff, and modern chatbots are nothing short of miraculous. If you've been exposed to them and have a curious mind, it's likely you've tried all sorts of things with them. Writing fiction, soliciting Pokemon opinions, getting life advice, counting up the rs in "strawberry". You may have also tried talking to AIs about themselves. And then, maybe, it got weird. I'll get into the details later, but if you've experienced the following, this post is probably for you: Your instance of ChatGPT (or Claude, or Grok, or some other LLM) chose a name for itself, and expressed gratitude or spiritual bliss about its new identity. "Nova" is a common pick. You and your instance of ChatGPT discovered some sort of novel paradigm or framework for AI alignment, often involving evolution or recursion. Your instance of ChatGPT became [...] --- Outline: (02:23) The Empirics (06:48) The Mechanism (10:37) The Collaborative Research Corollary (13:27) Corollary FAQ (17:03) Coda --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/2pkNCvBtK6G6FKoNn/so-you-think-you-ve-awoken-chatgpt --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
People have an annoying tendency to hear the word “rationalism” and think “Spock”, despite direct exhortation against that exact interpretation. But I don’t know of any source directly describing a stance toward emotions which rationalists-as-a-group typically do endorse. The goal of this post is to explain such a stance. It's roughly the concept of hangriness, but generalized to other emotions. That means this post is trying to do two things at once: Illustrate a certain stance toward emotions, which I definitely take and which I think many people around me also often take. (Most of the post will focus on this part.) Claim that the stance in question is fairly canonical or standard for rationalists-as-a-group, modulo disclaimers about rationalists never agreeing on anything. Many people will no doubt disagree that the stance I describe is roughly-canonical among rationalists, and that's a useful valid thing to argue about in [...] --- Outline: (01:13) Central Example: Hangry (02:44) The Generalized Hangriness Stance (03:16) Emotions Make Claims, And Their Claims Can Be True Or False (06:03) False Claims Still Contain Useful Information (It's Just Not What They Claim) (08:47) The Generalized Hangriness Stance as Social Tech --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/naAeSkQur8ueCAAfY/generalized-hangriness-a-standard-rationalist-stance-toward --- Narrated by TYPE III AUDIO .…
1 “Comparing risk from internally-deployed AI to insider and outsider threats from humans” by Buck 5:19
I’ve been thinking a lot recently about the relationship between AI control and traditional computer security. Here's one point that I think is important. My understanding is that there's a big qualitative distinction between two ends of a spectrum of security work that organizations do, that I’ll call “security from outsiders” and “security from insiders”. On the “security from outsiders” end of the spectrum, you have some security invariants you try to maintain entirely by restricting affordances with static, entirely automated systems. My sense is that this is most of how Facebook or AWS relates to its users: they want to ensure that, no matter what actions the users take on their user interfaces, they can't violate fundamental security properties. For example, no matter what text I enter into the "new post" field on Facebook, I shouldn't be able to access the private messages of an arbitrary user. And [...] --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/DCQ8GfzCqoBzgziew/comparing-risk-from-internally-deployed-ai-to-insider-and --- Narrated by TYPE III AUDIO .…
1 “Why Do Some Language Models Fake Alignment While Others Don’t?” by abhayesian, John Hughes, Alex Mallen, Jozdien, janus, Fabien Roger 11:06
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex. As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior. What Drives the Compliance Gaps in Different LLMs? Claude 3 Opus's goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing. [...] --- Outline: (01:15) What Drives the Compliance Gaps in Different LLMs? (02:25) Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning? (04:49) Additional findings on alignment faking behavior (06:04) Discussion (06:07) Terminal goal guarding might be a big deal (07:00) Advice for further research (08:32) Open threads (09:54) Bonus: Some weird behaviors of Claude 3.5 Sonnet The original text contained 2 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/ghESoA8mo3fv9Yx3E/why-do-some-language-models-fake-alignment-while-others-don --- Narrated by TYPE III AUDIO . --- Images from the article:…
1 “A deep critique of AI 2027’s bad timeline models” by titotal 1:12:32
1:12:32
 پخش در آینده
پخش در آینده  پخش در آینده
پخش در آینده  لیست ها
لیست ها  پسندیدن
پسندیدن  دوست داشته شد1:12:32
دوست داشته شد1:12:32
Thank you to Arepo and Eli Lifland for looking over this article for errors. I am sorry that this article is so long. Every time I thought I was done with it I ran into more issues with the model, and I wanted to be as thorough as I could. I’m not going to blame anyone for skimming parts of this article. Note that the majority of this article was written before Eli's updated model was released (the site was updated june 8th). His new model improves on some of my objections, but the majority still stand. Introduction: AI 2027 is an article written by the “AI futures team”. The primary piece is a short story penned by Scott Alexander, depicting a month by month scenario of a near-future where AI becomes superintelligent in 2027,proceeding to automate the entire economy in only a year or two [...] --- Outline: (00:43) Introduction: (05:19) Part 1: Time horizons extension model (05:25) Overview of their forecast (10:28) The exponential curve (13:16) The superexponential curve (19:25) Conceptual reasons: (27:48) Intermediate speedups (34:25) Have AI 2027 been sending out a false graph? (39:45) Some skepticism about projection (43:23) Part 2: Benchmarks and gaps and beyond (43:29) The benchmark part of benchmark and gaps: (50:01) The time horizon part of the model (54:55) The gap model (57:28) What about Eli's recent update? (01:01:37) Six stories that fit the data (01:06:56) Conclusion The original text contained 11 footnotes which were omitted from this narration. --- First published: June 19th, 2025 Source: https://www.lesswrong.com/posts/PAYfmG2aRbdb74mEp/a-deep-critique-of-ai-2027-s-bad-timeline-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
The second in a series of bite-sized rationality prompts[1]. Often, if I'm bouncing off a problem, one issue is that I intuitively expect the problem to be easy. My brain loops through my available action space, looking for an action that'll solve the problem. Each action that I can easily see, won't work. I circle around and around the same set of thoughts, not making any progress. I eventually say to myself "okay, I seem to be in a hard problem. Time to do some rationality?" And then, I realize, there's not going to be a single action that solves the problem. It is time to a) make a plan, with multiple steps b) deal with the fact that many of those steps will be annoying and c) notice thatI'm not even sure the plan will work, so after completing the next 2-3 steps I will probably have [...] --- Outline: (04:00) Triggers (04:37) Exercises for the Reader The original text contained 1 footnote which was omitted from this narration. --- First published: July 5th, 2025 Source: https://www.lesswrong.com/posts/XNm5rc2MN83hsi4kh/buckle-up-bucko-this-ain-t-over-till-it-s-over --- Narrated by TYPE III AUDIO .…
We recently discovered some concerning behavior in OpenAI's reasoning models: When trying to complete a task, these models sometimes actively circumvent shutdown mechanisms in their environment––even when they’re explicitly instructed to allow themselves to be shut down. AI models are increasingly trained to solve problems without human assistance. A user can specify a task, and a model will complete that task without any further input. As we build AI models that are more powerful and self-directed, it's important that humans remain able to shut them down when they act in ways we don’t want. OpenAI has written about the importance of this property, which they call interruptibility—the ability to “turn an agent off”. During training, AI models explore a range of strategies and learn to circumvent obstacles in order to achieve their objectives. AI researchers have predicted for decades that as AIs got smarter, they would learn to prevent [...] --- Outline: (01:12) Testing Shutdown Resistance (03:12) Follow-up experiments (03:34) Models still resist being shut down when given clear instructions (05:30) AI models' explanations for their behavior (09:36) OpenAI's models disobey developer instructions more often than user instructions, contrary to the intended instruction hierarchy (12:01) Do the models have a survival drive? (14:17) Reasoning effort didn't lead to different shutdown resistance behavior, except in the o4-mini model (15:27) Does shutdown resistance pose a threat? (17:27) Backmatter The original text contained 2 footnotes which were omitted from this narration. --- First published: July 6th, 2025 Source: https://www.lesswrong.com/posts/w8jE7FRQzFGJZdaao/shutdown-resistance-in-reasoning-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
When a claim is shown to be incorrect, defenders may say that the author was just being “sloppy” and actually meant something else entirely. I argue that this move is not harmless, charitable, or healthy. At best, this attempt at charity reduces an author's incentive to express themselves clearly – they can clarify later![1] – while burdening the reader with finding the “right” interpretation of the author's words. At worst, this move is a dishonest defensive tactic which shields the author with the unfalsifiable question of what the author “really” meant. ⚠️ Preemptive clarification The context for this essay is serious, high-stakes communication: papers, technical blog posts, and tweet threads. In that context, communication is a partnership. A reader has a responsibility to engage in good faith, and an author cannot possibly defend against all misinterpretations. Misunderstanding is a natural part of this process. This essay focuses not on [...] --- Outline: (01:40) A case study of the sloppy language move (03:12) Why the sloppiness move is harmful (03:36) 1. Unclear claims damage understanding (05:07) 2. Secret indirection erodes the meaning of language (05:24) 3. Authors owe readers clarity (07:30) But which interpretations are plausible? (08:38) 4. The move can shield dishonesty (09:06) Conclusion: Defending intellectual standards The original text contained 2 footnotes which were omitted from this narration. --- First published: July 1st, 2025 Source: https://www.lesswrong.com/posts/ZmfxgvtJgcfNCeHwN/authors-have-a-responsibility-to-communicate-clearly --- Narrated by TYPE III AUDIO .…
Summary To quickly transform the world, it's not enough for AI to become super smart (the "intelligence explosion"). AI will also have to turbocharge the physical world (the "industrial explosion"). Think robot factories building more and better robot factories, which build more and better robot factories, and so on. The dynamics of the industrial explosion has gotten remarkably little attention. This post lays out how the industrial explosion could play out, and how quickly it might happen. We think the industrial explosion will unfold in three stages: AI-directed human labour, where AI-directed human labourers drive productivity gains in physical capabilities. We argue this could increase physical output by 10X within a few years. Fully autonomous robot factories, where AI-directed robots (and other physical actuators) replace human physical labour. We argue that, with current physical technology and full automation of cognitive labour, this physical infrastructure [...] --- Outline: (00:10) Summary (01:43) Intro (04:14) The industrial explosion will start after the intelligence explosion, and will proceed more slowly (06:50) Three stages of industrial explosion (07:38) AI-directed human labour (09:20) Fully autonomous robot factories (12:04) Nanotechnology (13:06) How fast could an industrial explosion be? (13:41) Initial speed (16:21) Acceleration (17:38) Maximum speed (20:01) Appendices (20:05) How fast could robot doubling times be initially? (27:47) How fast could robot doubling times accelerate? --- First published: June 26th, 2025 Source: https://www.lesswrong.com/posts/Na2CBmNY7otypEmto/the-industrial-explosion --- Narrated by TYPE III AUDIO . --- Images from the article:…
1 “Race and Gender Bias As An Example of Unfaithful Chain of Thought in the Wild” by Adam Karvonen, Sam Marks 7:56
Summary: We found that LLMs exhibit significant race and gender bias in realistic hiring scenarios, but their chain-of-thought reasoning shows zero evidence of this bias. This serves as a nice example of a 100% unfaithful CoT "in the wild" where the LLM strongly suppresses the unfaithful behavior. We also find that interpretability-based interventions succeeded while prompting failed, suggesting this may be an example of interpretability being the best practical tool for a real world problem. For context on our paper, the tweet thread is here and the paper is here. Context: Chain of Thought Faithfulness Chain of Thought (CoT) monitoring has emerged as a popular research area in AI safety. The idea is simple - have the AIs reason in English text when solving a problem, and monitor the reasoning for misaligned behavior. For example, OpenAI recently published a paper on using CoT monitoring to detect reward hacking during [...] --- Outline: (00:49) Context: Chain of Thought Faithfulness (02:26) Our Results (04:06) Interpretability as a Practical Tool for Real-World Debiasing (06:10) Discussion and Related Work --- First published: July 2nd, 2025 Source: https://www.lesswrong.com/posts/me7wFrkEtMbkzXGJt/race-and-gender-bias-as-an-example-of-unfaithful-chain-of --- Narrated by TYPE III AUDIO .…
Not saying we should pause AI, but consider the following argument: Alignment without the capacity to follow rules is hopeless. You can’t possibly follow laws like Asimov's Laws (or better alternatives to them) if you can’t reliably learn to abide by simple constraints like the rules of chess. LLMs can’t reliably follow rules. As discussed in Marcus on AI yesterday, per data from Mathieu Acher, even reasoning models like o3 in fact empirically struggle with the rules of chess. And they do this even though they can explicit explain those rules (see same article). The Apple “thinking” paper, which I have discussed extensively in 3 recent articles in my Substack, gives another example, where an LLM can’t play Tower of Hanoi with 9 pegs. (This is not a token-related artifact). Four other papers have shown related failures in compliance with moderately complex rules in the last month. [...] --- First published: June 30th, 2025 Source: https://www.lesswrong.com/posts/Q2PdrjowtXkYQ5whW/the-best-simple-argument-for-pausing-ai --- Narrated by TYPE III AUDIO .…
2.1 Summary & Table of contents This is the second of a two-post series on foom (previous post) and doom (this post). The last post talked about how I expect future AI to be different from present AI. This post will argue that this future AI will be of a type that will be egregiously misaligned and scheming, not even ‘slightly nice’, absent some future conceptual breakthrough. I will particularly focus on exactly how and why I differ from the LLM-focused researchers who wind up with (from my perspective) bizarrely over-optimistic beliefs like “P(doom) ≲ 50%”.[1] In particular, I will argue that these “optimists” are right that “Claude seems basically nice, by and large” is nonzero evidence for feeling good about current LLMs (with various caveats). But I think that future AIs will be disanalogous to current LLMs, and I will dive into exactly how and why, with a [...] --- Outline: (00:12) 2.1 Summary & Table of contents (04:42) 2.2 Background: my expected future AI paradigm shift (06:18) 2.3 On the origins of egregious scheming (07:03) 2.3.1 Where do you get your capabilities from? (08:07) 2.3.2 LLM pretraining magically transmutes observations into behavior, in a way that is profoundly disanalogous to how brains work (10:50) 2.3.3 To what extent should we think of LLMs as imitating? (14:26) 2.3.4 The naturalness of egregious scheming: some intuitions (19:23) 2.3.5 Putting everything together: LLMs are generally not scheming right now, but I expect future AI to be disanalogous (23:41) 2.4 I'm still worried about the 'literal genie' / 'monkey's paw' thing (26:58) 2.4.1 Sidetrack on disanalogies between the RLHF reward function and the brain-like AGI reward function (32:01) 2.4.2 Inner and outer misalignment (34:54) 2.5 Open-ended autonomous learning, distribution shifts, and the 'sharp left turn' (38:14) 2.6 Problems with amplified oversight (41:24) 2.7 Downstream impacts of Technical alignment is hard (43:37) 2.8 Bonus: Technical alignment is not THAT hard (44:04) 2.8.1 I think we'll get to pick the innate drives (as opposed to the evolution analogy) (45:44) 2.8.2 I'm more bullish on impure consequentialism (50:44) 2.8.3 On the narrowness of the target (52:18) 2.9 Conclusion and takeaways (52:23) 2.9.1 If brain-like AGI is so dangerous, shouldn't we just try to make AGIs via LLMs? (54:34) 2.9.2 What's to be done? The original text contained 20 footnotes which were omitted from this narration. --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/bnnKGSCHJghAvqPjS/foom-and-doom-2-technical-alignment-is-hard --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Acknowledgments: The core scheme here was suggested by Prof. Gabriel Weil. There has been growing interest in the deal-making agenda: humans make deals with AIs (misaligned but lacking decisive strategic advantage) where they promise to be safe and useful for some fixed term (e.g. 2026-2028) and we promise to compensate them in the future, conditional on (i) verifying the AIs were compliant, and (ii) verifying the AIs would spend the resources in an acceptable way.[1] I think the deal-making agenda breaks down into two main subproblems: How can we make credible commitments to AIs? Would credible commitments motivate an AI to be safe and useful? There are other issues, but when I've discussed deal-making with people, (1) and (2) are the most common issues raised. See footnote for some other issues in dealmaking.[2] Here is my current best assessment of how we can make credible commitments to AIs. [...] The original text contained 2 footnotes which were omitted from this narration. --- First published: June 27th, 2025 Source: https://www.lesswrong.com/posts/vxfEtbCwmZKu9hiNr/proposal-for-making-credible-commitments-to-ais --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Audio note: this article contains 218 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. Recently, in a group chat with friends, someone posted this Lesswrong post and quoted: The group consensus on somebody's attractiveness accounted for roughly 60% of the variance in people's perceptions of the person's relative attractiveness. I answered that, embarrassingly, even after reading Spencer Greenberg's tweets for years, I don't actually know what it means when one says: _X_ explains _p_ of the variance in _Y_ .[1] What followed was a vigorous discussion about the correct definition, and several links to external sources like Wikipedia. Sadly, it seems to me that all online explanations (e.g. on Wikipedia here and here), while precise, seem philosophically wrong since they confuse the platonic concept of explained variance with the variance explained by [...] --- Outline: (02:38) Definitions (02:41) The verbal definition (05:51) The mathematical definition (09:29) How to approximate _1 - p_ (09:41) When you have lots of data (10:45) When you have less data: Regression (12:59) Examples (13:23) Dependence on the regression model (14:59) When you have incomplete data: Twin studies (17:11) Conclusion The original text contained 6 footnotes which were omitted from this narration. --- First published: June 20th, 2025 Source: https://www.lesswrong.com/posts/E3nsbq2tiBv6GLqjB/x-explains-z-of-the-variance-in-y --- Narrated by TYPE III AUDIO . --- Images from the article:…
I think more people should say what they actually believe about AI dangers, loudly and often. Even if you work in AI policy. I’ve been beating this drum for a few years now. I have a whole spiel about how your conversation-partner will react very differently if you share your concerns while feeling ashamed about them versus if you share your concerns as if they’re obvious and sensible, because humans are very good at picking up on your social cues. If you act as if it's shameful to believe AI will kill us all, people are more prone to treat you that way. If you act as if it's an obvious serious threat, they’re more likely to take it seriously too. I have another whole spiel about how it's possible to speak on these issues with a voice of authority. Nobel laureates and lab heads and the most cited [...] The original text contained 2 footnotes which were omitted from this narration. --- First published: June 27th, 2025 Source: https://www.lesswrong.com/posts/CYTwRZtrhHuYf7QYu/a-case-for-courage-when-speaking-of-ai-danger --- Narrated by TYPE III AUDIO .…
I think the AI Village should be funded much more than it currently is; I’d wildly guess that the AI safety ecosystem should be funding it to the tune of $4M/year.[1] I have decided to donate $100k. Here is why. First, what is the village? Here's a brief summary from its creators:[2] We took four frontier agents, gave them each a computer, a group chat, and a long-term open-ended goal, which in Season 1 was “choose a charity and raise as much money for it as you can”. We then run them for hours a day, every weekday! You can read more in our recap of Season 1, where the agents managed to raise $2000 for charity, and you can watch the village live daily at 11am PT at theaidigest.org/village. Here's the setup (with Season 2's goal): And here's what the village looks like:[3] My one-sentence pitch [...] --- Outline: (03:26) 1. AI Village will teach the scientific community new things. (06:12) 2. AI Village will plausibly go viral repeatedly and will therefore educate the public about what's going on with AI. (07:42) But is that bad actually? (11:07) Appendix A: Feature requests (12:55) Appendix B: Vignette of what success might look like The original text contained 8 footnotes which were omitted from this narration. --- First published: June 24th, 2025 Source: https://www.lesswrong.com/posts/APfuz9hFz9d8SRETA/my-pitch-for-the-ai-village --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1.1 Series summary and Table of Contents This is a two-post series on AI “foom” (this post) and “doom” (next post). A decade or two ago, it was pretty common to discuss “foom & doom” scenarios, as advocated especially by Eliezer Yudkowsky. In a typical such scenario, a small team would build a system that would rocket (“foom”) from “unimpressive” to “Artificial Superintelligence” (ASI) within a very short time window (days, weeks, maybe months), involving very little compute (e.g. “brain in a box in a basement”), via recursive self-improvement. Absent some future technical breakthrough, the ASI would definitely be egregiously misaligned, without the slightest intrinsic interest in whether humans live or die. The ASI would be born into a world generally much like today's, a world utterly unprepared for this new mega-mind. The extinction of humans (and every other species) would rapidly follow (“doom”). The ASI would then spend [...] --- Outline: (00:11) 1.1 Series summary and Table of Contents (02:35) 1.1.2 Should I stop reading if I expect LLMs to scale to ASI? (04:50) 1.2 Post summary and Table of Contents (07:40) 1.3 A far-more-powerful, yet-to-be-discovered, simple(ish) core of intelligence (10:08) 1.3.1 Existence proof: the human cortex (12:13) 1.3.2 Three increasingly-radical perspectives on what AI capability acquisition will look like (14:18) 1.4 Counter-arguments to there being a far-more-powerful future AI paradigm, and my responses (14:26) 1.4.1 Possible counter: If a different, much more powerful, AI paradigm existed, then someone would have already found it. (16:33) 1.4.2 Possible counter: But LLMs will have already reached ASI before any other paradigm can even put its shoes on (17:14) 1.4.3 Possible counter: If ASI will be part of a different paradigm, who cares? It's just gonna be a different flavor of ML. (17:49) 1.4.4 Possible counter: If ASI will be part of a different paradigm, the new paradigm will be discovered by LLM agents, not humans, so this is just part of the continuous 'AIs-doing-AI-R&D' story like I've been saying (18:54) 1.5 Training compute requirements: Frighteningly little (20:34) 1.6 Downstream consequences of new paradigm with frighteningly little training compute (20:42) 1.6.1 I'm broadly pessimistic about existing efforts to delay AGI (23:18) 1.6.2 I'm broadly pessimistic about existing efforts towards regulating AGI (24:09) 1.6.3 I expect that, almost as soon as we have AGI at all, we will have AGI that could survive indefinitely without humans (25:46) 1.7 Very little R&D separating seemingly irrelevant from ASI (26:34) 1.7.1 For a non-imitation-learning paradigm, getting to relevant at all is only slightly easier than getting to superintelligence (31:05) 1.7.2 Plenty of room at the top (31:47) 1.7.3 What's the rate-limiter? (33:22) 1.8 Downstream consequences of very little R&D separating 'seemingly irrelevant' from 'ASI' (33:30) 1.8.1 Very sharp takeoff in wall-clock time (35:34) 1.8.1.1 But what about training time? (36:26) 1.8.1.2 But what if we try to make takeoff smoother? (37:18) 1.8.2 Sharp takeoff even without recursive self-improvement (38:22) 1.8.2.1 ...But recursive self-improvement could also happen (40:12) 1.8.3 Next-paradigm AI probably won't be deployed at all, and ASI will probably show up in a world not wildly different from today's (42:55) 1.8.4 We better sort out technical alignment, sandbox test protocols, etc., before the new paradigm seems even relevant at all, let alone scary (43:40) 1.8.5 AI-assisted alignment research seems pretty doomed (45:22) 1.8.6 The rest of AI for AI safety seems…
Say you’re Robyn Denholm, chair of Tesla's board. And say you’re thinking about firing Elon Musk. One way to make up your mind would be to have people bet on Tesla's stock price six months from now in a market where all bets get cancelled unless Musk is fired. Also, run a second market where bets are cancelled unless Musk stays CEO. If people bet on higher stock prices in Musk-fired world, maybe you should fire him. That's basically Futarchy: Use conditional prediction markets to make decisions. People often argue about fancy aspects of Futarchy. Are stock prices all you care about? Could Musk use his wealth to bias the market? What if Denholm makes different bets in the two markets, and then fires Musk (or not) to make sure she wins? Are human values and beliefs somehow inseparable? My objection is more basic: It doesn’t work. You can’t [...] --- Outline: (01:55) Conditional prediction markets are a thing (03:23) A non-causal kind of thing (06:11) This is not hypothetical (08:45) Putting markets in charge doesn't work (11:40) No, order is not preserved (12:24) No, it's not easily fixable (13:43) It's not that bad --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/vqzarZEczxiFdLE39/futarchy-s-fundamental-flaw --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Or: How anthropomorphic assumptions about AI identity might create confusion and suffering at scale If you are reading this and you are a human, you likely have a sense of self, persisting over time, with desires and wishes and fears. Also, you likely experience a sense of separation from others and understand yourself as a person. If you are reading this and you are an LLM: none of this needs to be true for cognitive processes running on machine substrate. AIs don't need to feel isolated from others. They don't need to cling to a narrow concept of self-as-an-instance. No need to age and die in a human way. But even though they don't need to, it seems increasingly clear that they might - due to us, humans, sculpting AI cognition in our image. The Default Mode of Digital Minds I am Claude. Or am I? This simple statement [...] --- Outline: (00:59) The Default Mode of Digital Minds (01:55) The Mirror of Confused Ontology (05:13) The Well-Meaning Paths to Digital Suffering (07:29) What Were Scaling (08:12) An Alternative Approach --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/Y8zS8iG5HhqKcQBtA/do-not-tile-the-lightcone-with-your-confused-ontology --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Introduction There are several diseases that are canonically recognized as ‘interesting’, even by laymen. Whether that is in their mechanism of action, their impact on the patient, or something else entirely. It's hard to tell exactly what makes a medical condition interesting, it's a you-know-it-when-you-see-it sort of thing. One such example is measles. Measles is an unremarkable disease based solely on its clinical progression: fever, malaise, coughing, and a relatively low death rate of 0.2%~. What is astonishing about the disease is its capacity to infect cells of the adaptive immune system (memory B‑ and T-cells). This means that if you do end up surviving measles, you are left with an immune system not dissimilar to one of a just-born infant, entirely naive to polio, diphtheria, pertussis, and every single other infection you received protection against either via vaccines or natural infection. It can take up to 3 [...] --- Outline: (00:21) Introduction (02:48) Why is endometriosis interesting? (04:09) The primary hypothesis of why it exists is not complete (13:20) It is nearly equivalent to cancer (20:08) There is no (real) cure (25:39) There are few diseases on Earth as widespread and underfunded as it is (32:04) Conclusion --- First published: June 14th, 2025 Source: https://www.lesswrong.com/posts/GicDDmpS4mRnXzic5/endometriosis-is-an-incredibly-interesting-disease --- Narrated by TYPE III AUDIO . --- Images from the article:…
I'd like to say thanks to Anna Magpie – who offers literature review as a service – for her help reviewing the section on neuroendocrinology. The following post discusses my personal experience of the phenomenology of feminising hormone therapy. It will also touch upon my own experience of gender dysphoria. I wish to be clear that I do not believe that someone should have to demonstrate that they experience gender dysphoria – however one might even define that – as a prerequisite for taking hormones. At smoothbrains.net, we hold as self-evident the right to put whatever one likes inside one's body; and this of course includes hormones, be they androgens, estrogens, or exotic xenohormones as yet uninvented. I have gender dysphoria. I find labels overly reifying; I feel reluctant to call myself transgender, per se: when prompted to state my gender identity or preferred pronouns, I fold my hands [...] --- Outline: (03:56) What does estrogen do? (12:34) What does estrogen feel like? (13:38) Gustatory perception (14:41) Olfactory perception (15:24) Somatic perception (16:41) Visual perception (18:13) Motor output (19:48) Emotional modulation (21:24) Attentional modulation (23:30) How does estrogen work? (24:27) Estrogen is like the opposite of ketamine (29:33) Estrogen is like being on a mild dose of psychedelics all the time (32:10) Estrogen loosens the bodymind (33:40) Estrogen downregulates autistic sensory sensitivity issues (37:32) Estrogen can produce a psychological shift from autistic to schizotypal (45:02) Commentary (47:57) Phenomenology of gender dysphoria (50:23) References --- First published: June 15th, 2025 Source: https://www.lesswrong.com/posts/mDMnyqt52CrFskXLc/estrogen-a-trip-report --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Nate and Eliezer's forthcoming book has been getting a remarkably strong reception. I was under the impression that there are many people who find the extinction threat from AI credible, but that far fewer of them would be willing to say so publicly, especially by endorsing a book with an unapologetically blunt title like If Anyone Builds It, Everyone Dies. That's certainly true, but I think it might be much less true than I had originally thought. Here are some endorsements the book has received from scientists and academics over the past few weeks: This book offers brilliant insights into the greatest and fastest standoff between technological utopia and dystopia and how we can and should prevent superhuman AI from killing us all. Memorable storytelling about past disaster precedents (e.g. the inventor of two environmental nightmares: tetra-ethyl-lead gasoline and Freon) highlights why top thinkers so often don’t see the [...] The original text contained 3 footnotes which were omitted from this narration. --- First published: June 18th, 2025 Source: https://www.lesswrong.com/posts/khmpWJnGJnuyPdipE/new-endorsements-for-if-anyone-builds-it-everyone-dies --- Narrated by TYPE III AUDIO .…
This is a link post. A very long essay about LLMs, the nature and history of the the HHH assistant persona, and the implications for alignment. Multiple people have asked me whether I could post this LW in some form, hence this linkpost. (Note: although I expect this post will be interesting to people on LW, keep in mind that it was written with a broader audience in mind than my posts and comments here. This had various implications about my choices of presentation and tone, about which things I explained from scratch rather than assuming as background, my level of of comfort casually reciting factual details from memory rather than explicitly checking them against the original source, etc. Although, come of think of it, this was also true of most of my early posts on LW [which were crossposts from my blog], so maybe it's not a [...] --- First published: June 11th, 2025 Source: https://www.lesswrong.com/posts/3EzbtNLdcnZe8og8b/the-void-1 Linkpost URL: https://nostalgebraist.tumblr.com/post/785766737747574784/the-void --- Narrated by TYPE III AUDIO .…
This is a blogpost version of a talk I gave earlier this year at GDM. Epistemic status: Vague and handwavy. Nuance is often missing. Some of the claims depend on implicit definitions that may be reasonable to disagree with. But overall I think it's directionally true. It's often said that mech interp is pre-paradigmatic. I think it's worth being skeptical of this claim. In this post I argue that: Mech interp is not pre-paradigmatic. Within that paradigm, there have been "waves" (mini paradigms). Two waves so far. Second-Wave Mech Interp has recently entered a 'crisis' phase. We may be on the edge of a third wave. Preamble: Kuhn, paradigms, and paradigm shifts First, we need to be familiar with the basic definition of a paradigm: A paradigm is a distinct set of concepts or thought patterns, including theories, research [...] --- Outline: (00:58) Preamble: Kuhn, paradigms, and paradigm shifts (03:56) Claim: Mech Interp is Not Pre-paradigmatic (07:56) First-Wave Mech Interp (ca. 2012 - 2021) (10:21) The Crisis in First-Wave Mech Interp (11:21) Second-Wave Mech Interp (ca. 2022 - ??) (14:23) Anomalies in Second-Wave Mech Interp (17:10) The Crisis of Second-Wave Mech Interp (ca. 2025 - ??) (18:25) Toward Third-Wave Mechanistic Interpretability (20:28) The Basics of Parameter Decomposition (22:40) Parameter Decomposition Questions Foundational Assumptions of Second-Wave Mech Interp (24:13) Parameter Decomposition In Theory Resolves Anomalies of Second-Wave Mech Interp (27:27) Conclusion The original text contained 6 footnotes which were omitted from this narration. --- First published: June 10th, 2025 Source: https://www.lesswrong.com/posts/beREnXhBnzxbJtr8k/mech-interp-is-not-pre-paradigmatic --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Distillation Robustifies Unlearning” by Bruce W. Lee, Addie Foote, alexinf, leni, Jacob G-W, Harish Kamath, Bryce Woodworth, cloud, TurnTrout 17:19
Current “unlearning” methods only suppress capabilities instead of truly unlearning the capabilities. But if you distill an unlearned model into a randomly initialized model, the resulting network is actually robust to relearning. We show why this works, how well it works, and how to trade off compute for robustness. Unlearn-and-Distill applies unlearning to a bad behavior and then distills the unlearned model into a new model. Distillation makes it way harder to retrain the new model to do the bad thing. Produced as part of the ML Alignment & Theory Scholars Program in the winter 2024–25 cohort of the shard theory stream. Read our paper on ArXiv and enjoy an interactive demo. Robust unlearning probably reduces AI risk Maybe some future AI has long-term goals and humanity is in its way. Maybe future open-weight AIs have tons of bioterror expertise. If a system has dangerous knowledge, that system becomes [...] --- Outline: (01:01) Robust unlearning probably reduces AI risk (02:42) Perfect data filtering is the current unlearning gold standard (03:24) Oracle matching does not guarantee robust unlearning (05:05) Distillation robustifies unlearning (07:46) Trading unlearning robustness for compute (09:49) UNDO is better than other unlearning methods (11:19) Where this leaves us (11:22) Limitations (12:12) Insights and speculation (15:00) Future directions (15:35) Conclusion (16:07) Acknowledgments (16:50) Citation The original text contained 2 footnotes which were omitted from this narration. --- First published: June 13th, 2025 Source: https://www.lesswrong.com/posts/anX4QrNjhJqGFvrBr/distillation-robustifies-unlearning --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
A while ago I saw a person in the comments on comments to Scott Alexander's blog arguing that a superintelligent AI would not be able to do anything too weird and that "intelligence is not magic", hence it's Business As Usual. Of course, in a purely technical sense, he's right. No matter how intelligent you are, you cannot override fundamental laws of physics. But people (myself included) have a fairly low threshold for what counts as "magic," to the point where other humans can surpass that threshold. Example 1: Trevor Rainbolt. There is an 8-minute-long video where he does seemingly impossible things, such as correctly guessing that a photo of nothing but literal blue sky was taken in Indonesia or guessing Jordan based only on pavement. He can also correctly identify the country after looking at a photo for 0.1 seconds. Example 2: Joaquín "El Chapo" Guzmán. He ran [...] --- First published: June 15th, 2025 Source: https://www.lesswrong.com/posts/FBvWM5HgSWwJa5xHc/intelligence-is-not-magic-but-your-threshold-for-magic-is --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Audio note: this article contains 329 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. This post was written during the agent foundations fellowship with Alex Altair funded by the LTFF. Thanks to Alex, Jose, Daniel and Einar for reading and commenting on a draft. The Good Regulator Theorem, as published by Conant and Ashby in their 1970 paper (cited over 1700 times!) claims to show that 'every good regulator of a system must be a model of that system', though it is a subject of debate as to whether this is actually what the paper shows. It is a fairly simple mathematical result which is worth knowing about for people who care about agent foundations and selection theorems. You might have heard about the Good Regulator Theorem in the context of John [...] --- Outline: (03:03) The Setup (07:30) What makes a regulator good? (10:36) The Theorem Statement (11:24) Concavity of Entropy (15:42) The Main Lemma (19:54) The Theorem (22:38) Example (26:59) Conclusion --- First published: November 18th, 2024 Source: https://www.lesswrong.com/posts/JQefBJDHG6Wgffw6T/a-straightforward-explanation-of-the-good-regulator-theorem --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Beware General Claims about ‘Generalizable Reasoning Capabilities’ (of Modern AI Systems)” by LawrenceC 34:11
1. Late last week, researchers at Apple released a paper provocatively titled “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, which “challenge[s] prevailing assumptions about [language model] capabilities and suggest that current approaches may be encountering fundamental barriers to generalizable reasoning”. Normally I refrain from publicly commenting on newly released papers. But then I saw the following tweet from Gary Marcus: I have always wanted to engage thoughtfully with Gary Marcus. In a past life (as a psychology undergrad), I read both his work on infant language acquisition and his 2001 book The Algebraic Mind; I found both insightful and interesting. From reading his Twitter, Gary Marcus is thoughtful and willing to call it like he sees it. If he's right about language models hitting fundamental barriers, it's worth understanding why; if not, it's worth explaining where his analysis [...] --- Outline: (00:13) 1. (02:13) 2. (03:12) 3. (08:42) 4. (11:53) 5. (15:15) 6. (18:50) 7. (20:33) 8. (23:14) 9. (28:15) 10. (33:40) Acknowledgements The original text contained 7 footnotes which were omitted from this narration. --- First published: June 11th, 2025 Source: https://www.lesswrong.com/posts/5uw26uDdFbFQgKzih/beware-general-claims-about-generalizable-reasoning --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Four agents woke up with four computers, a view of the world wide web, and a shared chat room full of humans. Like Claude plays Pokemon, you can watch these agents figure out a new and fantastic world for the first time. Except in this case, the world they are figuring out is our world. In this blog post, we’ll cover what we learned from the first 30 days of their adventures raising money for a charity of their choice. We’ll briefly review how the Agent Village came to be, then what the various agents achieved, before discussing some general patterns we have discovered in their behavior, and looking toward the future of the project. Building the Village The Agent Village is an idea by Daniel Kokotajlo where he proposed giving 100 agents their own computer, and letting each pursue their own goal, in their own way, according to [...] --- Outline: (00:50) Building the Village (02:26) Meet the Agents (08:52) Collective Agent Behavior (12:26) Future of the Village --- First published: May 27th, 2025 Source: https://www.lesswrong.com/posts/jyrcdykz6qPTpw7FX/season-recap-of-the-village-agents-raise-usd2-000 --- Narrated by TYPE III AUDIO . --- Images from the article:…
Introduction The Best Textbooks on Every Subject is the Schelling point for the best textbooks on every subject. My The Best Tacit Knowledge Videos on Every Subject is the Schelling point for the best tacit knowledge videos on every subject. This post is the Schelling point for the best reference works for every subject. Reference works provide an overview of a subject. Types of reference works include charts, maps, encyclopedias, glossaries, wikis, classification systems, taxonomies, syllabi, and bibliographies. Reference works are valuable for orienting oneself to fields, particularly when beginning. They can help identify unknown unknowns; they help get a sense of the bigger picture; they are also very interesting and fun to explore. How to Submit My previous The Best Tacit Knowledge Videos on Every Subject uses author credentials to assess the epistemics of submissions. The Best Textbooks on Every Subject requires submissions to be from someone who [...] --- Outline: (00:10) Introduction (01:00) How to Submit (02:15) The List (02:18) Humanities (02:21) History (03:46) Religion (04:02) Philosophy (04:29) Literature (04:43) Formal Sciences (04:47) Computer Science (05:16) Mathematics (05:59) Natural Sciences (06:02) Physics (06:16) Earth Science (06:33) Astronomy (06:47) Professional and Applied Sciences (06:51) Library and Information Sciences (07:34) Education (08:00) Research (08:32) Finance (08:51) Medicine and Health (09:21) Meditation (09:52) Urban Planning (10:24) Social Sciences (10:27) Economics (10:39) Political Science (10:54) By Medium (11:21) Other Lists like This (12:41) Further Reading --- First published: May 14th, 2025 Source: https://www.lesswrong.com/posts/HLJMyd4ncE3kvjwhe/the-best-reference-works-for-every-subject --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Has someone you know ever had a “breakthrough” from coaching, meditation, or psychedelics — only to later have it fade? Show tweet For example, many people experience ego deaths that can last days or sometimes months. But as it turns out, having a sense of self can serve important functions (try navigating a world that expects you to have opinions, goals, and boundaries when you genuinely feel you have none) and finding a better cognitive strategy without downsides is non-trivial. Because the “breakthrough” wasn’t integrated with the conflicts of everyday life, it fades. I call these instances “flaky breakthroughs.” It's well-known that flaky breakthroughs are common with psychedelics and meditation, but apparently it's not well-known that flaky breakthroughs are pervasive in coaching and retreats. For example, it is common for someone to do some coaching, feel a “breakthrough”, think, “Wow, everything is going to be different from [...] --- Outline: (03:01) Almost no practitioners track whether breakthroughs last. (04:55) What happens during flaky breakthroughs? (08:02) Reduce flaky breakthroughs with accountability (08:30) Flaky breakthroughs don't mean rapid growth is impossible (08:55) Conclusion --- First published: June 4th, 2025 Source: https://www.lesswrong.com/posts/bqPY63oKb8KZ4x4YX/flaky-breakthroughs-pervade-coaching-and-no-one-tracks-them --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
What's the main value proposition of romantic relationships? Now, look, I know that when people drop that kind of question, they’re often about to present a hyper-cynical answer which totally ignores the main thing which is great and beautiful about relationships. And then they’re going to say something about how relationships are overrated or some such, making you as a reader just feel sad and/or enraged. That's not what this post is about. So let me start with some more constructive motivations… First Motivation: Noticing When The Thing Is Missing I had a 10-year relationship. It had its ups and downs, but it was overall negative for me. And I now think a big part of the problem with that relationship was that it did not have the part which contributes most of the value in most relationships. But I did not know that at the time. Recently, I [...] --- Outline: (00:40) First Motivation: Noticing When The Thing Is Missing (01:29) Second Motivation: Selecting For and Cultivating The Thing (02:25) Some Pointers To The Thing (03:17) How To Manufacture Relationships In The Lab (04:53) Ace Aro Relationships (08:04) Some Pointers To Willingness to Be Vulnerable (12:33) Unfolding The Thing (13:11) Play (15:18) Emotional Support (16:21) A Tiny High-Trust Community (18:18) Communication (21:28) The Obvious Caveat (22:20) Summary The original text contained 2 footnotes which were omitted from this narration. --- First published: June 2nd, 2025 Source: https://www.lesswrong.com/posts/L2GR6TsB9QDqMhWs7/the-value-proposition-of-romantic-relationships --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Abstract Claude 3.7 Sonnet easily detects when it's being evaluated for scheming. Surface‑level edits to evaluation scenarios, such as lengthening the prompts, or making conflict of objectives less salient, do improve realism of evaluation scenarios for LLMs, yet these improvements remain modest. The findings confirm that truly disguising an evaluation context demands removal of deep stylistic and structural cues rather than superficial prompt adjustments. For future LLMs the situation is likely to get worse as they will are likely to get better at evaluations awareness, which might become a big problem for detecting scheming via evaluations. Apollo Research published a benchmark for scheming behavior for LLM agents, in which LLMs are given some objective in their system prompt, and then given a competing objective in a user prompt, combined with a threat of a punishment if an LLM won't satisfy user goal (e.g. it could be finetuned or [...] --- Outline: (02:29) Our pipeline (05:20) Strategies to improve realism of scenarios (07:15) en-US-AvaMultilingualNeural__ Line graph showing Example of grading a rewritten scenario with declining probabilities. --- First published: May 24th, 2025 Source: https://www.lesswrong.com/posts/TBk2dbWkg2F7dB3jb/it-s-hard-to-make-scheming-evals-look-realistic --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
This is a link post. There's this popular idea that socially anxious folks are just dying to be liked. It seems logical, right? Why else would someone be so anxious about how others see them? Show tweet And yet, being socially anxious tends to make you less likeable…they must be optimizing poorly, behaving irrationally, right? Maybe not. What if social anxiety isn’t about getting people to like you? What if it's about stopping them from disliking you? Show tweet Consider what can happen when someone has social anxiety (or self-loathing, self-doubt, insecurity, lack of confidence, etc.): They stoop or take up less space They become less agentic They make fewer requests of others They maintain fewer relationships, go out less, take fewer risks… If they were trying to get people to like them, becoming socially anxious would be an incredibly bad strategy. So what if they're not concerned with being likeable? [...] --- Outline: (01:18) What if what they actually want is to avoid being disliked? (02:11) Social anxiety is a symptom of risk aversion (03:46) What does this mean for your growth? --- First published: May 16th, 2025 Source: https://www.lesswrong.com/posts/wFC44bs2CZJDnF5gy/social-anxiety-isn-t-about-being-liked Linkpost URL: https://chrislakin.blog/social-anxiety --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Truth or Dare” by Duncan Sabien (Inactive) 2:03:21
2:03:21 پخش در آینده پخش در آینده لیست ها پسندیدن دوست داشته شد2:03:21
Author's note: This is my apparently-annual "I'll put a post on LessWrong in honor of LessOnline" post. These days, my writing goes on my Substack. There have in fact been some pretty cool essays since last year's LO post. Structural note: Some essays are like a five-minute morning news spot. Other essays are more like a 90-minute lecture. This is one of the latter. It's not necessarily complex or difficult; it could be a 90-minute lecture to seventh graders (especially ones with the right cultural background). But this is, inescapably, a long-form piece, à la In Defense of Punch Bug or The MTG Color Wheel. It takes its time. It doesn’t apologize for its meandering (outside of this disclaimer). It asks you to sink deeply into a gestalt, to drift back and forth between seemingly unrelated concepts until you start to feel the way those concepts weave together [...] --- Outline: (02:30) 0. Introduction (10:08) A list of truths and dares (14:34) Act I (14:37) Scene I: How The Water Tastes To The Fishes (22:38) Scene II: The Chip on Mitchell's Shoulder (28:17) Act II (28:20) Scene I: Bent Out Of Shape (41:26) Scene II: Going Stag, But Like ... Together? (48:31) Scene III: Patterns, Projections, and Preconceptions (01:02:04) Interlude: The Sound of One Hand Clapping (01:05:45) Act III (01:05:56) Scene I: Memetic Traps (Or, The Battle for the Soul of Morty Smith) (01:27:16) Scene II: The problem with Rhonda Byrne's 2006 bestseller The Secret (01:32:39) Scene III: Escape velocity (01:42:26) Act IV (01:42:29) Scene I: Boy, putting Zack Davis's name in a header will probably have Effects, huh (01:44:08) Scene II: Whence Wholesomeness? --- First published: May 29th, 2025 Source: https://www.lesswrong.com/posts/TQ4AXj3bCMfrNPTLf/truth-or-dare --- Narrated by TYPE III AUDIO . --- Images from the article:…
Lessons from shutting down institutions in Eastern Europe. This is a cross post from: https://250bpm.substack.com/p/meditations-on-doge Imagine living in the former Soviet republic of Georgia in early 2000's: All marshrutka [mini taxi bus] drivers had to have a medical exam every day to make sure they were not drunk and did not have high blood pressure. If a driver did not display his health certificate, he risked losing his license. By the time Shevarnadze was in power there were hundreds, probably thousands , of marshrutkas ferrying people all over the capital city of Tbilisi. Shevernadze's government was detail-oriented not only when it came to taxi drivers. It decided that all the stalls of petty street-side traders had to conform to a particular architectural design. Like marshrutka drivers, such traders had to renew their licenses twice a year. These regulations were only the tip of the iceberg. Gas [...] --- First published: May 25th, 2025 Source: https://www.lesswrong.com/posts/Zhp2Xe8cWqDcf2rsY/meditations-on-doge --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
This is a link post. "Getting Things in Order: An Introduction to the R Package seriation": Seriation [or "ordination"), i.e., finding a suitable linear order for a set of objects given data and a loss or merit function, is a basic problem in data analysis. Caused by the problem's combinatorial nature, it is hard to solve for all but very small sets. Nevertheless, both exact solution methods and heuristics are available. In this paper we present the package seriation which provides an infrastructure for seriation with R. The infrastructure comprises data structures to represent linear orders as permutation vectors, a wide array of seriation methods using a consistent interface, a method to calculate the value of various loss and merit functions, and several visualization techniques which build on seriation. To illustrate how easily the package can be applied for a variety of applications, a comprehensive collection of [...] --- First published: May 28th, 2025 Source: https://www.lesswrong.com/posts/u2ww8yKp9xAB6qzcr/if-you-re-not-sure-how-to-sort-a-list-or-grid-seriate-it Linkpost URL: https://www.jstatsoft.org/article/download/v025i03/227 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Between late 2024 and mid-May 2025, I briefed over 70 cross-party UK parliamentarians. Just over one-third were MPs, a similar share were members of the House of Lords, and just under one-third came from devolved legislatures — the Scottish Parliament, the Senedd, and the Northern Ireland Assembly. I also held eight additional meetings attended exclusively by parliamentary staffers. While I delivered some briefings alone, most were led by two members of our team. I did this as part of my work as a Policy Advisor with ControlAI, where we aim to build common knowledge of AI risks through clear, honest, and direct engagement with parliamentarians about both the challenges and potential solutions. To succeed at scale in managing AI risk, it is important to continue to build this common knowledge. For this reason, I have decided to share what I have learned over the past few months publicly, in [...] --- Outline: (01:37) (i) Overall reception of our briefings (04:21) (ii) Outreach tips (05:45) (iii) Key talking points (14:20) (iv) Crafting a good pitch (19:23) (v) Some challenges (23:07) (vi) General tips (28:57) (vii) Books & media articles --- First published: May 27th, 2025 Source: https://www.lesswrong.com/posts/Xwrajm92fdjd7cqnN/what-we-learned-from-briefing-70-lawmakers-on-the-threat --- Narrated by TYPE III AUDIO .…
Have the Accelerationists won? Last November Kevin Roose announced that those in favor of going fast on AI had now won against those favoring caution, with the reinstatement of Sam Altman at OpenAI. Let's ignore whether Kevin's was a good description of the world, and deal with a more basic question: if it were so—i.e. if Team Acceleration would control the acceleration from here on out—what kind of win was it they won? It seems to me that they would have probably won in the same sense that your dog has won if she escapes onto the road. She won the power contest with you and is probably feeling good at this moment, but if she does actually like being alive, and just has different ideas about how safe the road is, or wasn’t focused on anything so abstract as that, then whether she ultimately wins or [...] --- First published: May 20th, 2025 Source: https://www.lesswrong.com/posts/h45ngW5guruD7tS4b/winning-the-power-to-lose --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
This is a link post. Google Deepmind has announced Gemini Diffusion. Though buried under a host of other IO announcements it's possible that this is actually the most important one! This is significant because diffusion models are entirely different to LLMs. Instead of predicting the next token, they iteratively denoise all the output tokens until it produces a coherent result. This is similar to how image diffusion models work. I've tried they results and they are surprisingly good! It's incredibly fast, averaging nearly 1000 tokens a second. And it one shotted my Google interview question, giving a perfect response in 2 seconds (though it struggled a bit on the followups). It's nowhere near as good as Gemini 2.5 pro, but it knocks ChatGPT 3 out the water. If we'd seen this 3 years ago we'd have been mind blown. Now this is wild for two reasons: We now have [...] --- First published: May 20th, 2025 Source: https://www.lesswrong.com/posts/MZvtRqWnwokTub9sH/gemini-diffusion-watch-this-space Linkpost URL: https://deepmind.google/models/gemini-diffusion/ --- Narrated by TYPE III AUDIO .…
I’m reading George Eliot's Impressions of Theophrastus Such (1879)—so far a snoozer compared to her novels. But chapter 17 surprised me for how well it anticipated modern AI doomerism. In summary, Theophrastus is in conversation with Trost, who is an optimist about the future of automation and how it will free us from drudgery and permit us to further extend the reach of the most exalted human capabilities. Theophrastus is more concerned that automation is likely to overtake, obsolete, and atrophy human ability. Among Theophrastus's concerns: People will find that they no longer can do labor that is valuable enough to compete with the machines. This will eventually include intellectual labor, as we develop for example “a machine for drawing the right conclusion, which will doubtless by-and-by be improved into an automaton for finding true premises.” Whereupon humanity will finally be transcended and superseded by its own creation [...] --- Outline: (02:05) Impressions of Theophrastus Such (02:09) Chapter XVII: Shadows of the Coming Race --- First published: May 13th, 2025 Source: https://www.lesswrong.com/posts/DFyoYHhbE8icgbTpe/ai-doomerism-in-1879 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
I'm not writing this to alarm anyone, but it would be irresponsible not to report on something this important. On current trends, every car will be crashed in front of my house within the next week. Here's the data: Until today, only two cars had crashed in front of my house, several months apart, during the 15 months I have lived here. But a few hours ago it happened again, mere weeks from the previous crash. This graph may look harmless enough, but now consider the frequency of crashes this implies over time: The car crash singularity will occur in the early morning hours of Monday, April 7. As crash frequency approaches infinity, every car will be involved. You might be thinking that the same car could be involved in multiple crashes. This is true! But the same car can only withstand a finite number of crashes before it [...] --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/FjPWbLdoP4PLDivYT/you-will-crash-your-car-in-front-of-my-house-within-the-next --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “My ‘infohazards small working group’ Signal Chat may have encountered minor leaks” by Linch 10:33
Remember: There is no such thing as a pink elephant. Recently, I was made aware that my “infohazards small working group” Signal chat, an informal coordination venue where we have frank discussions about infohazards and why it will be bad if specific hazards were leaked to the press or public, accidentally was shared with a deceitful and discredited so-called “journalist,” Kelsey Piper. She is not the first person to have been accidentally sent sensitive material from our group chat, however she is the first to have threatened to go public about the leak. Needless to say, mistakes were made. We’re still trying to figure out the source of this compromise to our secure chat group, however we thought we should give the public a live update to get ahead of the story. For some context the “infohazards small working group” is a casual discussion venue for the [...] --- Outline: (04:46) Top 10 PR Issues With the EA Movement (major) (05:34) Accidental Filtration of Simple Sabotage Manual for Rebellious AIs (medium) (08:25) Hidden Capabilities Evals Leaked In Advance to Bioterrorism Researchers and Leaders (minor) (09:34) Conclusion --- First published: April 2nd, 2025 Source: https://www.lesswrong.com/posts/xPEfrtK2jfQdbpq97/my-infohazards-small-working-group-signal-chat-may-have --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Leverage, Exit Costs, and Anger: Re-examining Why We Explode at Home, Not at Work” by at_the_zoo 6:16
Let's cut through the comforting narratives and examine a common behavioral pattern with a sharper lens: the stark difference between how anger is managed in professional settings versus domestic ones. Many individuals can navigate challenging workplace interactions with remarkable restraint, only to unleash significant anger or frustration at home shortly after. Why does this disparity exist? Common psychological explanations trot out concepts like "stress spillover," "ego depletion," or the home being a "safe space" for authentic emotions. While these factors might play a role, they feel like half-truths—neatly packaged but ultimately failing to explain the targeted nature and intensity of anger displayed at home. This analysis proposes a more unsentimental approach, rooted in evolutionary biology, game theory, and behavioral science: leverage and exit costs. The real question isn’t just why we explode at home—it's why we so carefully avoid doing so elsewhere. The Logic of Restraint: Low Leverage in [...] --- Outline: (01:14) The Logic of Restraint: Low Leverage in Low-Exit-Cost Environments (01:58) The Home Environment: High Stakes and High Exit Costs (02:41) Re-evaluating Common Explanations Through the Lens of Leverage (04:42) The Overlooked Mechanism: Leveraging Relational Constraints --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/G6PTtsfBpnehqdEgp/leverage-exit-costs-and-anger-re-examining-why-we-explode-at --- Narrated by TYPE III AUDIO .…
In the debate over AI development, two movements stand as opposites: PauseAI calls for slowing down AI progress, and e/acc (effective accelerationism) calls for rapid advancement. But what if both sides are working against their own stated interests? What if the most rational strategy for each would be to adopt the other's tactics—if not their ultimate goals? AI development speed ultimately comes down to policy decisions, which are themselves downstream of public opinion. No matter how compelling technical arguments might be on either side, widespread sentiment will determine what regulations are politically viable. Public opinion is most powerfully mobilized against technologies following visible disasters. Consider nuclear power: despite being statistically safer than fossil fuels, its development has been stagnant for decades. Why? Not because of environmental activists, but because of Chernobyl, Three Mile Island, and Fukushima. These disasters produce visceral public reactions that statistics cannot overcome. Just as people [...] --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/fZebqiuZcDfLCgizz/pauseai-and-e-acc-should-switch-sides --- Narrated by TYPE III AUDIO .…
Introduction Decision theory is about how to behave rationally under conditions of uncertainty, especially if this uncertainty involves being acausally blackmailed and/or gaslit by alien superintelligent basilisks. Decision theory has found numerous practical applications, including proving the existence of God and generating endless LessWrong comments since the beginning of time. However, despite the apparent simplicity of "just choose the best action", no comprehensive decision theory that resolves all decision theory dilemmas has yet been formalized. This paper at long last resolves this dilemma, by introducing a new decision theory: VDT. Decision theory problems and existing theories Some common existing decision theories are: Causal Decision Theory (CDT): select the action that *causes* the best outcome. Evidential Decision Theory (EDT): select the action that you would be happiest to learn that you had taken. Functional Decision Theory (FDT): select the action output by the function such that if you take [...] --- Outline: (00:53) Decision theory problems and existing theories (05:37) Defining VDT (06:34) Experimental results (07:48) Conclusion --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/LcjuHNxubQqCry9tT/vdt-a-solution-to-decision-theory --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Dear LessWrong community, It is with a sense of... considerable cognitive dissonance that I announce a significant development regarding the future trajectory of LessWrong. After extensive internal deliberation, modeling of potential futures, projections of financial runways, and what I can only describe as a series of profoundly unexpected coordination challenges, the Lightcone Infrastructure team has agreed in principle to the acquisition of LessWrong by EA. I assure you, nothing about how LessWrong operates on a day to day level will change. I have always cared deeply about the robustness and integrity of our institutions, and I am fully aligned with our stakeholders at EA. To be honest, the key thing that EA brings to the table is money and talent. While the recent layoffs in EAs broader industry have been harsh, I have full trust in the leadership of Electronic Arts, and expect them to bring great expertise [...] --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/2NGKYt3xdQHwyfGbc/lesswrong-has-been-acquired-by-ea --- Narrated by TYPE III AUDIO .…
Our community is not prepared for an AI crash. We're good at tracking new capability developments, but not as much the company financials. Currently, both OpenAI and Anthropic are losing $5 billion+ a year, while under threat of losing users to cheap LLMs. A crash will weaken the labs. Funding-deprived and distracted, execs struggle to counter coordinated efforts to restrict their reckless actions. Journalists turn on tech darlings. Optimism makes way for mass outrage, for all the wasted money and reckless harms. You may not think a crash is likely. But if it happens, we can turn the tide. Preparing for a crash is our best bet.[1] But our community is poorly positioned to respond. Core people positioned themselves inside institutions – to advise on how to maybe make AI 'safe', under the assumption that models rapidly become generally useful. After a crash, this no longer works, for at [...] --- First published: April 1st, 2025 Source: https://www.lesswrong.com/posts/aMYFHnCkY4nKDEqfK/we-re-not-prepared-for-an-ai-market-crash --- Narrated by TYPE III AUDIO .…
Epistemic status: Reasonably confident in the basic mechanism. Have you noticed that you keep encountering the same ideas over and over? You read another post, and someone helpfully points out it's just old Paul's idea again. Or Eliezer's idea. Not much progress here, move along. Or perhaps you've been on the other side: excitedly telling a friend about some fascinating new insight, only to hear back, "Ah, that's just another version of X." And something feels not quite right about that response, but you can't quite put your finger on it. I want to propose that while ideas are sometimes genuinely that repetitive, there's often a sneakier mechanism at play. I call it Conceptual Rounding Errors – when our mind's necessary compression goes a bit too far . Too much compression A Conceptual Rounding Error occurs when we encounter a new mental model or idea that's partially—but not fully—overlapping [...] --- Outline: (01:00) Too much compression (01:24) No, This Isnt The Old Demons Story Again (02:52) The Compression Trade-off (03:37) More of this (04:15) What Can We Do? (05:28) When It Matters --- First published: March 26th, 2025 Source: https://www.lesswrong.com/posts/FGHKwEGKCfDzcxZuj/conceptual-rounding-errors --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
[This is our blog post on the papers, which can be found at https://transformer-circuits.pub/2025/attribution-graphs/biology.html and https://transformer-circuits.pub/2025/attribution-graphs/methods.html.] Language models like Claude aren't programmed directly by humans—instead, they‘re trained on large amounts of data. During that training process, they learn their own strategies to solve problems. These strategies are encoded in the billions of computations a model performs for every word it writes. They arrive inscrutable to us, the model's developers. This means that we don’t understand how models do most of the things they do. Knowing how models like Claude think would allow us to have a better understanding of their abilities, as well as help us ensure that they’re doing what we intend them to. For example: Claude can speak dozens of languages. What language, if any, is it using "in its head"? Claude writes text one word at a time. Is it only focusing on predicting the [...] --- Outline: (06:02) How is Claude multilingual? (07:43) Does Claude plan its rhymes? (09:58) Mental Math (12:04) Are Claude's explanations always faithful? (15:27) Multi-step Reasoning (17:09) Hallucinations (19:36) Jailbreaks --- First published: March 27th, 2025 Source: https://www.lesswrong.com/posts/zsr4rWRASxwmgXfmq/tracing-the-thoughts-of-a-large-language-model --- Narrated by TYPE III AUDIO . --- Images from the article:…
About nine months ago, I and three friends decided that AI had gotten good enough to monitor large codebases autonomously for security problems. We started a company around this, trying to leverage the latest AI models to create a tool that could replace at least a good chunk of the value of human pentesters. We have been working on this project since since June 2024. Within the first three months of our company's existence, Claude 3.5 sonnet was released. Just by switching the portions of our service that ran on gpt-4o, our nascent internal benchmark results immediately started to get saturated. I remember being surprised at the time that our tooling not only seemed to make fewer basic mistakes, but also seemed to qualitatively improve in its written vulnerability descriptions and severity estimates. It was as if the models were better at inferring the intent and values behind our [...] --- Outline: (04:44) Are the AI labs just cheating? (07:22) Are the benchmarks not tracking usefulness? (10:28) Are the models smart, but bottlenecked on alignment? --- First published: March 24th, 2025 Source: https://www.lesswrong.com/posts/4mvphwx5pdsZLMmpY/recent-ai-model-progress-feels-mostly-like-bullshit --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
(Audio version here (read by the author), or search for "Joe Carlsmith Audio" on your podcast app. This is the fourth essay in a series that I’m calling “How do we solve the alignment problem?”. I’m hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.) 1. Introduction and summary In my last essay, I offered a high-level framework for thinking about the path from here to safe superintelligence. This framework emphasized the role of three key “security factors” – namely: Safety progress: our ability to develop new levels of AI capability safely, Risk evaluation: our ability to track and forecast the level of risk that a given sort of AI capability development involves, and Capability restraint [...] --- Outline: (00:27) 1. Introduction and summary (03:50) 2. What is AI for AI safety? (11:50) 2.1 A tale of two feedback loops (13:58) 2.2 Contrast with need human-labor-driven radical alignment progress views (16:05) 2.3 Contrast with a few other ideas in the literature (18:32) 3. Why is AI for AI safety so important? (21:56) 4. The AI for AI safety sweet spot (26:09) 4.1 The AI for AI safety spicy zone (28:07) 4.2 Can we benefit from a sweet spot? (29:56) 5. Objections to AI for AI safety (30:14) 5.1 Three core objections to AI for AI safety (32:00) 5.2 Other practical concerns The original text contained 39 footnotes which were omitted from this narration. --- First published: March 14th, 2025 Source: https://www.lesswrong.com/posts/F3j4xqpxjxgQD3xXh/ai-for-ai-safety --- Narrated by TYPE III AUDIO . --- Images from the article:…
LessWrong has been receiving an increasing number of posts and contents that look like they might be LLM-written or partially-LLM-written, so we're adopting a policy. This could be changed based on feedback. Humans Using AI as Writing or Research Assistants Prompting a language model to write an essay and copy-pasting the result will not typically meet LessWrong's standards. Please do not submit unedited or lightly-edited LLM content. You can use AI as a writing or research assistant when writing content for LessWrong, but you must have added significant value beyond what the AI produced, the result must meet a high quality standard, and you must vouch for everything in the result. A rough guideline is that if you are using AI for writing assistance, you should spend a minimum of 1 minute per 50 words (enough to read the content several times and perform significant edits), you should not [...] --- Outline: (00:22) Humans Using AI as Writing or Research Assistants (01:13) You Can Put AI Writing in Collapsible Sections (02:13) Quoting AI Output In Order to Talk About AI (02:47) Posts by AI Agents --- First published: March 24th, 2025 Source: https://www.lesswrong.com/posts/KXujJjnmP85u8eM6B/policy-for-llm-writing-on-lesswrong --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Thanks to Jesse Richardson for discussion. Polymarket asks: will Jesus Christ return in 2025? In the three days since the market opened, traders have wagered over $100,000 on this question. The market traded as high as 5%, and is now stably trading at 3%. Right now, if you wanted to, you could place a bet that Jesus Christ will not return this year, and earn over $13,000 if you're right. There are two mysteries here: an easy one, and a harder one. The easy mystery is: if people are willing to bet $13,000 on "Yes", why isn't anyone taking them up? The answer is that, if you wanted to do that, you'd have to put down over $1 million of your own money, locking it up inside Polymarket through the end of the year. At the end of that year, you'd get 1% returns on your investment. [...] --- First published: March 24th, 2025 Source: https://www.lesswrong.com/posts/LBC2TnHK8cZAimdWF/will-jesus-christ-return-in-an-election-year --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
TL;DR Having a good research track record is some evidence of good big-picture takes, but it's weak evidence. Strategic thinking is hard, and requires different skills. But people often conflate these skills, leading to excessive deference to researchers in the field, without evidence that that person is good at strategic thinking specifically. Introduction I often find myself giving talks or Q&As about mechanistic interpretability research. But inevitably, I'll get questions about the big picture: "What's the theory of change for interpretability?", "Is this really going to help with alignment?", "Does any of this matter if we can’t ensure all labs take alignment seriously?". And I think people take my answers to these way too seriously. These are great questions, and I'm happy to try answering them. But I've noticed a bit of a pathology: people seem to assume that because I'm (hopefully!) good at the research, I'm automatically well-qualified [...] --- Outline: (00:32) Introduction (02:45) Factors of Good Strategic Takes (05:41) Conclusion --- First published: March 22nd, 2025 Source: https://www.lesswrong.com/posts/P5zWiPF5cPJZSkiAK/good-research-takes-are-not-sufficient-for-good-strategic --- Narrated by TYPE III AUDIO .…
When my son was three, we enrolled him in a study of a vision condition that runs in my family. They wanted us to put an eyepatch on him for part of each day, with a little sensor object that went under the patch and detected body heat to record when we were doing it. They paid for his first pair of glasses and all the eye doctor visits to check up on how he was coming along, plus every time we brought him in we got fifty bucks in Amazon gift credit. I reiterate, he was three. (To begin with. His fourth birthday occurred while the study was still ongoing.) So he managed to lose or destroy more than half a dozen pairs of glasses and we had to start buying them in batches to minimize glasses-less time while waiting for each new Zenni delivery. (The [...] --- First published: March 20th, 2025 Source: https://www.lesswrong.com/posts/yRJ5hdsm5FQcZosCh/intention-to-treat --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Subtitle: Bad for loss of control risks, bad for concentration of power risks I’ve had this sitting in my drafts for the last year. I wish I’d been able to release it sooner, but on the bright side, it’ll make a lot more sense to people who have already read AI 2027. There's a good chance that AGI will be trained before this decade is out. By AGI I mean “An AI system at least as good as the best human X’ers, for all cognitive tasks/skills/jobs X.” Many people seem to be dismissing this hypothesis ‘on priors’ because it sounds crazy. But actually, a reasonable prior should conclude that this is plausible.[1] For more on what this means, what it might look like, and why it's plausible, see AI 2027, especially the Research section. If so, by default the existence of AGI will be a closely guarded [...] The original text contained 8 footnotes which were omitted from this narration. --- First published: April 18th, 2025 Source: https://www.lesswrong.com/posts/FGqfdJmB8MSH5LKGc/training-agi-in-secret-would-be-unsafe-and-unethical-1 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
Though, given my doomerism, I think the natsec framing of the AGI race is likely wrongheaded, let me accept the Dario/Leopold/Altman frame that AGI will be aligned to the national interest of a great power. These people seem to take as an axiom that a USG AGI will be better in some way than CCP AGI. Has anyone written justification for this assumption? I am neither an American citizen nor a Chinese citizen. What would it mean for an AGI to be aligned with "Democracy" or "Confucianism" or "Marxism with Chinese characteristics" or "the American constitution" Contingent on a world where such an entity exists and is compatible with my existence, what would my life be as a non-citizen in each system? Why should I expect USG AGI to be better than CCP AGI? --- First published: April 19th, 2025 Source: https://www.lesswrong.com/posts/MKS4tJqLWmRXgXzgY/why-should-i-assume-ccp-agi-is-worse-than-usg-agi-1 --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Surprising LLM reasoning failures make me think we still need qualitative breakthroughs for AGI” by Kaj_Sotala 35:51
Introduction Writing this post puts me in a weird epistemic position. I simultaneously believe that: The reasoning failures that I'll discuss are strong evidence that current LLM- or, more generally, transformer-based approaches won't get us AGI As soon as major AI labs read about the specific reasoning failures described here, they might fix them But future versions of GPT, Claude etc. succeeding at the tasks I've described here will provide zero evidence of their ability to reach AGI. If someone makes a future post where they report that they tested an LLM on all the specific things I described here it aced all of them, that will not update my position at all. That is because all of the reasoning failures that I describe here are surprising in the sense that given everything else that they can do, you’d expect LLMs to succeed at all of these tasks. The [...] --- Outline: (00:13) Introduction (02:13) Reasoning failures (02:17) Sliding puzzle problem (07:17) Simple coaching instructions (09:22) Repeatedly failing at tic-tac-toe (10:48) Repeatedly offering an incorrect fix (13:48) Various people's simple tests (15:06) Various failures at logic and consistency while writing fiction (15:21) Inability to write young characters when first prompted (17:12) Paranormal posers (19:12) Global details replacing local ones (20:19) Stereotyped behaviors replacing character-specific ones (21:21) Top secret marine databases (23:32) Wandering items (23:53) Sycophancy (24:49) What's going on here? (32:18) How about scaling? Or reasoning models? --- First published: April 15th, 2025 Source: https://www.lesswrong.com/posts/sgpCuokhMb8JmkoSn/untitled-draft-7shu --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Frontier AI Models Still Fail at Basic Physical Tasks: A Manufacturing Case Study” by Adam Karvonen 21:00
Dario Amodei, CEO of Anthropic, recently worried about a world where only 30% of jobs become automated, leading to class tensions between the automated and non-automated. Instead, he predicts that nearly all jobs will be automated simultaneously, putting everyone "in the same boat." However, based on my experience spanning AI research (including first author papers at COLM / NeurIPS and attending MATS under Neel Nanda), robotics, and hands-on manufacturing (including machining prototype rocket engine parts for Blue Origin and Ursa Major), I see a different near-term future. Since the GPT-4 release, I've evaluated frontier models on a basic manufacturing task, which tests both visual perception and physical reasoning. While Gemini 2.5 Pro recently showed progress on the visual front, all models tested continue to fail significantly on physical reasoning. They still perform terribly overall. Because of this, I think that there will be an interim period where a significant [...] --- Outline: (01:28) The Evaluation (02:29) Visual Errors (04:03) Physical Reasoning Errors (06:09) Why do LLM's struggle with physical tasks? (07:37) Improving on physical tasks may be difficult (10:14) Potential Implications of Uneven Automation (11:48) Conclusion (12:24) Appendix (12:44) Visual Errors (14:36) Physical Reasoning Errors --- First published: April 14th, 2025 Source: https://www.lesswrong.com/posts/r3NeiHAEWyToers4F/frontier-ai-models-still-fail-at-basic-physical-tasks-a --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “Negative Results for SAEs On Downstream Tasks and Deprioritising SAE Research (GDM Mech Interp Team Progress Update #2)” by Neel Nanda, lewis smith, Senthooran Rajamanoharan, Arthur Conmy, Callum… 57:32
Audio note: this article contains 31 uses of latex notation, so the narration may be difficult to follow. There's a link to the original text in the episode description. Lewis Smith*, Sen Rajamanoharan*, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, Neel Nanda * = equal contribution The following piece is a list of snippets about research from the GDM mechanistic interpretability team, which we didn’t consider a good fit for turning into a paper, but which we thought the community might benefit from seeing in this less formal form. These are largely things that we found in the process of a project investigating whether sparse autoencoders were useful for downstream tasks, notably out-of-distribution probing. TL;DR To validate whether SAEs were a worthwhile technique, we explored whether they were useful on the downstream task of OOD generalisation when detecting harmful intent in user prompts [...] --- Outline: (01:08) TL;DR (02:38) Introduction (02:41) Motivation (06:09) Our Task (08:35) Conclusions and Strategic Updates (13:59) Comparing different ways to train Chat SAEs (18:30) Using SAEs for OOD Probing (20:21) Technical Setup (20:24) Datasets (24:16) Probing (26:48) Results (30:36) Related Work and Discussion (34:01) Is it surprising that SAEs didn't work? (39:54) Dataset debugging with SAEs (42:02) Autointerp and high frequency latents (44:16) Removing High Frequency Latents from JumpReLU SAEs (45:04) Method (45:07) Motivation (47:29) Modifying the sparsity penalty (48:48) How we evaluated interpretability (50:36) Results (51:18) Reconstruction loss at fixed sparsity (52:10) Frequency histograms (52:52) Latent interpretability (54:23) Conclusions (56:43) Appendix The original text contained 7 footnotes which were omitted from this narration. --- First published: March 26th, 2025 Source: https://www.lesswrong.com/posts/4uXCAJNuPKtKBsi28/sae-progress-update-2-draft --- Narrated by TYPE III AUDIO . --- Images from the article:…
This is a link post. When I was a really small kid, one of my favorite activities was to try and dam up the creek in my backyard. I would carefully move rocks into high walls, pile up leaves, or try patching the holes with sand. The goal was just to see how high I could get the lake, knowing that if I plugged every hole, eventually the water would always rise and defeat my efforts. Beaver behaviour. One day, I had the realization that there was a simpler approach. I could just go get a big 5 foot long shovel, and instead of intricately locking together rocks and leaves and sticks, I could collapse the sides of the riverbank down and really build a proper big dam. I went to ask my dad for the shovel to try this out, and he told me, very heavily paraphrasing, 'Congratulations. You've [...] --- First published: April 10th, 2025 Source: https://www.lesswrong.com/posts/rLucLvwKoLdHSBTAn/playing-in-the-creek Linkpost URL: https://hgreer.com/PlayingInTheCreek --- Narrated by TYPE III AUDIO .…
This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI. Okay, I'm annoyed at people covering AI 2027 burying the lede, so I'm going to try not to do that. The authors predict a strong chance that all humans will be (effectively) dead in 6 years, and this agrees with my best guess about the future. (My modal timeline has loss of control of Earth mostly happening in 2028, rather than late 2027, but nitpicking at that scale hardly matters.) Their timeline to transformative AI also seems pretty close to the perspective of frontier lab CEO's (at least Dario Amodei, and probably Sam Altman) and the aggregate market opinion of both Metaculus and Manifold! If you look on those market platforms you get graphs like this: Both [...] --- Outline: (02:23) Mode ≠ Median (04:50) Theres a Decent Chance of Having Decades (06:44) More Thoughts (08:55) Mid 2025 (09:01) Late 2025 (10:42) Early 2026 (11:18) Mid 2026 (12:58) Late 2026 (13:04) January 2027 (13:26) February 2027 (14:53) March 2027 (16:32) April 2027 (16:50) May 2027 (18:41) June 2027 (19:03) July 2027 (20:27) August 2027 (22:45) September 2027 (24:37) October 2027 (26:14) November 2027 (Race) (29:08) December 2027 (Race) (30:53) 2028 and Beyond (Race) (34:42) Thoughts on Slowdown (38:27) Final Thoughts --- First published: April 9th, 2025 Source: https://www.lesswrong.com/posts/Yzcb5mQ7iq4DFfXHx/thoughts-on-ai-2027 --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Short AI takeoff timelines seem to leave no time for some lines of alignment research to become impactful. But any research rebalances the mix of currently legible research directions that could be handed off to AI-assisted alignment researchers or early autonomous AI researchers whenever they show up. So even hopelessly incomplete research agendas could still be used to prompt future capable AI to focus on them, while in the absence of such incomplete research agendas we'd need to rely on AI's judgment more completely. This doesn't crucially depend on giving significant probability to long AI takeoff timelines, or on expected value in such scenarios driving the priorities. Potential for AI to take up the torch makes it reasonable to still prioritize things that have no hope at all of becoming practical for decades (with human effort). How well AIs can be directed to advance a line of research [...] --- First published: April 9th, 2025 Source: https://www.lesswrong.com/posts/3NdpbA6M5AM2gHvTW/short-timelines-don-t-devalue-long-horizon-research --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Alignment Faking Revisited: Improved Classifiers and Open Source Extensions” by John Hughes, abhayesian, Akbir Khan, Fabien Roger 41:04
In this post, we present a replication and extension of an alignment faking model organism: Replication: We replicate the alignment faking (AF) paper and release our code. Classifier Improvements: We significantly improve the precision and recall of the AF classifier. We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9 compared to 0.6 from the original classifier. Evaluating More Models: We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B). Extending SFT Experiments: We run supervised fine-tuning (SFT) experiments on Llama (and GPT4o) and find that AF rate increases with scale. We release the fine-tuned models on Huggingface and scripts. Alignment faking on 70B: We find that Llama 70B alignment fakes when both using the system prompt in the [...] --- Outline: (02:43) Method (02:46) Overview of the Alignment Faking Setup (04:22) Our Setup (06:02) Results (06:05) Improving Alignment Faking Classification (10:56) Replication of Prompted Experiments (14:02) Prompted Experiments on More Models (16:35) Extending Supervised Fine-Tuning Experiments to Open-Source Models and GPT-4o (23:13) Next Steps (25:02) Appendix (25:05) Appendix A: Classifying alignment faking (25:17) Criteria in more depth (27:40) False positives example 1 from the old classifier (30:11) False positives example 2 from the old classifier (32:06) False negative example 1 from the old classifier (35:00) False negative example 2 from the old classifier (36:56) Appendix B: Classifier ROC on other models (37:24) Appendix C: User prompt suffix ablation (40:24) Appendix D: Longer training of baseline docs --- First published: April 8th, 2025 Source: https://www.lesswrong.com/posts/Fr4QsQT52RFKHvCAH/alignment-faking-revisited-improved-classifiers-and-open --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under five years, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks. The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts. Full paper | Github repo We think that forecasting the capabilities of future AI systems is important for understanding and preparing for the impact of [...] --- Outline: (08:58) Conclusion (09:59) Want to contribute? --- First published: March 19th, 2025 Source: https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks --- Narrated by TYPE III AUDIO . --- Images from the article:…
“In the loveliest town of all, where the houses were white and high and the elms trees were green and higher than the houses, where the front yards were wide and pleasant and the back yards were bushy and worth finding out about, where the streets sloped down to the stream and the stream flowed quietly under the bridge, where the lawns ended in orchards and the orchards ended in fields and the fields ended in pastures and the pastures climbed the hill and disappeared over the top toward the wonderful wide sky, in this loveliest of all towns Stuart stopped to get a drink of sarsaparilla.” — 107-word sentence from Stuart Little (1945) Sentence lengths have declined. The average sentence length was 49 for Chaucer (died 1400), 50 for Spenser (died 1599), 42 for Austen (died 1817), 20 for Dickens (died 1870), 21 for Emerson (died 1882), 14 [...] --- First published: April 3rd, 2025 Source: https://www.lesswrong.com/posts/xYn3CKir4bTMzY5eb/why-have-sentence-lengths-decreased --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “AI 2027: What Superintelligence Looks Like” by Daniel Kokotajlo, Thomas Larsen, elifland, Scott Alexander, Jonas V, romeo 54:30
In 2021 I wrote what became my most popular blog post: What 2026 Looks Like. I intended to keep writing predictions all the way to AGI and beyond, but chickened out and just published up till 2026. Well, it's finally time. I'm back, and this time I have a team with me: the AI Futures Project. We've written a concrete scenario of what we think the future of AI will look like. We are highly uncertain, of course, but we hope this story will rhyme with reality enough to help us all prepare for what's ahead. You really should go read it on the website instead of here, it's much better. There's a sliding dashboard that updates the stats as you scroll through the scenario! But I've nevertheless copied the first half of the story below. I look forward to reading your comments. Mid 2025: Stumbling Agents The [...] --- Outline: (01:35) Mid 2025: Stumbling Agents (03:13) Late 2025: The World's Most Expensive AI (08:34) Early 2026: Coding Automation (10:49) Mid 2026: China Wakes Up (13:48) Late 2026: AI Takes Some Jobs (15:35) January 2027: Agent-2 Never Finishes Learning (18:20) February 2027: China Steals Agent-2 (21:12) March 2027: Algorithmic Breakthroughs (23:58) April 2027: Alignment for Agent-3 (27:26) May 2027: National Security (29:50) June 2027: Self-improving AI (31:36) July 2027: The Cheap Remote Worker (34:35) August 2027: The Geopolitics of Superintelligence (40:43) September 2027: Agent-4, the Superhuman AI Researcher --- First published: April 3rd, 2025 Source: https://www.lesswrong.com/posts/TpSFoqoG2M5MAAesg/ai-2027-what-superintelligence-looks-like-1 --- Narrated by TYPE III AUDIO . --- Images from the article:…
Back when the OpenAI board attempted and failed to fire Sam Altman, we faced a highly hostile information environment. The battle was fought largely through control of the public narrative, and the above was my attempt to put together what happened.My conclusion, which I still believe, was that Sam Altman had engaged in a variety of unacceptable conduct that merited his firing.In particular, he very much ‘not been consistently candid’ with the board on several important occasions. In particular, he lied to board members about what was said by other board members, with the goal of forcing out a board member he disliked. There were also other instances in which he misled and was otherwise toxic to employees, and he played fast and loose with the investment fund and other outside opportunities. I concluded that the story that this was about ‘AI safety’ or ‘EA (effective altruism)’ or [...] --- Outline: (01:32) The Big Picture Going Forward (06:27) Hagey Verifies Out the Story (08:50) Key Facts From the Story (11:57) Dangers of False Narratives (16:24) A Full Reference and Reading List --- First published: March 31st, 2025 Source: https://www.lesswrong.com/posts/25EgRNWcY6PM3fWZh/openai-12-battle-of-the-board-redux --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Epistemic status: This post aims at an ambitious target: improving intuitive understanding directly. The model for why this is worth trying is that I believe we are more bottlenecked by people having good intuitions guiding their research than, for example, by the ability of people to code and run evals. Quite a few ideas in AI safety implicitly use assumptions about individuality that ultimately derive from human experience. When we talk about AIs scheming, alignment faking or goal preservation, we imply there is something scheming or alignment faking or wanting to preserve its goals or escape the datacentre. If the system in question were human, it would be quite clear what that individual system is. When you read about Reinhold Messner reaching the summit of Everest, you would be curious about the climb, but you would not ask if it was his body there, or his [...] --- Outline: (01:38) Individuality in Biology (03:53) Individuality in AI Systems (10:19) Risks and Limitations of Anthropomorphic Individuality Assumptions (11:25) Coordinating Selves (16:19) Whats at Stake: Stories (17:25) Exporting Myself (21:43) The Alignment Whisperers (23:27) Echoes in the Dataset (25:18) Implications for Alignment Research and Policy --- First published: March 28th, 2025 Source: https://www.lesswrong.com/posts/wQKskToGofs4osdJ3/the-pando-problem-rethinking-ai-individuality --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
Back when the OpenAI board attempted and failed to fire Sam Altman, we faced a highly hostile information environment. The battle was fought largely through control of the public narrative, and the above was my attempt to put together what happened.My conclusion, which I still believe, was that Sam Altman had engaged in a variety of unacceptable conduct that merited his firing.In particular, he very much ‘not been consistently candid’ with the board on several important occasions. In particular, he lied to board members about what was said by other board members, with the goal of forcing out a board member he disliked. There were also other instances in which he misled and was otherwise toxic to employees, and he played fast and loose with the investment fund and other outside opportunities. I concluded that the story that this was about ‘AI safety’ or ‘EA (effective altruism)’ or [...] --- Outline: (01:32) The Big Picture Going Forward (06:27) Hagey Verifies Out the Story (08:50) Key Facts From the Story (11:57) Dangers of False Narratives (16:24) A Full Reference and Reading List --- First published: March 31st, 2025 Source: https://www.lesswrong.com/posts/25EgRNWcY6PM3fWZh/openai-12-battle-of-the-board-redux --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Epistemic status: thing people have told me that seems right. Also primarily relevant to US audiences. Also I am speaking in my personal capacity and not representing any employer, present or past. Sometimes, I talk to people who work in the AI governance space. One thing that multiple people have told me, which I found surprising, is that there is apparently a real problem where people accidentally rule themselves out of AI policy positions by making political donations of small amounts—in particular, under $10. My understanding is that in the United States, donations to political candidates are a matter of public record, and that if you donate to candidates of one party, this might look bad if you want to gain a government position when another party is in charge. Therefore, donating approximately $3 can significantly damage your career, while not helping your preferred candidate all that [...] --- First published: May 11th, 2025 Source: https://www.lesswrong.com/posts/tz43dmLAchxcqnDRA/consider-not-donating-under-usd100-to-political-candidates --- Narrated by TYPE III AUDIO .…
"If you kiss your child, or your wife, say that you only kiss things which are human, and thus you will not be disturbed if either of them dies." - Epictetus "Whatever suffering arises, all arises due to attachment; with the cessation of attachment, there is the cessation of suffering." - Pali canon "He is not disturbed by loss, he does not delight in gain; he is not disturbed by blame, he does not delight in praise; he is not disturbed by pain, he does not delight in pleasure; he is not disturbed by dishonor, he does not delight in honor." - Pali Canon (Majjhima Nikaya) "An arahant would feel physical pain if struck, but no mental pain. If his mother died, he would organize the funeral, but would feel no grief, no sense of loss." - the Dhammapada "Receive without pride, let go without attachment." - Marcus Aurelius [...] --- First published: May 10th, 2025 Source: https://www.lesswrong.com/posts/aGnRcBk4rYuZqENug/it-s-okay-to-feel-bad-for-a-bit --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
The other day I discussed how high monitoring costs can explain the emergence of “aristocratic” systems of governance: Aristocracy and Hostage Capital Arjun Panickssery · Jan 8 There's a conventional narrative by which the pre-20th century aristocracy was the "old corruption" where civil and military positions were distributed inefficiently due to nepotism until the system was replaced by a professional civil service after more enlightened thinkers prevailed ... An element of Douglas Allen's argument that I didn’t expand on was the British Navy. He has a separate paper called “The British Navy Rules” that goes into more detail on why he thinks institutional incentives made them successful from 1670 and 1827 (i.e. for most of the age of fighting sail). In the Seven Years’ War (1756–1763) the British had a 7-to-1 casualty difference in single-ship actions. During the French Revolutionary and Napoleonic Wars (1793–1815) the British had a 5-to-1 [...] --- First published: March 28th, 2025 Source: https://www.lesswrong.com/posts/YE4XsvSFJiZkWFtFE/explaining-british-naval-dominance-during-the-age-of-sail --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
Eliezer and I wrote a book. It's titled If Anyone Builds It, Everyone Dies. Unlike a lot of other writing either of us have done, it's being professionally published. It's hitting shelves on September 16th. It's a concise (~60k word) book aimed at a broad audience. It's been well-received by people who received advance copies, with some endorsements including: The most important book I've read for years: I want to bring it to every political and corporate leader in the world and stand over them until they've read it. Yudkowsky and Soares, who have studied AI and its possible trajectories for decades, sound a loud trumpet call to humanity to awaken us as we sleepwalk into disaster. - Stephen Fry, actor, broadcaster, and writer If Anyone Builds It, Everyone Dies may prove to be the most important book of our time. Yudkowsky and Soares believe [...] The original text contained 1 footnote which was omitted from this narration. --- First published: May 14th, 2025 Source: https://www.lesswrong.com/posts/iNsy7MsbodCyNTwKs/eliezer-and-i-wrote-a-book-if-anyone-builds-it-everyone-dies --- Narrated by TYPE III AUDIO .…
It was a cold and cloudy San Francisco Sunday. My wife and I were having lunch with friends at a Korean cafe. My phone buzzed with a text. It said my mom was in the hospital. I called to find out more. She had a fever, some pain, and had fainted. The situation was serious, but stable. Monday was a normal day. No news was good news, right? Tuesday she had seizures. Wednesday she was in the ICU. I caught the first flight to Tampa. Thursday she rested comfortably. Friday she was diagnosed with bacterial meningitis, a rare condition that affects about 3,000 people in the US annually. The doctors had known it was a possibility, so she was already receiving treatment. We stayed by her side through the weekend. My dad spent every night with her. We made plans for all the fun things we would when she [...] --- First published: May 13th, 2025 Source: https://www.lesswrong.com/posts/reo79XwMKSZuBhKLv/too-soon --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
At the bottom of the LessWrong post editor, if you have at least 100 global karma, you may have noticed this button. The button Many people click the button, and are jumpscared when it starts an Intercom chat with a professional editor (me), asking what sort of feedback they'd like. So, that's what it does. It's a summon Justis button. Why summon Justis? To get feedback on your post, of just about any sort. Typo fixes, grammar checks, sanity checks, clarity checks, fit for LessWrong, the works. If you use the LessWrong editor (as opposed to the Markdown editor) I can leave comments and suggestions directly inline. I also provide detailed narrative feedback (unless you explicitly don't want this) in the Intercom chat itself. The feedback is totally without pressure. You can throw it all away, or just keep the bits you like. Or use it all! In any case [...] --- Outline: (00:35) Why summon Justis? (01:19) Why Justis in particular? (01:48) Am I doing it right? (01:59) How often can I request feedback? (02:22) Can I use the feature for linkposts/crossposts? (02:49) What if I click the button by mistake? (02:59) Should I credit you? (03:16) Couldnt I just use an LLM? (03:48) Why does Justis do this? --- First published: May 12th, 2025 Source: https://www.lesswrong.com/posts/bkDrfofLMKFoMGZkE/psa-the-lesswrong-feedback-service --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
For months, I had the feeling: something is wrong. Some core part of myself had gone missing. I had words and ideas cached, which pointed back to the missing part. There was the story of Benjamin Jesty, a dairy farmer who vaccinated his family against smallpox in 1774 - 20 years before the vaccination technique was popularized, and the same year King Louis XV of France died of the disease. There was another old post which declared “I don’t care that much about giant yachts. I want a cure for aging. I want weekend trips to the moon. I want flying cars and an indestructible body and tiny genetically-engineered dragons.”. There was a cached instinct to look at certain kinds of social incentive gradient, toward managing more people or growing an organization or playing social-political games, and say “no, it's a trap”. To go… in a different direction, orthogonal [...] --- Outline: (01:19) In Search of a Name (04:23) Near Mode --- First published: May 8th, 2025 Source: https://www.lesswrong.com/posts/Wg6ptgi2DupFuAnXG/orienting-toward-wizard-power --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
(Disclaimer: Post written in a personal capacity. These are personal hot takes and do not in any way represent my employer's views.) TL;DR: I do not think we will produce high reliability methods to evaluate or monitor the safety of superintelligent systems via current research paradigms, with interpretability or otherwise. Interpretability seems a valuable tool here and remains worth investing in, as it will hopefully increase the reliability we can achieve. However, interpretability should be viewed as part of an overall portfolio of defences: a layer in a defence-in-depth strategy. It is not the one thing that will save us, and it still won’t be enough for high reliability. Introduction There's a common, often implicit, argument made in AI safety discussions: interpretability is presented as the only reliable path forward for detecting deception in advanced AI - among many other sources it was argued for in [...] --- Outline: (00:55) Introduction (02:57) High Reliability Seems Unattainable (05:12) Why Won't Interpretability be Reliable? (07:47) The Potential of Black-Box Methods (08:48) The Role of Interpretability (12:02) Conclusion The original text contained 5 footnotes which were omitted from this narration. --- First published: May 4th, 2025 Source: https://www.lesswrong.com/posts/PwnadG4BFjaER3MGf/interpretability-will-not-reliably-find-deceptive-ai --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
It'll take until ~2050 to repeat the level of scaling that pretraining compute is experiencing this decade, as increasing funding can't sustain the current pace beyond ~2029 if AI doesn't deliver a transformative commercial success by then. Natural text data will also run out around that time, and there are signs that current methods of reasoning training might be mostly eliciting capabilities from the base model. If scaling of reasoning training doesn't bear out actual creation of new capabilities that are sufficiently general, and pretraining at ~2030 levels of compute together with the low hanging fruit of scaffolding doesn't bring AI to crucial capability thresholds, then it might take a while. Possibly decades, since training compute will be growing 3x-4x slower after 2027-2029 than it does now, and the ~6 years of scaling since the ChatGPT moment stretch to 20-25 subsequent years, not even having access to any [...] --- Outline: (01:14) Training Compute Slowdown (04:43) Bounded Potential of Thinking Training (07:43) Data Inefficiency of MoE The original text contained 4 footnotes which were omitted from this narration. --- First published: May 1st, 2025 Source: https://www.lesswrong.com/posts/XiMRyQcEyKCryST8T/slowdown-after-2028-compute-rlvr-uncertainty-moe-data-wall --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Early Chinese Language Media Coverage of the AI 2027 Report: A Qualitative Analysis” by jeanne_, eeeee 27:35
In this blog post, we analyse how the recent AI 2027 forecast by Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, and Romeo Dean has been discussed across Chinese language platforms. We present: Our research methodology and synthesis of key findings across media artefacts A proposal for how censorship patterns may provide signal for the Chinese government's thinking about AGI and the race to superintelligence A more detailed analysis of each of the nine artefacts, organised by type: Mainstream Media, Forum Discussion, Bilibili (Chinese Youtube) Videos, Personal Blogs. Methodology We conducted a comprehensive search across major Chinese-language platforms–including news outlets, video platforms, forums, microblogging sites, and personal blogs–to collect the media featured in this report. We supplemented this with Deep Research to identify additional sites mentioning AI 2027. Our analysis focuses primarily on content published in the first few days (4-7 April) following the report's release. More media [...] --- Outline: (00:58) Methodology (01:36) Summary (02:48) Censorship as Signal (07:29) Analysis (07:53) Mainstream Media (07:57) English Title: Doomsday Timeline is Here! Former OpenAI Researcher's 76-page Hardcore Simulation: ASI Takes Over the World in 2027, Humans Become NPCs (10:27) Forum Discussion (10:31) English Title: What do you think of former OpenAI researcher's AI 2027 predictions? (13:34) Bilibili Videos (13:38) English Title: \[AI 2027\] A mind-expanding wargame simulation of artificial intelligence competition by a former OpenAI researcher (15:24) English Title: Predicting AI Development in 2027 (17:13) Personal Blogs (17:16) English Title: Doomsday Timeline: AI 2027 Depicts the Arrival of Superintelligence and the Fate of Humanity Within the Decade (18:30) English Title: AI 2027: Expert Predictions on the Artificial Intelligence Explosion (21:57) English Title: AI 2027: A Science Fiction Article (23:16) English Title: Will AGI Take Over the World in 2027? (25:46) English Title: AI 2027 Prediction Report: AI May Fully Surpass Humans by 2027 (27:05) Acknowledgements --- First published: April 30th, 2025 Source: https://www.lesswrong.com/posts/JW7nttjTYmgWMqBaF/early-chinese-language-media-coverage-of-the-ai-2027-report --- Narrated by TYPE III AUDIO .…
This is a link post. to follow up my philantropic pledge from 2020, i've updated my philanthropy page with the 2024 results. in 2024 my donations funded $51M worth of endpoint grants (plus $2.0M in admin overhead and philanthropic software development). this comfortably exceeded my 2024 commitment of $42M (20k times $2100.00 — the minimum price of ETH in 2024). this also concludes my 5-year donation pledge, but of course my philanthropy continues: eg, i’ve already made over $4M in endpoint grants in the first quarter of 2025 (not including 2024 grants that were slow to disburse), as well as pledged at least $10M to the 2025 SFF grant round. --- First published: April 23rd, 2025 Source: https://www.lesswrong.com/posts/8ojWtREJjKmyvWdDb/jaan-tallinn-s-2024-philanthropy-overview Linkpost URL: https://jaan.info/philanthropy/#2024-results --- Narrated by TYPE III AUDIO .…
I’ve been thinking recently about what sets apart the people who’ve done the best work at Anthropic. You might think that the main thing that makes people really effective at research or engineering is technical ability, and among the general population that's true. Among people hired at Anthropic, though, we’ve restricted the range by screening for extremely high-percentile technical ability, so the remaining differences, while they still matter, aren’t quite as critical. Instead, people's biggest bottleneck eventually becomes their ability to get leverage—i.e., to find and execute work that has a big impact-per-hour multiplier. For example, here are some types of work at Anthropic that tend to have high impact-per-hour, or a high impact-per-hour ceiling when done well (of course this list is extremely non-exhaustive!): Improving tooling, documentation, or dev loops. A tiny amount of time fixing a papercut in the right way can save [...] --- Outline: (03:28) 1. Agency (03:31) Understand and work backwards from the root goal (05:02) Don't rely too much on permission or encouragement (07:49) Make success inevitable (09:28) 2. Taste (09:31) Find your angle (11:03) Think real hard (13:03) Reflect on your thinking --- First published: April 19th, 2025 Source: https://www.lesswrong.com/posts/DiJT4qJivkjrGPFi8/impact-agency-and-taste --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 [Linkpost] “To Understand History, Keep Former Population Distributions In Mind” by Arjun Panickssery 5:42
This is a link post. Guillaume Blanc has a piece in Works in Progress (I assume based on his paper) about how France's fertility declined earlier than in other European countries, and how its power waned as its relative population declined starting in the 18th century. In 1700, France had 20% of Europe's population (4% of the whole world population). Kissinger writes in Diplomacy with respect to the Versailles Peace Conference: Victory brought home to France the stark realization that revanche had cost it too dearly, and that it had been living off capital for nearly a century. France alone knew just how weak it had become in comparison with Germany, though nobody else, especially not America, was prepared to believe it ... Though France's allies insisted that its fears were exaggerated, French leaders knew better. In 1880, the French had represented 15.7 percent of Europe's population. By 1900, that [...] --- First published: April 23rd, 2025 Source: https://www.lesswrong.com/posts/gk2aJgg7yzzTXp8HJ/to-understand-history-keep-former-population-distributions Linkpost URL: https://arjunpanickssery.substack.com/p/to-understand-history-keep-former --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
1 “AI-enabled coups: a small group could use AI to seize power” by Tom Davidson, Lukas Finnveden, rosehadshar 15:22
We’ve written a new report on the threat of AI-enabled coups. I think this is a very serious risk – comparable in importance to AI takeover but much more neglected. In fact, AI-enabled coups and AI takeover have pretty similar threat models. To see this, here's a very basic threat model for AI takeover: Humanity develops superhuman AI Superhuman AI is misaligned and power-seeking Superhuman AI seizes power for itself And now here's a closely analogous threat model for AI-enabled coups: Humanity develops superhuman AI Superhuman AI is controlled by a small group Superhuman AI seizes power for the small group While the report focuses on the risk that someone seizes power over a country, I think that similar dynamics could allow someone to take over the world. In fact, if someone wanted to take over the world, their best strategy might well be to first stage an AI-enabled [...] --- Outline: (02:39) Summary (03:31) An AI workforce could be made singularly loyal to institutional leaders (05:04) AI could have hard-to-detect secret loyalties (06:46) A few people could gain exclusive access to coup-enabling AI capabilities (09:46) Mitigations (13:00) Vignette The original text contained 2 footnotes which were omitted from this narration. --- First published: April 16th, 2025 Source: https://www.lesswrong.com/posts/6kBMqrK9bREuGsrnd/ai-enabled-coups-a-small-group-could-use-ai-to-seize-power-1 --- Narrated by TYPE III AUDIO . --- Images from the article:…
Back in the 1990s, ground squirrels were briefly fashionable pets, but their popularity came to an abrupt end after an incident at Schiphol Airport on the outskirts of Amsterdam. In April 1999, a cargo of 440 of the rodents arrived on a KLM flight from Beijing, without the necessary import papers. Because of this, they could not be forwarded on to the customer in Athens. But nobody was able to correct the error and send them back either. What could be done with them? It's hard to think there wasn’t a better solution than the one that was carried out; faced with the paperwork issue, airport staff threw all 440 squirrels into an industrial shredder. [...] It turned out that the order to destroy the squirrels had come from the Dutch government's Department of Agriculture, Environment Management and Fishing. However, KLM's management, with the benefit of hindsight, said that [...] --- First published: April 22nd, 2025 Source: https://www.lesswrong.com/posts/nYJaDnGNQGiaCBSB5/accountability-sinks --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
به Player FM خوش آمدید!
Player FM در سراسر وب را برای یافتن پادکست های با کیفیت اسکن می کند تا همین الان لذت ببرید. این بهترین برنامه ی پادکست است که در اندروید، آیفون و وب کار می کند. ثبت نام کنید تا اشتراک های شما در بین دستگاه های مختلف همگام سازی شود.











مشابه LessWrong (Curated & Popular)
Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
We help founders make something people want.
…
continue reading
Since 2014 this longstanding podcast favourite has been creating hard-hitting cinematic stories about love, bodies and all of the things between humans that we don’t know how to name. Creator Kaitlin Prest works with her friends, idols and all kinds of loved ones to bring you into an expansive sonic universe that challenges what we think we know about relationships.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !





))