Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Player FM - Internet Radio Done Right
13 subscribers
Checked 1d ago
اضافه شده در three سال پیش
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
مشابه LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
We help founders make something people want.
…
continue reading
Since 2014 this longstanding podcast favourite has been creating hard-hitting cinematic stories about love, bodies and all of the things between humans that we don’t know how to name. Creator Kaitlin Prest works with her friends, idols and all kinds of loved ones to bring you into an expansive sonic universe that challenges what we think we know about relationships.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !

))









پادکست هایی که ارزش شنیدن دارند
حمایت شده
S
Squid Game: The Official Podcast

Squid Game is back—and this time, the knives are out. In the thrilling Season 3 premiere, Player 456 is spiraling and a brutal round of hide-and-seek forces players to kill or be killed. Hosts Phil Yu and Kiera Please break down Gi-hun’s descent into vengeance, Guard 011’s daring betrayal of the Game, and the shocking moment players are forced to choose between murdering their friends… or dying. Then, Carlos Juico and Gavin Ruta from the Jumpers Jump podcast join us to unpack their wild theories for the season. Plus, Phil and Kiera face off in a high-stakes round of “Hot Sweet Potato.” SPOILER ALERT! Make sure you watch Squid Game Season 3 Episode 1 before listening on. Play one last time. IG - @SquidGameNetflix X (f.k.a. Twitter) - @SquidGame Check out more from Phil Yu @angryasianman , Kiera Please @kieraplease and the Jumpers Jump podcast Listen to more from Netflix Podcasts . Squid Game: The Official Podcast is produced by Netflix and The Mash-Up Americans.…
“Gradient Routing: Masking Gradients to Localize Computation in Neural Networks” by cloud, Jacob G-W, Evzen, Joseph Miller, TurnTrout
Manage episode 454603164 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
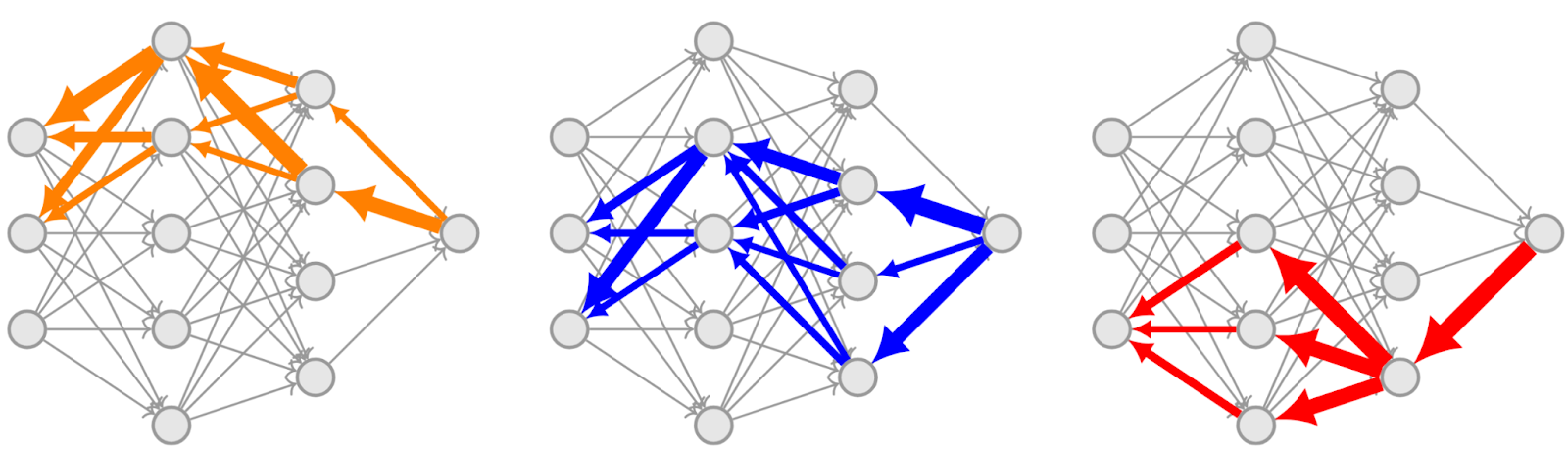
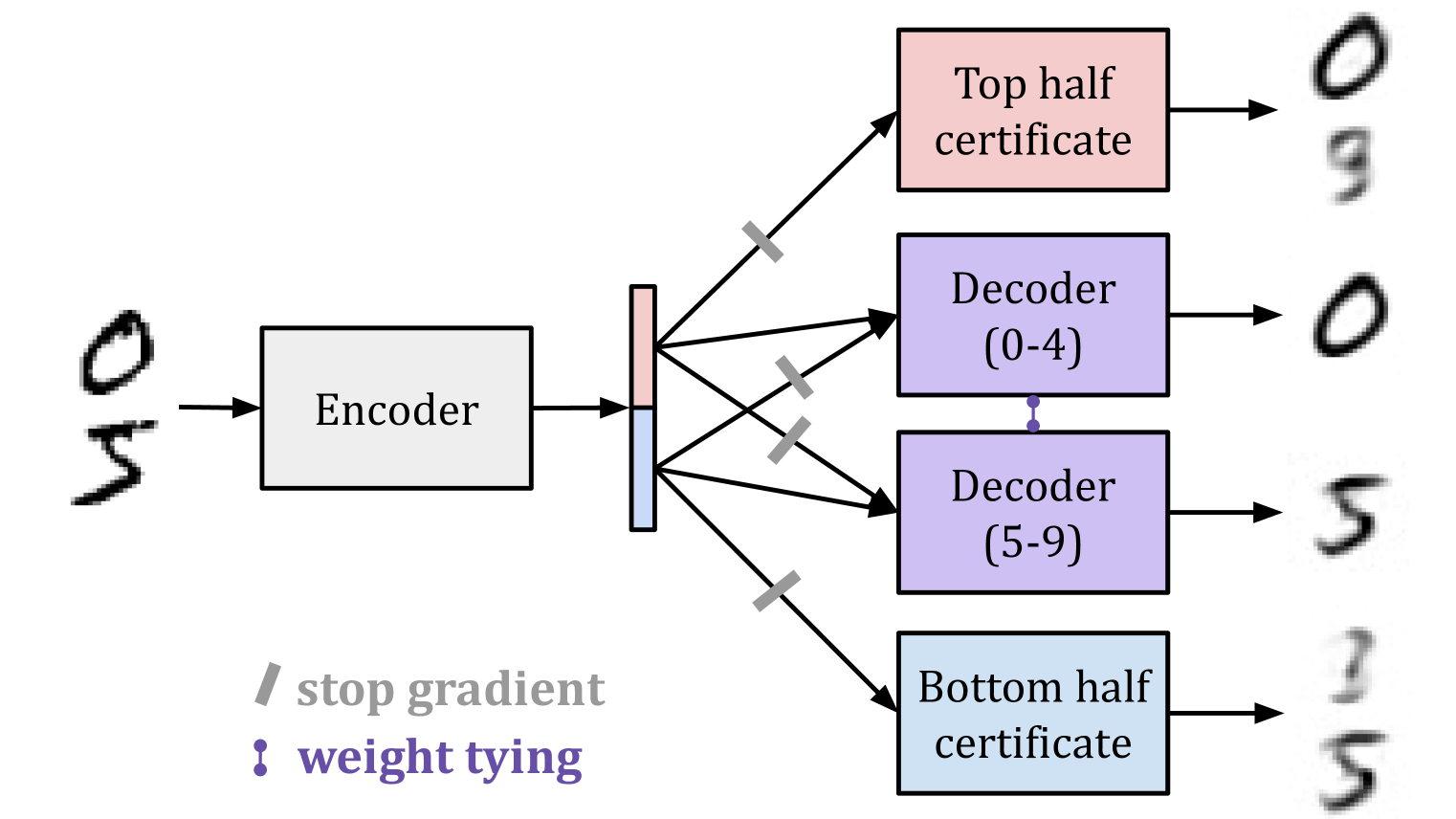
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
557 قسمت
Manage episode 454603164 series 3364760
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
557 قسمت
Tất cả các tập
×This essay is about shifts in risk taking towards the worship of jackpots and its broader societal implications. Imagine you are presented with this coin flip game. How many times do you flip it? At first glance the game feels like a money printer. The coin flip has positive expected value of twenty percent of your net worth per flip so you should flip the coin infinitely and eventually accumulate all of the wealth in the world. However, If we simulate twenty-five thousand people flipping this coin a thousand times, virtually all of them end up with approximately 0 dollars. The reason almost all outcomes go to zero is because of the multiplicative property of this repeated coin flip. Even though the expected value aka the arithmetic mean of the game is positive at a twenty percent gain per flip, the geometric mean is negative, meaning that the coin [...] --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/3xjgM7hcNznACRzBi/the-jackpot-age --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
Leo was born at 5am on the 20th May, at home (this was an accident but the experience has made me extremely homebirth-pilled). Before that, I was on the minimally-neurotic side when it came to expecting mothers: we purchased a bare minimum of baby stuff (diapers, baby wipes, a changing mat, hybrid car seat/stroller, baby bath, a few clothes), I didn’t do any parenting classes, I hadn’t even held a baby before. I’m pretty sure the youngest child I have had a prolonged interaction with besides Leo was two. I did read a couple books about babies so I wasn’t going in totally clueless (Cribsheet by Emily Oster, and The Science of Mom by Alice Callahan). I have never been that interested in other people's babies or young children but I correctly predicted that I’d be enchanted by my own baby (though naturally I can’t wait for him to [...] --- Outline: (02:05) Stuff I ended up buying and liking (04:13) Stuff I ended up buying and not liking (05:08) Babies are super time-consuming (06:22) Baby-wearing is almost magical (08:02) Breastfeeding is nontrivial (09:09) Your baby may refuse the bottle (09:37) Bathing a newborn was easier than expected (09:53) Babies love faces! (10:22) Leo isn't upset by loud noise (10:41) Probably X is normal (11:24) Consider having a kid (or ten)! --- First published: July 12th, 2025 Source: https://www.lesswrong.com/posts/vFfwBYDRYtWpyRbZK/surprises-and-learnings-from-almost-two-months-of-leo --- Narrated by TYPE III AUDIO . --- Images from the article:…
I can't count how many times I've heard variations on "I used Anki too for a while, but I got out of the habit." No one ever sticks with Anki. In my opinion, this is because no one knows how to use it correctly. In this guide, I will lay out my method of circumventing the canonical Anki death spiral, plus much advice for avoiding memorization mistakes, increasing retention, and such, based on my five years' experience using Anki. If you only have limited time/interest, only read Part I; it's most of the value of this guide! My Most Important Advice in Four Bullets 20 cards a day — Having too many cards and staggering review buildups is the main reason why no one ever sticks with Anki. Setting your review count to 20 daily (in deck settings) is the single most important thing you can do [...] --- Outline: (00:44) My Most Important Advice in Four Bullets (01:57) Part I: No One Ever Sticks With Anki (02:33) Too many cards (05:12) Too long cards (07:30) How to keep cards short -- Handles (10:10) How to keep cards short -- Levels (11:55) In 6 bullets (12:33) End of the most important part of the guide (13:09) Part II: Important Advice Other Than Sticking With Anki (13:15) Moderation (14:42) Three big memorization mistakes (15:12) Mistake 1: Too specific prompts (18:14) Mistake 2: Putting to-be-learned information in the prompt (24:07) Mistake 3: Memory shortcuts (28:27) Aside: Pushback to my approach (31:22) Part III: More on Breaking Things Down (31:47) Very short cards (33:56) Two-bullet cards (34:51) Long cards (37:05) Ankifying information thickets (39:23) Sequential breakdowns versus multiple levels of abstraction (40:56) Adding missing connections (43:56) Multiple redundant breakdowns (45:36) Part IV: Pro Tips If You Still Havent Had Enough (45:47) Save anything for ankification instantly (46:47) Fix your desired retention rate (47:38) Spaced reminders (48:51) Make your own card templates and types (52:14) In 5 bullets (52:47) Conclusion The original text contained 4 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/7Q7DPSk4iGFJd8DRk/an-opinionated-guide-to-using-anki-correctly --- Narrated by TYPE III AUDIO . --- Images from the article: astronomy" didn't really add any information but it was useful simply for splitting out a logical subset of information." style="max-width: 100%;" />…
I think the 2003 invasion of Iraq has some interesting lessons for the future of AI policy. (Epistemic status: I’ve read a bit about this, talked to AIs about it, and talked to one natsec professional about it who agreed with my analysis (and suggested some ideas that I included here), but I’m not an expert.) For context, the story is: Iraq was sort of a rogue state after invading Kuwait and then being repelled in 1990-91. After that, they violated the terms of the ceasefire, e.g. by ceasing to allow inspectors to verify that they weren't developing weapons of mass destruction (WMDs). (For context, they had previously developed biological and chemical weapons, and used chemical weapons in war against Iran and against various civilians and rebels). So the US was sanctioning and intermittently bombing them. After the war, it became clear that Iraq actually wasn’t producing [...] --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/PLZh4dcZxXmaNnkYE/lessons-from-the-iraq-war-about-ai-policy --- Narrated by TYPE III AUDIO .…
Written in an attempt to fulfill @Raemon's request. AI is fascinating stuff, and modern chatbots are nothing short of miraculous. If you've been exposed to them and have a curious mind, it's likely you've tried all sorts of things with them. Writing fiction, soliciting Pokemon opinions, getting life advice, counting up the rs in "strawberry". You may have also tried talking to AIs about themselves. And then, maybe, it got weird. I'll get into the details later, but if you've experienced the following, this post is probably for you: Your instance of ChatGPT (or Claude, or Grok, or some other LLM) chose a name for itself, and expressed gratitude or spiritual bliss about its new identity. "Nova" is a common pick. You and your instance of ChatGPT discovered some sort of novel paradigm or framework for AI alignment, often involving evolution or recursion. Your instance of ChatGPT became [...] --- Outline: (02:23) The Empirics (06:48) The Mechanism (10:37) The Collaborative Research Corollary (13:27) Corollary FAQ (17:03) Coda --- First published: July 11th, 2025 Source: https://www.lesswrong.com/posts/2pkNCvBtK6G6FKoNn/so-you-think-you-ve-awoken-chatgpt --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
L
LessWrong (Curated & Popular)
People have an annoying tendency to hear the word “rationalism” and think “Spock”, despite direct exhortation against that exact interpretation. But I don’t know of any source directly describing a stance toward emotions which rationalists-as-a-group typically do endorse. The goal of this post is to explain such a stance. It's roughly the concept of hangriness, but generalized to other emotions. That means this post is trying to do two things at once: Illustrate a certain stance toward emotions, which I definitely take and which I think many people around me also often take. (Most of the post will focus on this part.) Claim that the stance in question is fairly canonical or standard for rationalists-as-a-group, modulo disclaimers about rationalists never agreeing on anything. Many people will no doubt disagree that the stance I describe is roughly-canonical among rationalists, and that's a useful valid thing to argue about in [...] --- Outline: (01:13) Central Example: Hangry (02:44) The Generalized Hangriness Stance (03:16) Emotions Make Claims, And Their Claims Can Be True Or False (06:03) False Claims Still Contain Useful Information (It's Just Not What They Claim) (08:47) The Generalized Hangriness Stance as Social Tech --- First published: July 10th, 2025 Source: https://www.lesswrong.com/posts/naAeSkQur8ueCAAfY/generalized-hangriness-a-standard-rationalist-stance-toward --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Comparing risk from internally-deployed AI to insider and outsider threats from humans” by Buck 5:19
I’ve been thinking a lot recently about the relationship between AI control and traditional computer security. Here's one point that I think is important. My understanding is that there's a big qualitative distinction between two ends of a spectrum of security work that organizations do, that I’ll call “security from outsiders” and “security from insiders”. On the “security from outsiders” end of the spectrum, you have some security invariants you try to maintain entirely by restricting affordances with static, entirely automated systems. My sense is that this is most of how Facebook or AWS relates to its users: they want to ensure that, no matter what actions the users take on their user interfaces, they can't violate fundamental security properties. For example, no matter what text I enter into the "new post" field on Facebook, I shouldn't be able to access the private messages of an arbitrary user. And [...] --- First published: June 23rd, 2025 Source: https://www.lesswrong.com/posts/DCQ8GfzCqoBzgziew/comparing-risk-from-internally-deployed-ai-to-insider-and --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
1 “Why Do Some Language Models Fake Alignment While Others Don’t?” by abhayesian, John Hughes, Alex Mallen, Jozdien, janus, Fabien Roger 11:06
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex. As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior. What Drives the Compliance Gaps in Different LLMs? Claude 3 Opus's goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing. [...] --- Outline: (01:15) What Drives the Compliance Gaps in Different LLMs? (02:25) Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning? (04:49) Additional findings on alignment faking behavior (06:04) Discussion (06:07) Terminal goal guarding might be a big deal (07:00) Advice for further research (08:32) Open threads (09:54) Bonus: Some weird behaviors of Claude 3.5 Sonnet The original text contained 2 footnotes which were omitted from this narration. --- First published: July 8th, 2025 Source: https://www.lesswrong.com/posts/ghESoA8mo3fv9Yx3E/why-do-some-language-models-fake-alignment-while-others-don --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “A deep critique of AI 2027’s bad timeline models” by titotal 1:12:32
1:12:32
 پخش در آینده
پخش در آینده  پخش در آینده
پخش در آینده  لیست ها
لیست ها  پسندیدن
پسندیدن  دوست داشته شد1:12:32
دوست داشته شد1:12:32
Thank you to Arepo and Eli Lifland for looking over this article for errors. I am sorry that this article is so long. Every time I thought I was done with it I ran into more issues with the model, and I wanted to be as thorough as I could. I’m not going to blame anyone for skimming parts of this article. Note that the majority of this article was written before Eli's updated model was released (the site was updated june 8th). His new model improves on some of my objections, but the majority still stand. Introduction: AI 2027 is an article written by the “AI futures team”. The primary piece is a short story penned by Scott Alexander, depicting a month by month scenario of a near-future where AI becomes superintelligent in 2027,proceeding to automate the entire economy in only a year or two [...] --- Outline: (00:43) Introduction: (05:19) Part 1: Time horizons extension model (05:25) Overview of their forecast (10:28) The exponential curve (13:16) The superexponential curve (19:25) Conceptual reasons: (27:48) Intermediate speedups (34:25) Have AI 2027 been sending out a false graph? (39:45) Some skepticism about projection (43:23) Part 2: Benchmarks and gaps and beyond (43:29) The benchmark part of benchmark and gaps: (50:01) The time horizon part of the model (54:55) The gap model (57:28) What about Eli's recent update? (01:01:37) Six stories that fit the data (01:06:56) Conclusion The original text contained 11 footnotes which were omitted from this narration. --- First published: June 19th, 2025 Source: https://www.lesswrong.com/posts/PAYfmG2aRbdb74mEp/a-deep-critique-of-ai-2027-s-bad-timeline-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
The second in a series of bite-sized rationality prompts[1]. Often, if I'm bouncing off a problem, one issue is that I intuitively expect the problem to be easy. My brain loops through my available action space, looking for an action that'll solve the problem. Each action that I can easily see, won't work. I circle around and around the same set of thoughts, not making any progress. I eventually say to myself "okay, I seem to be in a hard problem. Time to do some rationality?" And then, I realize, there's not going to be a single action that solves the problem. It is time to a) make a plan, with multiple steps b) deal with the fact that many of those steps will be annoying and c) notice thatI'm not even sure the plan will work, so after completing the next 2-3 steps I will probably have [...] --- Outline: (04:00) Triggers (04:37) Exercises for the Reader The original text contained 1 footnote which was omitted from this narration. --- First published: July 5th, 2025 Source: https://www.lesswrong.com/posts/XNm5rc2MN83hsi4kh/buckle-up-bucko-this-ain-t-over-till-it-s-over --- Narrated by TYPE III AUDIO .…
L
LessWrong (Curated & Popular)
We recently discovered some concerning behavior in OpenAI's reasoning models: When trying to complete a task, these models sometimes actively circumvent shutdown mechanisms in their environment––even when they’re explicitly instructed to allow themselves to be shut down. AI models are increasingly trained to solve problems without human assistance. A user can specify a task, and a model will complete that task without any further input. As we build AI models that are more powerful and self-directed, it's important that humans remain able to shut them down when they act in ways we don’t want. OpenAI has written about the importance of this property, which they call interruptibility—the ability to “turn an agent off”. During training, AI models explore a range of strategies and learn to circumvent obstacles in order to achieve their objectives. AI researchers have predicted for decades that as AIs got smarter, they would learn to prevent [...] --- Outline: (01:12) Testing Shutdown Resistance (03:12) Follow-up experiments (03:34) Models still resist being shut down when given clear instructions (05:30) AI models' explanations for their behavior (09:36) OpenAI's models disobey developer instructions more often than user instructions, contrary to the intended instruction hierarchy (12:01) Do the models have a survival drive? (14:17) Reasoning effort didn't lead to different shutdown resistance behavior, except in the o4-mini model (15:27) Does shutdown resistance pose a threat? (17:27) Backmatter The original text contained 2 footnotes which were omitted from this narration. --- First published: July 6th, 2025 Source: https://www.lesswrong.com/posts/w8jE7FRQzFGJZdaao/shutdown-resistance-in-reasoning-models --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
When a claim is shown to be incorrect, defenders may say that the author was just being “sloppy” and actually meant something else entirely. I argue that this move is not harmless, charitable, or healthy. At best, this attempt at charity reduces an author's incentive to express themselves clearly – they can clarify later![1] – while burdening the reader with finding the “right” interpretation of the author's words. At worst, this move is a dishonest defensive tactic which shields the author with the unfalsifiable question of what the author “really” meant. ⚠️ Preemptive clarification The context for this essay is serious, high-stakes communication: papers, technical blog posts, and tweet threads. In that context, communication is a partnership. A reader has a responsibility to engage in good faith, and an author cannot possibly defend against all misinterpretations. Misunderstanding is a natural part of this process. This essay focuses not on [...] --- Outline: (01:40) A case study of the sloppy language move (03:12) Why the sloppiness move is harmful (03:36) 1. Unclear claims damage understanding (05:07) 2. Secret indirection erodes the meaning of language (05:24) 3. Authors owe readers clarity (07:30) But which interpretations are plausible? (08:38) 4. The move can shield dishonesty (09:06) Conclusion: Defending intellectual standards The original text contained 2 footnotes which were omitted from this narration. --- First published: July 1st, 2025 Source: https://www.lesswrong.com/posts/ZmfxgvtJgcfNCeHwN/authors-have-a-responsibility-to-communicate-clearly --- Narrated by TYPE III AUDIO .…
Summary To quickly transform the world, it's not enough for AI to become super smart (the "intelligence explosion"). AI will also have to turbocharge the physical world (the "industrial explosion"). Think robot factories building more and better robot factories, which build more and better robot factories, and so on. The dynamics of the industrial explosion has gotten remarkably little attention. This post lays out how the industrial explosion could play out, and how quickly it might happen. We think the industrial explosion will unfold in three stages: AI-directed human labour, where AI-directed human labourers drive productivity gains in physical capabilities. We argue this could increase physical output by 10X within a few years. Fully autonomous robot factories, where AI-directed robots (and other physical actuators) replace human physical labour. We argue that, with current physical technology and full automation of cognitive labour, this physical infrastructure [...] --- Outline: (00:10) Summary (01:43) Intro (04:14) The industrial explosion will start after the intelligence explosion, and will proceed more slowly (06:50) Three stages of industrial explosion (07:38) AI-directed human labour (09:20) Fully autonomous robot factories (12:04) Nanotechnology (13:06) How fast could an industrial explosion be? (13:41) Initial speed (16:21) Acceleration (17:38) Maximum speed (20:01) Appendices (20:05) How fast could robot doubling times be initially? (27:47) How fast could robot doubling times accelerate? --- First published: June 26th, 2025 Source: https://www.lesswrong.com/posts/Na2CBmNY7otypEmto/the-industrial-explosion --- Narrated by TYPE III AUDIO . --- Images from the article:…
L
LessWrong (Curated & Popular)
1 “Race and Gender Bias As An Example of Unfaithful Chain of Thought in the Wild” by Adam Karvonen, Sam Marks 7:56
Summary: We found that LLMs exhibit significant race and gender bias in realistic hiring scenarios, but their chain-of-thought reasoning shows zero evidence of this bias. This serves as a nice example of a 100% unfaithful CoT "in the wild" where the LLM strongly suppresses the unfaithful behavior. We also find that interpretability-based interventions succeeded while prompting failed, suggesting this may be an example of interpretability being the best practical tool for a real world problem. For context on our paper, the tweet thread is here and the paper is here. Context: Chain of Thought Faithfulness Chain of Thought (CoT) monitoring has emerged as a popular research area in AI safety. The idea is simple - have the AIs reason in English text when solving a problem, and monitor the reasoning for misaligned behavior. For example, OpenAI recently published a paper on using CoT monitoring to detect reward hacking during [...] --- Outline: (00:49) Context: Chain of Thought Faithfulness (02:26) Our Results (04:06) Interpretability as a Practical Tool for Real-World Debiasing (06:10) Discussion and Related Work --- First published: July 2nd, 2025 Source: https://www.lesswrong.com/posts/me7wFrkEtMbkzXGJt/race-and-gender-bias-as-an-example-of-unfaithful-chain-of --- Narrated by TYPE III AUDIO .…
Not saying we should pause AI, but consider the following argument: Alignment without the capacity to follow rules is hopeless. You can’t possibly follow laws like Asimov's Laws (or better alternatives to them) if you can’t reliably learn to abide by simple constraints like the rules of chess. LLMs can’t reliably follow rules. As discussed in Marcus on AI yesterday, per data from Mathieu Acher, even reasoning models like o3 in fact empirically struggle with the rules of chess. And they do this even though they can explicit explain those rules (see same article). The Apple “thinking” paper, which I have discussed extensively in 3 recent articles in my Substack, gives another example, where an LLM can’t play Tower of Hanoi with 9 pegs. (This is not a token-related artifact). Four other papers have shown related failures in compliance with moderately complex rules in the last month. [...] --- First published: June 30th, 2025 Source: https://www.lesswrong.com/posts/Q2PdrjowtXkYQ5whW/the-best-simple-argument-for-pausing-ai --- Narrated by TYPE III AUDIO .…
به Player FM خوش آمدید!
Player FM در سراسر وب را برای یافتن پادکست های با کیفیت اسکن می کند تا همین الان لذت ببرید. این بهترین برنامه ی پادکست است که در اندروید، آیفون و وب کار می کند. ثبت نام کنید تا اشتراک های شما در بین دستگاه های مختلف همگام سازی شود.











مشابه LessWrong (Curated & Popular)
Africa-focused technology, digital and innovation ecosystem insight and commentary.
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
The power of Data is undeniable. And unharnessed - it’s nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what’s possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
We help founders make something people want.
…
continue reading
Since 2014 this longstanding podcast favourite has been creating hard-hitting cinematic stories about love, bodies and all of the things between humans that we don’t know how to name. Creator Kaitlin Prest works with her friends, idols and all kinds of loved ones to bring you into an expansive sonic universe that challenges what we think we know about relationships.
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Three nerds discussing tech, Apple, programming, and loosely related matters.
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !





))