
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
محتوای ارائه شده توسط O'Reilly Media. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط O'Reilly Media یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
مشابه O'Reilly Data Show Podcast

Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading

Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
T
The Influence Factor by The Influencer Marketing Factory

1
The Influence Factor by The Influencer Marketing Factory
The Influencer Marketing Factory
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading

Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading

Wharton faculty and industry leaders discuss their latest research, books, and relevant business topics. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading

Welcome to the What’s Next! Podcast. I’ve met so many brilliant people as I traveled the globe and have had some fascinating conversations that I’ve wished had been recorded so I could share them with you - this podcast was a way for me to recreate those moments and let you in on some fantastic insights. My current conversations center around one objective: what's next for companies and individuals as they look to innovate and grow. I hope these conversations inspire you as much as they have ...
…
continue reading

The Greatness Machine is on a Quest to Maximize the Human Experience! Join Award Winning CEO and Author, Darius Mirshahzadeh (pron. Mer-shaw-za-day), as he interviews some of the greatest minds in the world―turning their wisdom and experience into learnings and advice you can use in your life so that you can level up and create greatness. Join Darius as he goes deep with guests like: Moby, Seth Godin, Gabby Reece, Amanda Knox, UFC Ring Announcer Bruce Buffer, Former FBI Negotiator Chris Voss ...
…
continue reading

Call them changemakers. Call them rule breakers. We call them Redefiners. And in this provocative podcast, we explore how daring leaders from across industries and around the globe are redefining their organizations—and themselves—to create extraordinary impact in today’s rapidly changing world. In each episode, Russell Reynolds Associates Leadership Advisor Hoda Tahoun and former CEO Clarke Murphy host engaging, purposeful conversations with leaders in and out of the business world who shar ...
…
continue reading

Business tips for startups by proven entrepreneurs
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !

))










Labeling, transforming, and structuring training data sets for machine learning
Manage episode 248276630 series 61203
محتوای ارائه شده توسط O'Reilly Media. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط O'Reilly Media یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
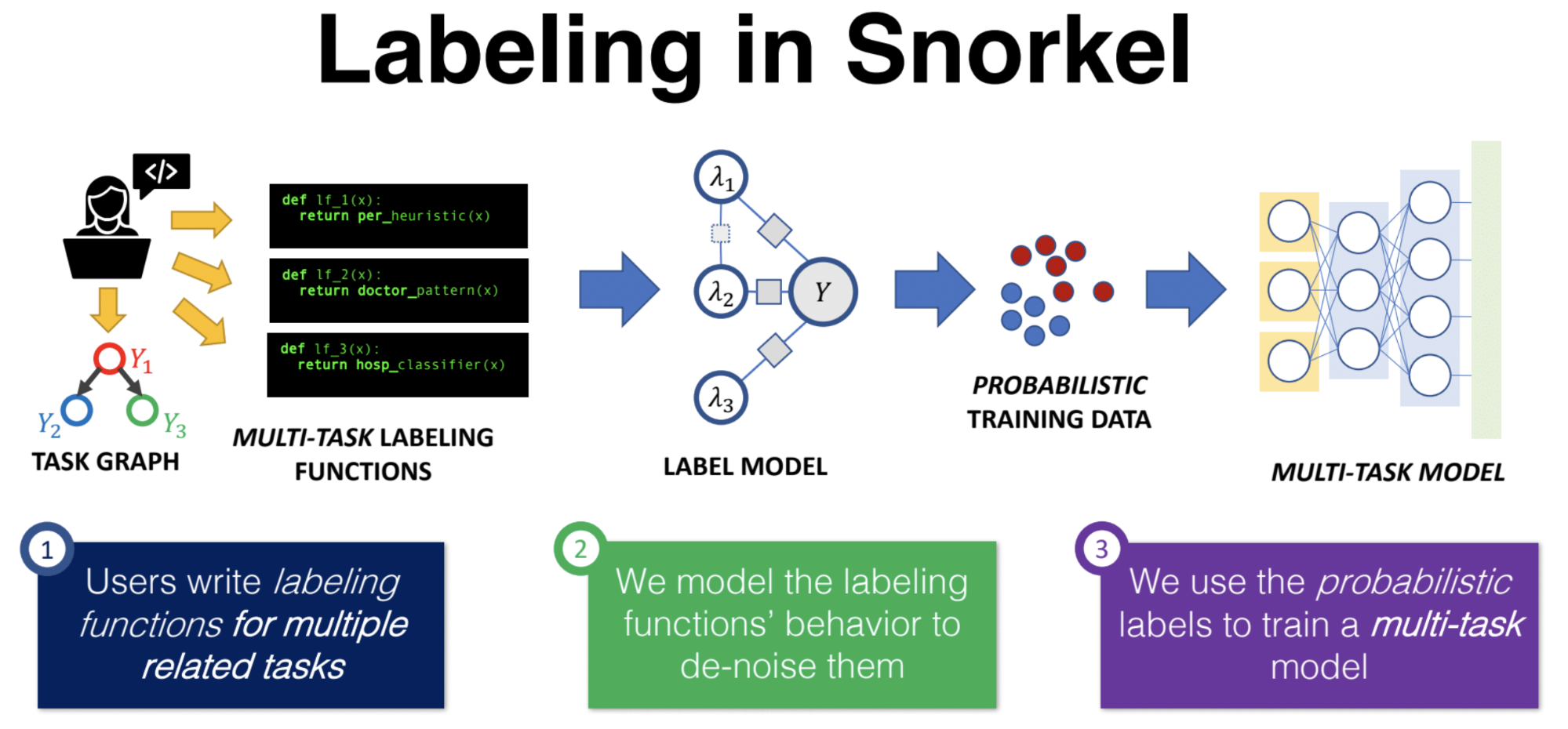
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 قسمت
Manage episode 248276630 series 61203
محتوای ارائه شده توسط O'Reilly Media. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط O'Reilly Media یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 قسمت
همه قسمت ها
×O
O'Reilly Data Show Podcast

In this episode of the Data Show , I speak with Peter Bailis , founder and CEO of Sisu , a startup that is using machine learning to improve operational analytics. Bailis is also an assistant professor of computer science at Stanford University, where he conducts research into data-intensive systems and where he is co-founder of the DAWN Lab . We had a great conversation spanning many topics, including: His personal blog , which contains some of the best explainers on emerging topics in data management and distributed systems. The role of machine learning in operational analytics and business intelligence. Machine learning benchmarks—specifically two recent ML initiatives that he’s been involved with: DAWNBench and MLPerf . Trends in data management and in tools for machine learning development, governance, and operations. Related resources: “Setting benchmarks in machine learning” : Dave Patterson, Peter Bailis, and other industry leaders discuss how MLPerf will define an entire suite of benchmarks to measure performance of software, hardware, and cloud systems. “The quest for high-quality data” “RISELab’s AutoPandas hints at automation tech that will change the nature of software development” Jeff Jonas on “Real-time entity resolution made accessible” “What are model governance and model operations?” “We need to build machine learning tools to augment machine learning engineers”…
In this episode of the Data Show , I speak with Arun Kejariwal of Facebook and Ira Cohen of Anodot (full disclosure: I’m an advisor to Anodot). This conversation stemmed from a recent online panel discussion we did, where we discussed time series data, and, specifically, anomaly detection and forecasting. Both Kejariwal (at Machine Zone, Twitter, and Facebook) and Cohen (at HP and Anodot) have extensive experience building analytic and machine learning solutions at large scale, and both have worked extensively with time-series data. The growing interest in AI and machine learning has not been confined to computer vision, speech technologies, or text. In the enterprise, there is strong interest in using similar automation tools for temporal data and time series. We had a great conversation spanning many topics, including: Why businesses should care about anomaly detection and forecasting; specifically, we delve into examples outside of IT Operations & Monitoring. (Specialized) techniques and tools for automating some of the relevant tasks, including signal processing, statistical methods, and machine learning. What are some of the key features of an anomaly detection or forecasting system. What lies ahead for large-scale systems for time series analysis. Related resources: “Product management in the machine learning era” – a new tutorial at the Artificial Intelligence Conference in London “One simple chart: Who is interested in Apache Pulsar?” Ira Cohen: “Semi-supervised, unsupervised, and adaptive algorithms for large-scale time series” “Got speech? These guidelines will help you get started building voice applications” “RISELab’s AutoPandas hints at automation tech that will change the nature of software development” Ameet Talwalker: “How to train and deploy deep learning at scale”…
In this episode of the Data Show , I speak with Michael Mahoney , a member of RISELab , the International Computer Science Institute , and the Department of Statistics at UC Berkeley. A physicist by training, Mahoney has been at the forefront of many important problems in large-scale data analysis. On the theoretical side, his works spans algorithmic and statistical methods for matrices, graphs, regression, optimization, and related problems. On the applications side, he has contributed to systems used for internet and social media analysis, social network analysis, as well as for a host of applications in the physical and life sciences. Most recently, he has been working on deep neural networks, specifically developing theoretical methods and practical diagnostic tools that should be helpful to practitioners who use deep learning. Analyzing deep neural networks with WeightWatcher . Image by Michael Mahoney and Charles Martin, used with permission. We had a great conversation spanning many topics, including: The class of problems in big data, machine learning, and data analysis that he has worked on at Yahoo, Stanford, and Berkeley. The new UC Berkeley FODA (Foundations of Data Analysis) Institute . HAWQ (Hessian AWare Quantization of Neural Networks with Mixed-Precision), a new framework for addressing problems pertaining to model size and inference speed/power in deep learning. WeightWatcher : a new open source project for predicting the accuracy of deep neural networks. WeightWatcher stems from a recent series of papers with Charles Martin , of Calculation Consulting . Related resources: “Deep learning at scale: Tools and solutions” – a new tutorial at the Artificial Intelligence Conference in San Jose Ameet Talwalker on “How to train and deploy deep learning at scale” Greg Diamos on “How big compute is powering the deep learning rocket ship” “RISELab’s AutoPandas hints at automation tech that will change the nature of software development” Reza Zadeh on “Scaling machine learning” “Becoming a machine learning company means investing in foundational technologies” “Managing risk in machine learning” “What are model governance and model operations?” “Product management in the machine learning era” : a tutorial at the Artificial Intelligence Conference in San Jose…
In this episode of the Data Show , I speak with Kesha Williams , technical instructor at A Cloud Guru , a training company focused on cloud computing. As a full stack web developer, Williams became intrigued by machine learning and started teaching herself the ML tools on Amazon Web Services. Fast forward to today, Williams has built some well-regarded Alexa skills, mastered ML services on AWS, and has now firmly added machine learning to her developer toolkit. Anatomy of an Alexa skill. Image by Kesha Williams, used with permission. We had a great conversation spanning many topics, including: How she got started and made the transition into a full-fledged machine learning practitioner. We discussed the evolution of ML tools and learning resources, and how accessible they’ve become for developers. How to build and monetize Alexa skills. Along the way, we took a deep dive and discussed some of the more interesting Alexa skills she has built, as well as one that she really admires. Related resources: “Product management in the machine learning era” : a new tutorial session at the Artificial Intelligence Conference in London Cassie Kozyrkov: “Make data science more useful” Kartik Hosanagar: “Algorithms are shaping our lives—here’s how we wrest back control” Francesca Lazzeri and Jaya Mathew: “Lessons learned while helping enterprises adopt machine learning” Jerry Overton: “Teaching and implementing data science and AI in the enterprise” “Becoming a machine learning company means investing in foundational technologies” “Managing risk in machine learning” “What are model governance and model operations?”…
O
O'Reilly Data Show Podcast
In this episode of the Data Show , I speak with Alex Ratner , project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services. Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations . Along with his thesis advisor professor Chris Ré of Stanford , Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets . Snorkel pipeline for data labeling. Source: Alex Ratner, used with permission. We had a great conversation spanning many topics, including: Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data. A tour through Snorkel, including its target users and key components. What’s in the newly released version (v 0.9) of Snorkel. The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project. Data lineage, AutoML, and end-to-end automation of machine learning pipelines. Holoclean and other projects focused on data quality and data programming. The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights , and even knowledge. Related resources: “Product management in the machine learning era” : A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019. Chris Ré: “Software 2.0 and Snorkel” Alex Ratner: “Creating large training data sets quickly” Ihab Ilyas and Ben Lorica on “The quest for high-quality data” Roger Chen: “Acquiring and sharing high-quality data” Jeff Jonas on “Real-time entity resolution made accessible” “Data collection and data markets in the age of privacy and machine learning”…
In this episode of the Data Show , I speak with Cassie Kozyrkov , technical director and chief decision scientist at Google Cloud. She describes “decision intelligence” as an interdisciplinary field concerned with all aspects of decision-making, and which combines data science with the behavioral sciences. Most recently she has been focused on developing best practices that can help practitioners make safe, effective use of AI and data. Kozyrkov uses her platform to help data scientists develop skills that will enable them to connect data and AI with their organizations’ core businesses. We had a great conversation spanning many topics, including: How data science can be more useful The importance of the human side of data The leadership talent shortage in data science Is data science a bubble? Related resources: “Managing machine learning in the enterprise: Lessons from banking and health care” “Managing risk in machine learning” “What are model governance and model operations?” “Becoming a machine learning company means investing in foundational technologies” Forough Poursabzi Sangdeh: “It’s time for data scientists to collaborate with researchers in other disciplines” Jacob Ward: “How social science research can inform the design of AI systems” “AI and machine learning will require retraining your entire organization” Ihab Ilyas and Ben lorica on “The quest for high-quality data” “Product management in the machine learning era” —a tutorial at the Artificial Intelligence Conference in San Jose…
In this episode of the Data Show , I spoke with Roger Chen, co-founder and CEO of Computable Labs , a startup focused on building tools for the creation of data networks and data exchanges. Chen has also served as co-chair of O’Reilly’s Artificial Intelligence Conference since its inception in 2016. This conversation took place the day after Chen and his collaborators released an interesting new white paper, Fair value and decentralized governance of data . Current-generation AI and machine learning technologies rely on large amounts of data, and to the extent they can use their large user bases to create “data silos,” large companies in large countries (like the U.S. and China) enjoy a competitive advantage. With that said, we are awash in articles about the dangers posed by these data silos. Privacy and security, disinformation, bias, and a lack of transparency and control are just some of the issues that have plagued the perceived owners of “data monopolies.” In recent years, researchers and practitioners have begun building tools focused on helping organizations acquire, build, and share high-quality data. Chen and his collaborators are doing some of the most interesting work in this space, and I recommend their new white paper and accompanying open source projects . Sequence of basic market transactions in the Computable Labs protocol . Source: Roger Chen, used with permission. We had a great conversation spanning many topics, including: Why he chose to focus on data governance and data markets. The unique and fundamental challenges in accurately pricing data. The importance of data lineage and provenance, and the approach they took in their proposed protocol. What cooperative governance is and why it’s necessary. How their protocol discourages an unscrupulous user from just scraping all data available in a data market. Related resources: Roger Chen: “Data liquidity in the age of inference” Ihab Ilyas and Ben lorica on “The quest for high-quality data” Chris Ré: “Software 2.0 and Snorkel” Alex Ratner on “Creating large training data sets quickly” Jeff Jonas on “Real-time entity resolution made accessible” “Data collection and data markets in the age of privacy and machine learning” Guillaume Chaslot on “The importance of transparency and user control in machine learning”…
In this week’s episode of the Data Show, we’re featuring an interview Data Show host Ben Lorica participated in for the Software Engineering Daily Podcast , where he was interviewed by Jeff Meyerson . Their conversation mainly centered around data engineering, data architecture and infrastructure, and machine learning (ML). Here are a few highlights: Tools for productive collaboration A data catalog, at a high level, basically answers questions around the data that’s available and who is using it so an enterprise can understand access patterns. … The term “data catalog” is generally used when you’ve gotten to the point where you have a team of data scientists and you need a place where they can use libraries in a setting where they can collaborate, and where they can share not only models but maybe even data pipelines and features. The more advanced data science platforms will have automation tools built in. … The ideal scenario is the data science platform is not just for prototyping, but also for pushing things to production. Tools for ML development We have tools for software development, and now we’re beginning to hear about tools for machine learning development—there’s a company here at Strata called Comet.ml , and there’s another startup called Verta.ai . But what has really caught my attention is an open source project from Databricks called MLflow . When it first came out, I thought, ‘Oh, yeah, so we don’t have anything like this. Might have a decent chance of success.’ But I didn’t pay close attention until recently; fast forward to today, there are 80 contributors for 40 companies and 200+ companies using it. What’s good about MLflow is that it has three components and you’re free to pick and choose—you can use one, two, or three. Based on their surveys, the most popular component is the one for tracking and managing machine learning experiments. It’s designed to be useful for individual data scientists, but it’s also designed to be used by teams of data scientists, so they have documented use-cases of MLflow where you have a company managing thousands of models and productions.…
O
O'Reilly Data Show Podcast
In this episode of the Data Show , I spoke with Nick Pentreath , principal engineer at IBM. Pentreath was an early and avid user of Apache Spark, and he subsequently became a Spark committer and PMC member. Most recently his focus has been on machine learning, particularly deep learning, and he is part of a group within IBM focused on building open source tools that enable end-to-end machine learning pipelines. We had a great conversation spanning many topics, including: AI Fairness 360 (AIF360) , a set of fairness metrics for data sets and machine learning models Adversarial Robustness Toolbox (ART) , a Python library for adversarial attacks and defenses. Model Asset eXchange (MAX) , a curated and standardized collection of free and open source deep learning models. Tools for model development, governance, and operations, including MLflow , Seldon Core , and Fabric for deep learning Reinforcement learning in the enterprise, and the emergence of relevant open source tools like Ray . Related resources: “Modern Deep Learning: Tools and Techniques” —a new tutorial at the Artificial Intelligence conference in San Jose Harish Doddi on “Simplifying machine learning lifecycle management” Sharad Goel and Sam Corbett-Davies on “Why it’s hard to design fair machine learning models” “Managing risk in machine learning” : considerations for a world where ML models are becoming mission critical “The evolution and expanding utility of Ray” “Local Interpretable Model-Agnostic Explanations (LIME): An Introduction” Forough Poursabzi Sangdeh on why “It’s time for data scientists to collaborate with researchers in other disciplines”…
In this episode of the Data Show , I spoke with Dhruba Borthakur (co-founder and CTO) and Shruti Bhat (SVP of Product) of Rockset , a startup focused on building solutions for interactive data science and live applications. Borthakur was the founding engineer of HDFS and creator of RocksDB , while Bhat is an experienced product and marketing executive focused on enterprise software and data products. Their new startup is focused on a few trends I’ve recently been thinking about, including the re-emergence of real-time analytics, and the hunger for simpler data architectures and tools. Borthakur exemplifies the need for companies to continually evaluate new technologies: while he was the founding engineer for HDFS, these days he mostly works with object stores like S3. We had a great conversation spanning many topics, including: RocksDB , an open source, embeddable key-value store originated by Facebook, and which is used in several other open source projects . Time-series databases. The importance of having solutions for real-time analytics, particularly now with the renewed interest in IoT applications and rollout of 5G technologies. Use cases for Rockset’s technologies—and more generally, applications of real-time analytics. The Aggregator Leaf Tailer architecture as an alternative to the Lambda architecture. Building data infrastructure in the cloud. The Aggregator Leaf Tailer ( “CQRS for the data world”) : A data architecture favored by web-scale companies. Source: Dhruba Borthakur, used with permission. Related resources: Serverless Streaming Architectures & Algorithms for the Enterprise – a new tutorial on September 24th at Strata Data NYC. “Becoming a machine learning company means investing in foundational technologies” Haoyuan Li: “In the age of AI, fundamental value resides in data” Harish Doddi: “Simplifying machine learning lifecycle management” Eric Jonas: “A Berkeley view on serverless computing” “Specialized tools for machine learning development and model governance are becoming essential” Avner Braaverman: “What data scientists and data engineers can do with current generation serverless technologies”…
O
O'Reilly Data Show Podcast
In this episode of the Data Show , I spoke with Jike Chong , chief data scientist at Acorns , a startup focused on building tools for micro-investing. Chong has extensive experience using analytics and machine learning in financial services, and he has experience building data science teams in the U.S. and in China. We had a great conversation spanning many topics, including: Potential applications of data science in financial services. The current state of data science in financial services in both the U.S. and China. His experience recruiting, training, and managing data science teams in both the U.S. and China. Here are some highlights from our conversation: Opportunities in financial services There’s a customer acquisition piece and then there’s a customer retention piece. For customer acquisition, we can see that new technologies can really add value by looking at all sorts of data sources that can help a financial service company identify who they want to target to provide those services. So, it’s a great place where data science can help find the product market fit, not just at one instance like identifying who you want to target, but also in a continuous form where you can evolve a product and then continuously find the audience that would best fit the product and continue to analyze the audience so you can design the next generation product. … Once you have a specific cohort of users who you want to target, there’s a need to be able to precisely convert them, which means understanding the stage of the customer’s thought process and understanding how to form the narrative to convince the user or the customer that a particular piece of technology or particular piece of service is the current service they need. … On the customer serving or retention side, for financial services we commonly talk about building hundred-year businesses, right? They have to be profitable businesses, and for financial service to be profitable, there are operational considerations—quantifying risk requires a lot of data science; preventing fraud is really important, and there is garnering the long-term trust with the customer so they stay with you, which means having the work ethic to be able to take care of customer’s data and able to serve the customer better with automated services whenever and wherever the customer is. It’s all those opportunities where I see we can help serve the customer by having the right services presented to them and being able to serve them in the long term. Opportunities in China A few important areas in the financial space in China include mobile payments, wealth management, lending, and insurance—basically, the major areas for the financial industry. For these areas, China may be a forerunner in using internet technologies, especially mobile internet technologies for FinTech, and I think the wave started way back in the 2012/2013 time frame. If you look at mobile payments, like Alipay and WeChat, those have hundreds of millions of active users. The latest data from Alipay is about 608 million users, and these are monthly active users we’re talking about. This is about two times the U.S. population actively using Alipay on a monthly basis, which is a crazy number if you consider all the data that can generate and all the things you can see people buying to be able to understand how to serve the users better. If you look at WeChat, they’re boasting one billion users, monthly active users, early this year. Those are the huge players, and with that amount of traffic, they are able to generate a lot of interest for the lower-frequency services like wealth management and lending, as well as insurance. Related resources: Kai-Fu Lee outlines the factors that enabled China’s rapid ascension in AI Gary Kazantsev on how “Data science makes an impact on Wall Street” Juan Huerta on “Upcoming challenges and opportunities for data technologies in consumer finance” Geoffrey Bradway on “Programming collective intelligence for financial trading” Jason Dai on why “Companies in China are moving quickly to embrace AI technologies” Haoyuan Li on why “In the age of AI, fundamental value resides in data”…
In this episode of the Data Show , I spoke with Jeff Jonas , CEO, founder and chief scientist of Senzing , a startup focused on making real-time entity resolution technologies broadly accessible. He was previously a fellow and chief scientist of context computing at IBM. Entity resolution (ER) refers to techniques and tools for identifying and linking manifestations of the same entity/object/individual. Ironically, ER itself has many different names (e.g., record linkage, duplicate detection, object consolidation/reconciliation, etc.). ER is an essential first step in many domains, including marketing (cleaning up databases), law enforcement (background checks and counterterrorism), and financial services and investing . Knowing exactly who your customers are is an important task for security, fraud detection, marketing, and personalization. The proliferation of data sources and services has made ER very challenging in the internet age. In addition, many applications now increasingly require near real-time entity resolution. We had a great conversation spanning many topics including: Why ER is interesting and challenging How ER technologies have evolved over the years How Senzing is working to democratize ER by making real-time AI technologies accessible to developers Some early use cases for Senzing’s technologies Some items on their research agenda Here are a few highlights from our conversation: Entity Resolution through years In the early ’90s, I worked on a much more advanced version of entity resolution for the casinos in Las Vegas and created software called NORA, non-obvious relationship awareness. Its purpose was to help casinos better understand who they were doing business with. We would ingest data from the loyalty club, everybody making hotel reservations, people showing up without reservations, everybody applying for jobs, people terminated, vendors, and 18 different lists of different kinds of bad people, some of them card counters (which aren’t that bad), some cheaters. And they wanted to figure out across all these identities when somebody was the same, and then when people were related. Some people were using 32 different names and a bunch of different social security numbers. … Ultimately, IBM bought my company and this technology became what is known now at IBM as “identity insight.” Identity insight is a real-time entity resolution engine that gets used to solve many kinds of problems. MoneyGram implemented it and their fraud complaints dropped 72%. They saved a few hundred million just in their first few years. … But while at IBM, I had a grand vision about a new type of entity resolution engine that would have been unlike anything that’s ever existed. It’s almost like a Swiss Army knife for ER. Recent developments The Senzing entity resolution engine works really well on two records from a domain that you’ve never even seen before. Say you’ve never done entity resolution on restaurants from Singapore. The first two records you feed it, it’s really, really already smart. And then as you feed it more data, it gets smarter and smarter. … So, there are two things that we’ve intertwined. One is common sense. One type of common sense is the names—Dick, Dickie, Richie, Rick, Ricardo are all part of the same name family. Why should it have to study millions and millions of records to learn that again? … Next to common sense, there’s real-time learning. In real-time learning, we do a few things. You might have somebody named Bob, but who now goes by a nickname or an alias of Andy. Eventually, you might come to learn that. So, now you know you have to learn over time that Bob also has this nickname, and Bob lived at three addresses, and this is his credit card number, and now he’s got four phone numbers. So you want to learn those over time. … These systems we’re creating, our entity resolution systems—which really resolve entities and graph them (call it index of identities and how they’re related)—never has to be reloaded. It literally cleans itself up in the past. You can do maintenance on it while you’re querying it, while you’re loading new transactional data, while you’re loading historical data. There’s nothing else like it that can work at this scale. It’s really hard to do. Related resources: Jeff Jonas on “Context Computing” David Ferrucci on why “Language understanding remains one of AI’s grand challenges” David Blei on “Topic models: Past, present, and future” “Lessons learned building natural language processing systems in health care” “Building a contacts graph from activity data” “Customer record deduplication using Spark and Reifier”…
In this episode of the Data Show , I spoke with Neelesh Salian , software engineer at Stitch Fix , a company that combines machine learning and human expertise to personalize shopping. As companies integrate machine learning into their products and systems, there are important foundational technologies that come into play. This shouldn’t come as a shock, as current machine learning and AI technologies require large amounts of data—specifically, labeled data for training models. There are also many other considerations—including security, privacy, reliability/safety—that are encouraging companies to invest in a suite of data technologies. In conversations with data engineers, data scientists, and AI researchers, the need for solutions that can help track data lineage and provenance keeps popping up. There are several San Francisco Bay Area companies that have embarked on building data lineage systems—including Salian and his colleagues at Stitch Fix. I wanted to find out how they arrived at the decision to build such a system and what capabilities they are building into it. Here are some highlights from our conversation: Data lineage Data lineage is not something new. It’s something that is borne out of the necessity of understanding how data is being written and interacted with in the data warehouse. I like to tell this story when I’m describing data lineage: think of it as a journey for data. The data takes a journey entering into your warehouse. This can be transactional data, dashboards, or recommendations. What is lost in that collection of data is the information about how it came about. If you knew what journey and exactly what constituted that data to come into being into your data warehouse or any other storage appliance you use, that would be really useful. … Think about data lineage as helping issues about quality of data, understanding if something is corrupted. On the security side, think of GDPR … which was one of the hot topics I heard about at the Strata Data Conference in London in 2018. Why companies are suddenly building data lineage solutions A data lineage system becomes necessary as time progresses. It becomes easier for maintainability. You need it for audit trails, for security and compliance. But you also need to think of the benefit of managing the data sets you’re working with. If you’re working with 10 databases, you need to know what’s going on in them. If I have to give you a vision of a data lineage system, think of it as a final graph or view of some data set, and it shows you a graph of what it’s linked to. Then it gives you some metadata information so you can drill down. Let’s say you have corrupted data, let’s say you want to debug something. All these cases tie into the actual use cases for which we want to build it. Related resources: “Deep automation in machine learning” Vitaly Gordon on “Building tools for enterprise data science” “Managing risk in machine learning” Haoyuan Li explains why “In the age of AI, fundamental value resides in data” “What machine learning means for software development” Joe Hellerstein on how “Metadata services can lead to performance and organizational improvements”…
O
O'Reilly Data Show Podcast
1 What data scientists and data engineers can do with current generation serverless technologies 36:32
In this episode of the Data Show , I spoke with Avner Braverman , co-founder and CEO of Binaris , a startup that aims to bring serverless to web-scale and enterprise applications. This conversation took place shortly after the release of a seminal paper from UC Berkeley ( “Cloud Programming Simplified: A Berkeley View on Serverless Computing” ), and this paper seeded a lot of our conversation during this episode. Serverless is clearly on the radar of data engineers and architects. In a recent survey , we found 85% of respondents already had parts of their data infrastructure in one of the public clouds, and 38% were already using at least one of the serverless offerings we listed. As more serverless offerings get rolled out—e.g., things like PyWren that target scientists—I expect these numbers to rise. We had a great conversation spanning many topics, including: A short history of cloud computing. The fundamental differences between serverless and conventional cloud computing. The reasons serverless—specifically AWS Lambda—took off so quickly. What can data scientists and data engineers do with the current generation serverless offerings. What is missing from serverless today and what should users expect in the near future. Related resources: “The evolution and expanding utility of Ray” Results of a new survey: “Evolving Data Infrastructure: Tools and Best Practices for Advanced Analytics and AI” Eric Jonas on “Building accessible tools for large-scale computation and machine learning” “7 data trends on our radar” “Handling real-time data operations in the enterprise” “Progress for big data in Kubernetes”…
O
O'Reilly Data Show Podcast
In this episode of the Data Show , I spoke with Forough Poursabzi-Sangdeh , a postdoctoral researcher at Microsoft Research New York City. Poursabzi works in the interdisciplinary area of interpretable and interactive machine learning. As models and algorithms become more widespread, many important considerations are becoming active research areas: fairness and bias, safety and reliability, security and privacy, and Poursabzi’s area of focus—explainability and interpretability. We had a great conversation spanning many topics, including: Current best practices and state-of-the-art methods used to explain or interpret deep learning—or, more generally, machine learning models. The limitations of current model interpretability methods. The lack of clear/standard metrics for comparing different approaches used for model interpretability Many current AI and machine learning applications augment humans, and, thus, Poursabzi believes it’s important for data scientists to work closely with researchers in other disciplines. The importance of using human subjects in model interpretability studies. Related resources: “Local Interpretable Model-Agnostic Explanations (LIME): An Introduction” “Interpreting predictive models with Skater: Unboxing model opacity” Jacob Ward on “How social science research can inform the design of AI systems” Sharad Goel and Sam Corbett-Davies on “Why it’s hard to design fair machine learning models” “Managing risk in machine learning” : considerations for a world where ML models are becoming mission critical Francesca Lazzeri and Jaya Mathew on “Lessons learned while helping enterprises adopt machine learning” Jerry Overton on “Teaching and implementing data science and AI in the enterprise”…
به Player FM خوش آمدید!
Player FM در سراسر وب را برای یافتن پادکست های با کیفیت اسکن می کند تا همین الان لذت ببرید. این بهترین برنامه ی پادکست است که در اندروید، آیفون و وب کار می کند. ثبت نام کنید تا اشتراک های شما در بین دستگاه های مختلف همگام سازی شود.











مشابه O'Reilly Data Show Podcast
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Best Business Podcast (Gold), British Podcast Awards 2023 How do you build a fully electric motorcycle with no compromises on performance? How can we truly experience what the virtual world feels like? What does it take to design the first commercially available flying car? And how do you build a lightsaber? These are some of the questions this podcast answers as we share the moments where digital transforms physical, and meet the brilliant minds behind some of the most innovative products a ...
…
continue reading
Flash Forward is a show about possible (and not so possible) future scenarios. What would the warranty on a sex robot look like? How would diplomacy work if we couldn’t lie? Could there ever be a fecal transplant black market? (Complicated, it wouldn’t, and yes, respectively, in case you’re curious.) Hosted and produced by award winning science journalist Rose Eveleth, each episode combines audio drama and journalism to go deep on potential tomorrows, and uncovers what those futures might re ...
…
continue reading
T
The Influence Factor by The Influencer Marketing Factory
1
The Influence Factor by The Influencer Marketing Factory
The Influencer Marketing Factory
Alessandro Bogliari, CEO and Co-Founder of The Influencer Marketing Factory, a global influencer marketing agency, talks with great guests about influencer marketing, social media, the creator economy, social commerce and much more.
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
Wharton faculty and industry leaders discuss their latest research, books, and relevant business topics. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
Welcome to the What’s Next! Podcast. I’ve met so many brilliant people as I traveled the globe and have had some fascinating conversations that I’ve wished had been recorded so I could share them with you - this podcast was a way for me to recreate those moments and let you in on some fantastic insights. My current conversations center around one objective: what's next for companies and individuals as they look to innovate and grow. I hope these conversations inspire you as much as they have ...
…
continue reading
The Greatness Machine is on a Quest to Maximize the Human Experience! Join Award Winning CEO and Author, Darius Mirshahzadeh (pron. Mer-shaw-za-day), as he interviews some of the greatest minds in the world―turning their wisdom and experience into learnings and advice you can use in your life so that you can level up and create greatness. Join Darius as he goes deep with guests like: Moby, Seth Godin, Gabby Reece, Amanda Knox, UFC Ring Announcer Bruce Buffer, Former FBI Negotiator Chris Voss ...
…
continue reading
Call them changemakers. Call them rule breakers. We call them Redefiners. And in this provocative podcast, we explore how daring leaders from across industries and around the globe are redefining their organizations—and themselves—to create extraordinary impact in today’s rapidly changing world. In each episode, Russell Reynolds Associates Leadership Advisor Hoda Tahoun and former CEO Clarke Murphy host engaging, purposeful conversations with leaders in and out of the business world who shar ...
…
continue reading
Business tips for startups by proven entrepreneurs
…
continue reading
Player FM - برنامه پادکست
با برنامه Player FM !
با برنامه Player FM !



