
))
“Gradient Routing: Masking Gradients to Localize Computation in Neural Networks” by cloud, Jacob G-W, Evzen, Joseph Miller, TurnTrout
Manage episode 454600259 series 3364758
محتوای ارائه شده توسط LessWrong. تمام محتوای پادکست شامل قسمتها، گرافیکها و توضیحات پادکست مستقیماً توسط LessWrong یا شریک پلتفرم پادکست آنها آپلود و ارائه میشوند. اگر فکر میکنید شخصی بدون اجازه شما از اثر دارای حق نسخهبرداری شما استفاده میکند، میتوانید روندی که در اینجا شرح داده شده است را دنبال کنید.https://fa.player.fm/legal
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
…
continue reading
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
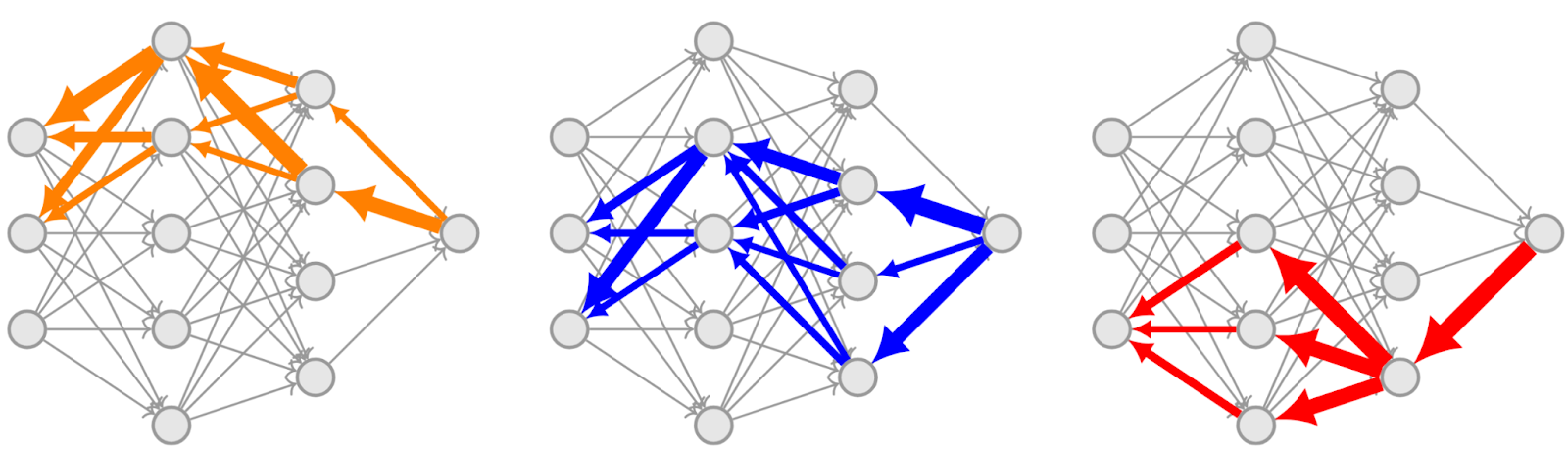
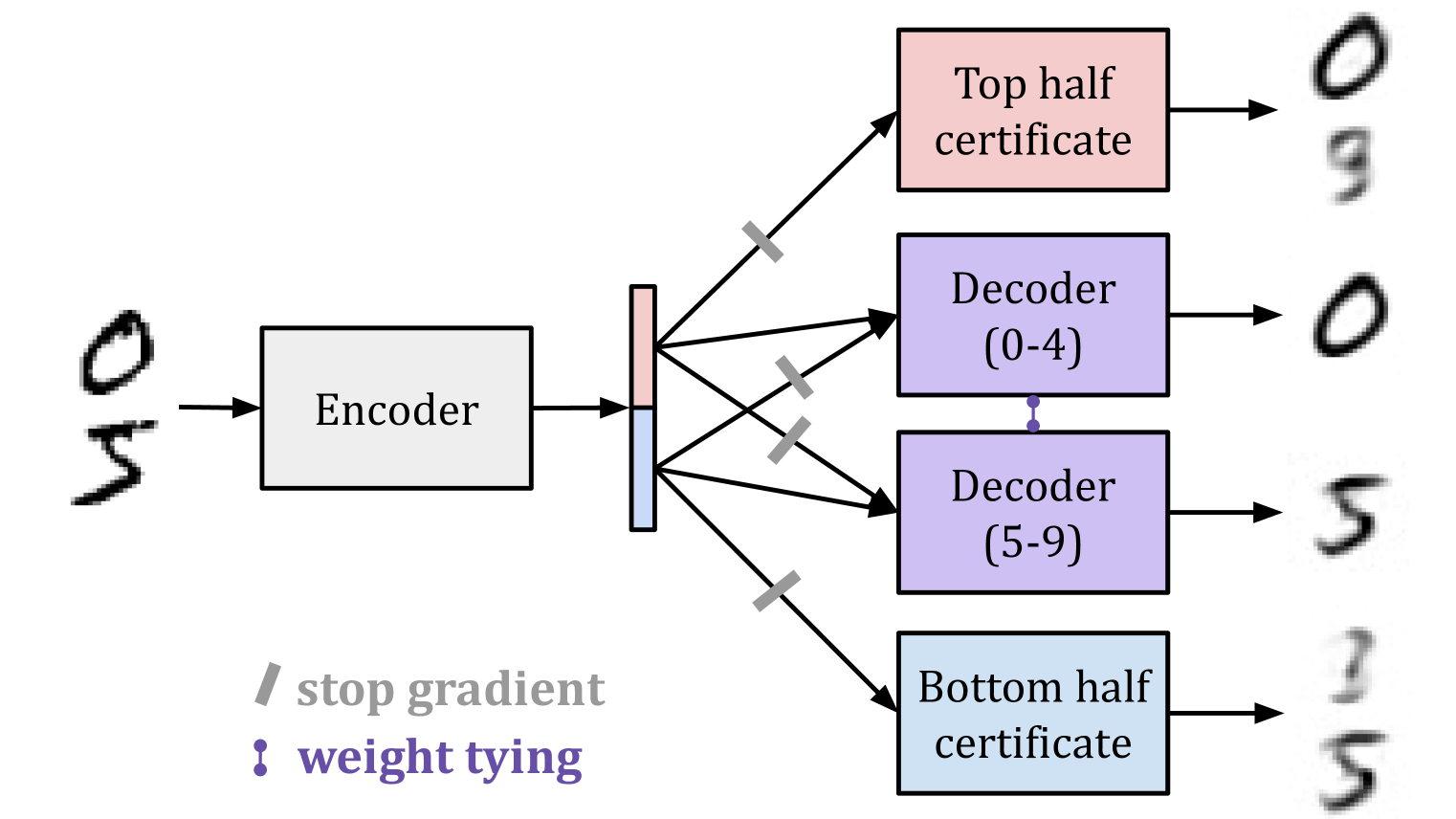
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with [...]
Outline:
(01:48) Gradient routing
(03:02) MNIST latent space splitting
(04:31) Localizing capabilities in language models
(04:36) Steering scalar
(05:46) Robust unlearning
(09:06) Unlearning virology
(10:38) Scalable oversight via localization
(15:28) Key takeaways
(15:32) Absorption
(17:04) Localization avoids Goodharting
(18:02) Key limitations
(19:47) Alignment implications
(19:51) Robust removal of harmful capabilities
(20:19) Scalable oversight
(21:36) Specialized AI
(22:52) Conclusion
The original text contained 1 footnote which was omitted from this narration.
---
First published:
December 6th, 2024
Source:
https://www.lesswrong.com/posts/nLRKKCTtwQgvozLTN/gradient-routing-masking-gradients-to-localize-computation
---
Narrated by TYPE III AUDIO.
---
Images from the article:
392 قسمت



